Engenharia de dados
AWS Kinesis
O Amazon Kinesis é um serviço gerenciado da AWS que facilita a coleta, processamento e análise de fluxos (streams) de dados em tempo real. É amplamente utilizado para monitoramento de logs, métricas, análise de dados de IoT e processamento de Big Data. O Kinesis é frequentemente comparado ao Apache Kafka, pois também é uma solução de streaming em tempo real.
Principais Características
- Processamento de grandes volumes de dados em tempo real.
- Alternativa da AWS ao Apache Kafka.
- Alta disponibilidade: Dados replicados em 3 zonas de disponibilidade (AZs) para maior resiliência.
- Integrado a ferramentas de Big Data como Apache Spark e NiFi.
- Dados organizados em shards, garantindo capacidade de processamento distribuída.
- Suporte a múltiplos consumidores simultâneos.
Os dados no Kinesis são imutáveis — uma vez gravados, não podem ser alterados ou excluídos.
Arquitetura Geral do Amazon Kinesis
- Um produtor envia um record para o Kinesis Data Stream.
- O stream distribui o record para um ou mais consumidores.
- Ordenação garantida por chaves de partição (Partition Keys). Registros com a mesma chave vão para o mesmo shard.
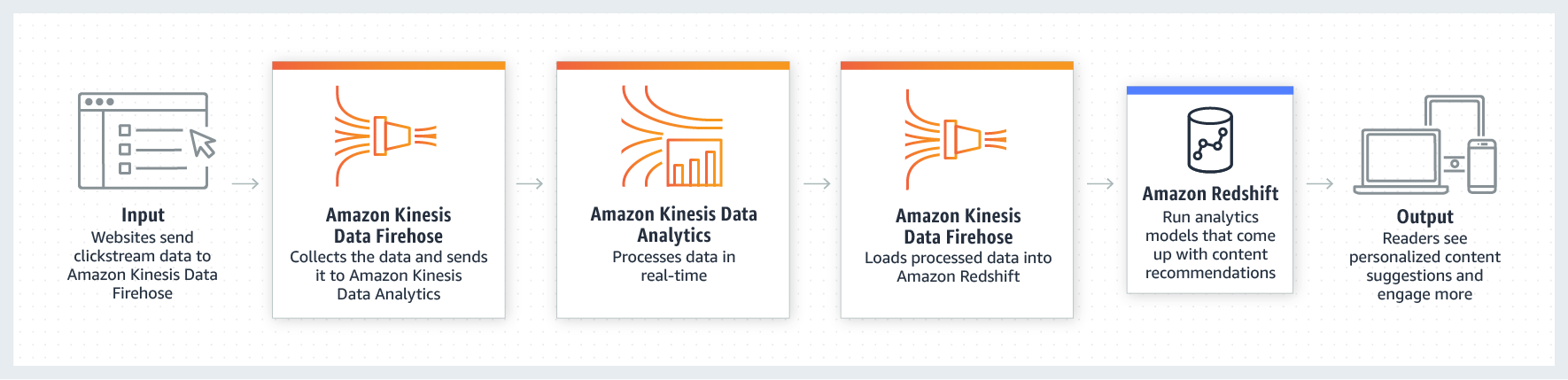
Tipos de Aplicações do Amazon Kinesis
- Kinesis Data Streams: Captura, processa e armazena fluxos de dados.
- Kinesis Data Firehose: Carrega dados para armazenamentos na AWS como S3, Redshift, OpenSearch e Splunk.
- Kinesis Data Analytics: Analisa fluxos de dados em tempo real usando SQL e Apache Flink.
- Kinesis Video Streams: Captura, processa e armazena fluxos de vídeo em tempo real.
Kinesis Data Streams
- Ideal para ingestão e processamento de grandes volumes de dados com baixa latência.
- Cobrança baseada em shards provisionados. Cada shard permite:
- Entrada: 1 MB/s ou 1.000 registros por segundo.
- Saída: 2 MB/s para múltiplos consumidores.
- Retenção de dados de 1 a 365 dias.
- Produtores:
- Lambda, Kinesis Data Firehose, Kinesis Data Analytics.
- AWS SDK e Kinesis Producer Library (KPL) — suportam compressão e batch.
- Kinesis Agent — coleta logs e envia ao Kinesis Data Streams ou Firehose.
- Consumidores:
- AWS Lambda, Kinesis Client Library (KCL) e AWS SDK.
- Suporte a leitura paralela, checkpoint e coordenação de leitura.
- Modos de Operação:
- Sob Demanda: Escala automaticamente com a carga. Pagamento por GB de I/O.
- Provisionado: Quantidade de shards definida manualmente. Pagamento por hora de shard e I/O por GB.
- Padrões de Consumo:
- Batch ou mensagem por mensagem.
Se precisar de processamento paralelo, use o Kinesis Client Library (KCL) para leitura distribuída.
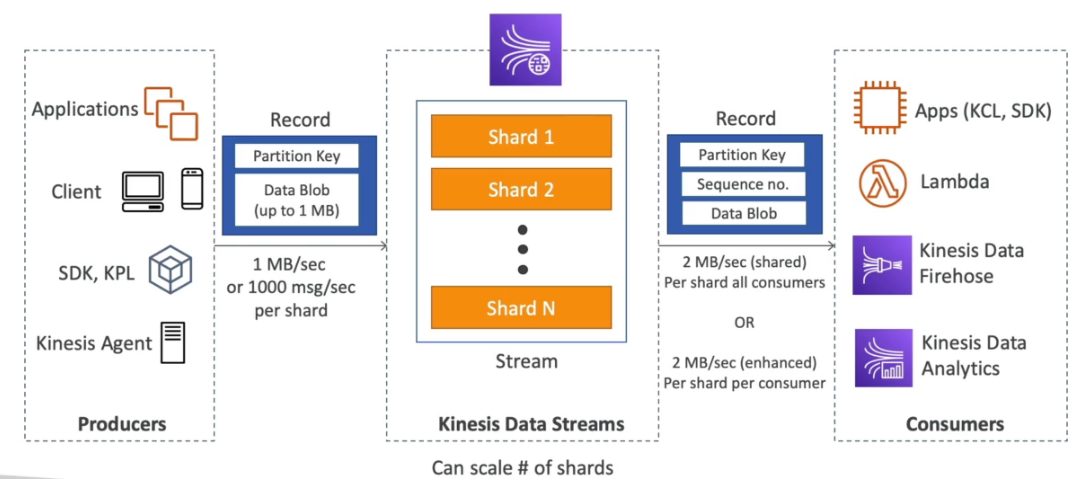
Kinesis Data Firehose
- Carrega dados para armazenamentos da AWS como S3, Redshift, OpenSearch e Splunk.
- Serviço totalmente gerenciado, com escalabilidade automática e arquitetura serverless.
- Cobrança apenas pelos dados processados.
- Funciona próximo do tempo real, pois utiliza um buffer para otimização:
- Buffer baseado em tempo ou tamanho.
- Caso seja necessário tempo real puro, utilize o AWS Lambda para pré-processamento.
Exemplo de Processo de Entrega:
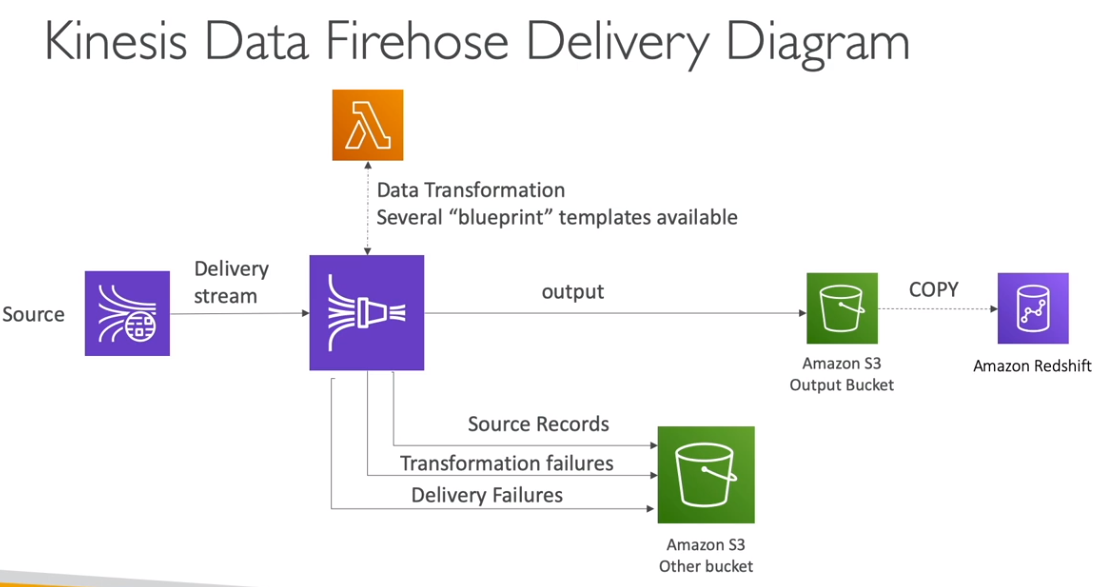
Diferença entre Data Streams e Firehose:

O Firehose não possui retenção de dados para reprocessamento, como o Kinesis Data Streams.
Kinesis Data Analytics
- Análise de fluxos de dados em tempo real com SQL e Apache Flink.
- Serviço gerenciado e altamente escalável.
- Cobrança baseada no volume de dados consumidos.
- Integração com AWS Lambda para pré-processamento dos dados.
- Permite consultas contínuas e criação de dashboards de monitoramento em tempo real.
- Uso de IAM para controlar o acesso às origens e destinos dos dados processados.
Aplicações Comuns:
- Análise de períodos de tempo.
- Monitoramento e dashboards em tempo real.
- Métricas de IoT e logs de auditoria.
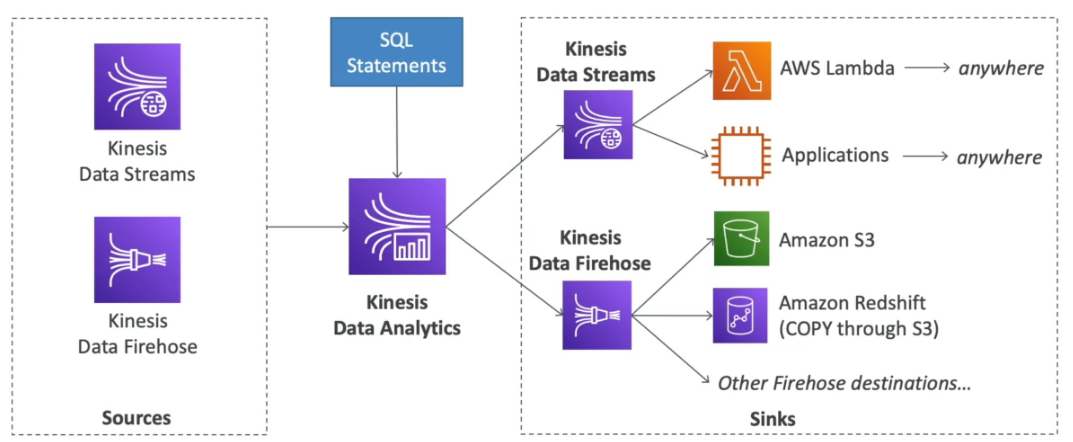
O uso de SQL simplifica a análise para usuários que não têm familiaridade com frameworks complexos como Apache Flink.
Arquiteturas de Referência com Amazon Kinesis
Pipeline de Dados em Tempo Real
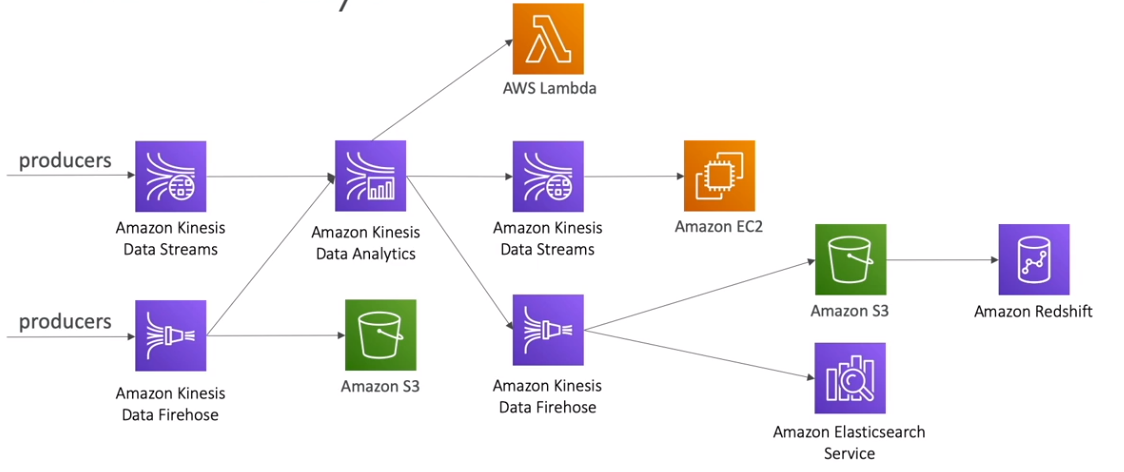
Soluções de Baixo Custo para Tempo Real

Comparação com Outras Soluções de Streaming
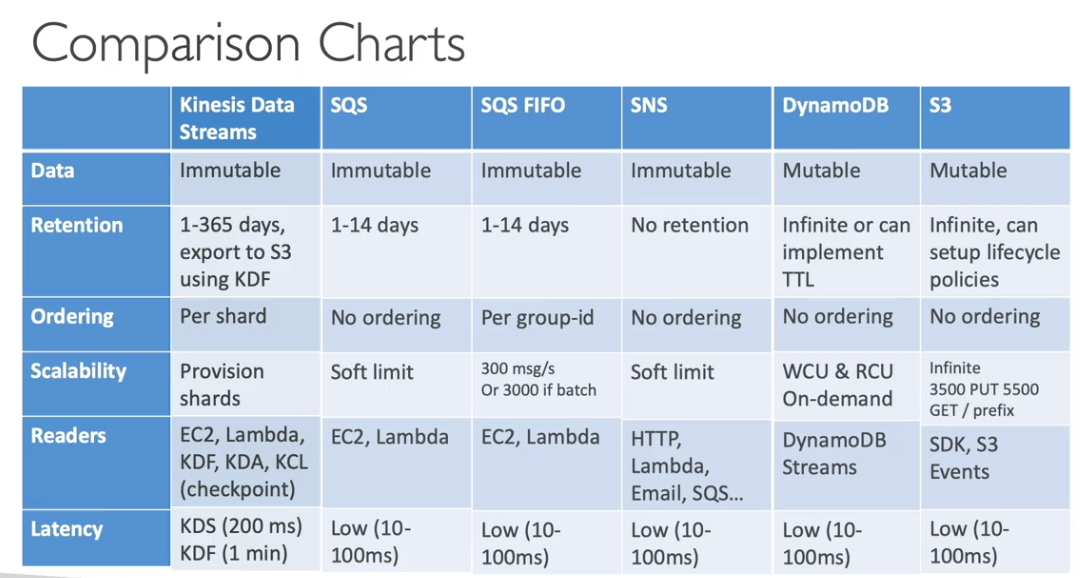
Resumo dos Limites do Kinesis Data Streams
- Limite padrão de shards: 500 shards por conta, podendo ser aumentado.
- Limite de dados de entrada: 1 MB/s por shard.
- Limite de dados de saída: 2 MB/s por shard para múltiplos consumidores.

Caso precise de maior throughput, é necessário dividir a carga entre múltiplos shards ou aumentar o número de shards provisionados.
Questões sobre o Kinesis Data Streams frequentemente abordam cenários de ingestão de dados em tempo real com alta escala, pedindo para identificar configurações corretas de shards ou modos de operação.
📌 Uma empresa deseja processar logs de acesso de milhões de usuários simultâneos em tempo real. Qual modo de operação do Kinesis Data Streams é mais adequado para garantir escalabilidade automática sem gerenciamento manual de shards?
- ✅ Modo Sob Demanda
📌 Para um aplicativo que coleta 1.500 registros por segundo, qual deve ser o número mínimo de shards provisionados para garantir a ingestão correta dos dados?
- ✅ 2 shards (Cada shard suporta até 1.000 registros/s)
Perguntas sobre Kinesis Data Firehose geralmente envolvem entrega de dados para destinos como S3, Redshift ou OpenSearch, focando em otimização de buffer e custos.
📌 Uma equipe de análise de dados deseja carregar informações em tempo quase real no Amazon S3. O volume de dados é pequeno, e a latência precisa ser mínima. O que deve ser configurado no Firehose para otimizar a entrega?
- ✅ Buffer com menor tempo possível (60 segundos) e tamanho mínimo de 1 MB.
📌 Uma empresa deseja pré-processar os dados antes de entregá-los ao Amazon Redshift. Qual recurso do Firehose deve ser utilizado?
- ✅ AWS Lambda para transformação dos dados.
Questões sobre Kinesis Data Analytics costumam testar conhecimentos sobre consultas SQL em streams de dados, integração com AWS Lambda e monitoramento de métricas.
📌 Uma startup deseja analisar em tempo real dados de sensores IoT para detecção de falhas. Qual serviço é o mais indicado para processar e analisar esses dados utilizando SQL?
- ✅ Kinesis Data Analytics
📌 Para gerar alarmes com base em eventos processados no Kinesis Data Analytics, qual serviço pode ser utilizado para integração imediata?
- ✅ AWS Lambda para resposta em tempo real.
AWS MSK
O Amazon MSK (Managed Streaming for Apache Kafka) é um serviço gerenciado da AWS baseado no Apache Kafka, que facilita a criação e execução de clusters Kafka altamente disponíveis, seguros e escaláveis na nuvem da AWS. Ele é projetado para oferecer todas as funcionalidades do Apache Kafka, mas com gerenciamento simplificado e integração nativa com outros serviços da AWS.
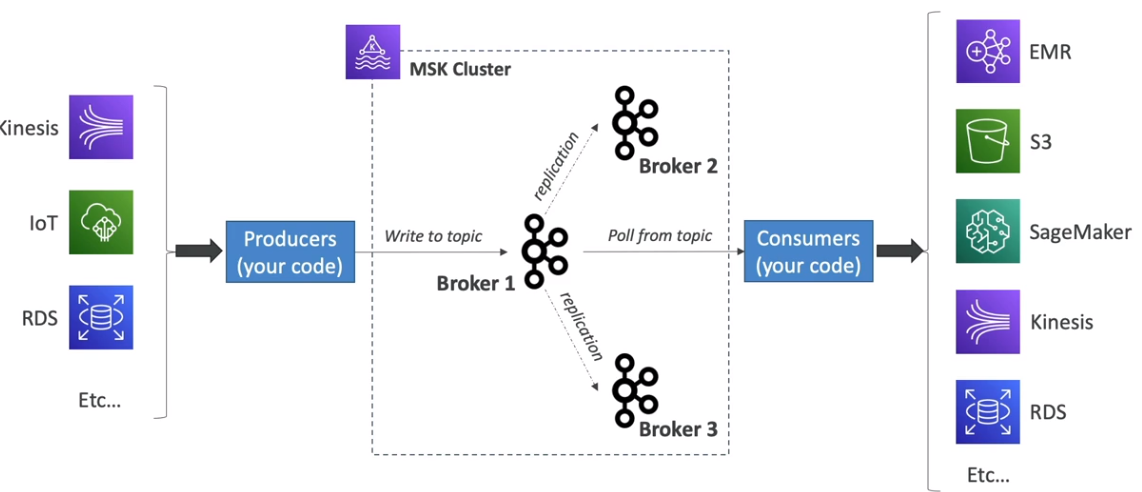
Principais Características
- Serviço gerenciado de Kafka: A AWS gerencia a infraestrutura subjacente, incluindo provisionamento, atualizações de software e manutenção de hardware.
- Alternativa ao Amazon Kinesis para processamento de dados em tempo real.
- Armazenamento persistente em EBS: Dados armazenados em volumes EBS pelo tempo que o cliente desejar, garantindo durabilidade e resiliência.
- Alta disponibilidade: Suporte a múltiplas zonas de disponibilidade (Multi-AZ) para alta disponibilidade.
- Opção de implementação Serverless, eliminando a necessidade de provisionamento manual de clusters.
- Integração nativa com serviços da AWS, facilitando a construção de pipelines de dados escaláveis e seguros.
Consumidores no Amazon MSK
Os dados armazenados nos tópicos Kafka do MSK podem ser consumidos por:
- Aplicações personalizadas que leem diretamente dos tópicos usando clientes Kafka padrão.
- Kinesis Data Analytics: Processamento avançado de streams de dados.
- AWS Glue: Transformação e integração de dados.
- AWS Lambda: Processamento de eventos em tempo real sem necessidade de infraestrutura gerenciada.
Diferenças entre MSK e Amazon Kinesis
O Amazon MSK e o Amazon Kinesis têm casos de uso semelhantes para processamento de dados em tempo real, mas diferem em arquitetura, gerenciamento e casos de uso específicos.

- MSK é indicado quando há necessidade de compatibilidade total com o ecossistema Apache Kafka ou integração com sistemas já baseados em Kafka.
- Kinesis é uma solução mais fácil de configurar e gerenciar para quem já está imerso no ecossistema AWS.
A escolha entre Amazon MSK e Amazon Kinesis depende dos requisitos específicos de integração, complexidade operacional e compatibilidade com ferramentas externas. Se sua equipe já utiliza Kafka on-premises ou precisa de compatibilidade completa com APIs do Kafka, o Amazon MSK pode ser a melhor escolha.
Questões relacionadas ao Amazon MSK frequentemente abordam comparações com o Amazon Kinesis, gerenciamento de clusters Kafka e cenários de integração com outros serviços da AWS.
📌 Uma equipe de desenvolvimento utiliza Kafka on-premises para processamento de dados em tempo real. Eles desejam migrar para a AWS mantendo a compatibilidade com seu código atual e minimizando a necessidade de mudanças significativas. Qual serviço AWS é mais adequado?
- ✅ Amazon MSK (Managed Streaming for Apache Kafka)
📌 Uma aplicação precisa processar grandes volumes de dados em tempo real com alta taxa de ingestão. A equipe deseja evitar o gerenciamento complexo de clusters Kafka e prefere uma solução serverless totalmente gerenciada. Qual serviço é recomendado?
- ✅ Amazon Kinesis Data Streams
O Amazon MSK Serverless é uma alternativa para reduzir a complexidade de provisionamento e gerenciamento de clusters Kafka, ajustando automaticamente a capacidade de acordo com a demanda.
📌 Durante um evento de marketing, o tráfego de dados no cluster Kafka aumenta de forma imprevisível. A equipe quer garantir a continuidade sem precisar redimensionar manualmente o cluster. Qual modo de operação do Amazon MSK é mais indicado?
- ✅ Amazon MSK Serverless
📌 Um cliente deseja integrar seu cluster MSK com serviços de análise de dados em tempo real da AWS. Qual ferramenta é recomendada para processar e analisar fluxos de dados diretamente do MSK?
- ✅ Kinesis Data Analytics ou AWS Lambda
AWS Batch
O AWS Batch é um serviço gerenciado da AWS que permite a execução de trabalhos em lote (batch jobs) utilizando imagens Docker. Ele simplifica o planejamento, a execução e o dimensionamento de workloads de processamento de dados sem a necessidade de gerenciar infraestrutura de cluster complexa. O pagamento é baseado apenas nos recursos utilizados, como instâncias EC2, Fargate e Spot Instances.
Principais Características
- Suporte a execução de imagens Docker para jobs em lote.
- Cobrança apenas pelos recursos computacionais utilizados.
- Integração com AWS Fargate, eliminando a necessidade de provisionar e gerenciar clusters.
- Suporte a EC2 e Spot Instances para execução na VPC.
- Possibilidade de utilizar EventBridge para agendamento de jobs.
- Integração com AWS Step Functions para orquestração de workflows complexos.
Opções de Execução no AWS Batch
- AWS Fargate: Execução serverless sem a necessidade de configurar e gerenciar instâncias ou clusters.
- Instâncias Provisionadas (EC2 e Spot): Possibilidade de maior controle sobre a infraestrutura e otimização de custos usando Spot Instances.

Casos de Uso
- Processamento de imagens em lote: Geração de miniaturas, compressão de imagens ou renderização de vídeos.
- Execução de jobs concorrentes: Processamento paralelo de grandes volumes de dados.
- Análises científicas e simulações: Modelagem matemática e simulação de cenários complexos.
Alta Performance com AWS Batch
- O AWS Batch suporta execução de multi-node parallel jobs para workloads de alta performance.
- Distribuição da carga de trabalho em várias instâncias.
- Não suporta instâncias Spot para alta performance.
- Integração com Placement Groups para otimização de baixa latência de rede e alto desempenho.
Diferença entre AWS Batch e AWS Lambda
- O AWS Batch é indicado para workloads de longa duração, uso intensivo de CPU ou memória e com necessidade de controle detalhado da infraestrutura.
- O AWS Lambda é mais adequado para tarefas curtas, baseadas em eventos e com escalabilidade automática.

Soluções de Arquitetura com AWS Batch
- Criação de Thumbnails: Automação de geração de miniaturas de imagens em massa.
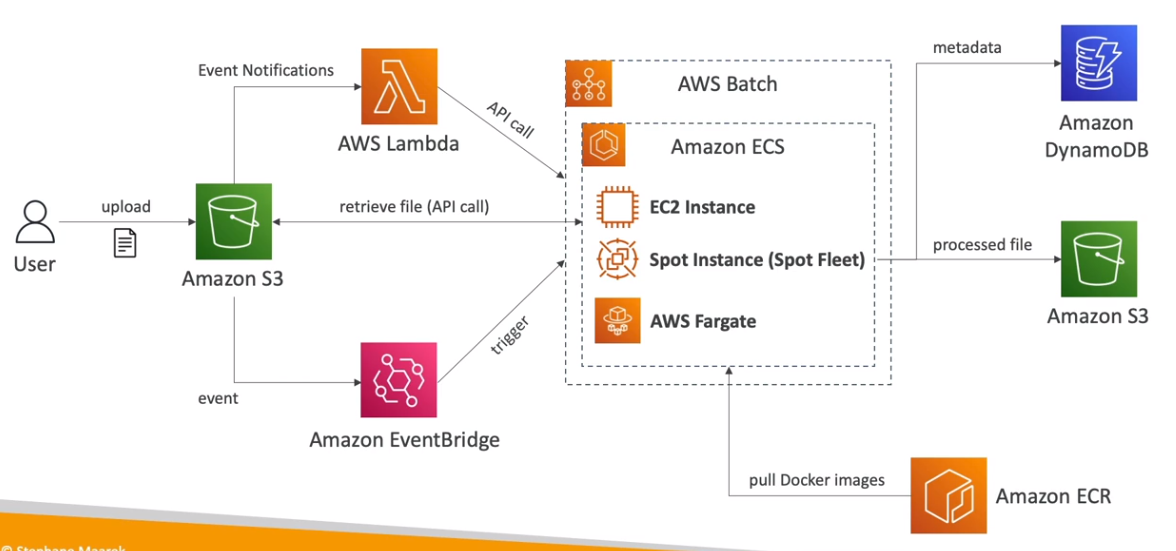
Questões sobre AWS Batch frequentemente abordam cenários de processamento em lote, escolha de tipos de instância (EC2, Fargate, Spot) e casos de uso para jobs de alta performance.
📌 Uma equipe de análise de dados precisa processar grandes volumes de dados diariamente. O processamento deve ocorrer em horários definidos e minimizar custos. Qual estratégia de execução no AWS Batch é mais indicada?
- ✅ Uso de Spot Instances para redução de custos e agendamento com EventBridge.
📌 Sua empresa precisa executar simulações complexas e altamente paralelas, exigindo várias instâncias trabalhando juntas. Qual recurso do AWS Batch atende melhor a esse cenário?
- ✅ Multi-node parallel jobs com instâncias EC2 provisionadas, garantindo comunicação entre os nós.
O AWS Batch é capaz de integrar com AWS Step Functions para orquestrar workflows complexos. Entender a integração entre esses serviços é importante para a certificação.
📌 Um fluxo de trabalho envolve várias etapas de processamento de dados, onde cada etapa depende da conclusão da anterior. Qual abordagem pode ser utilizada para orquestrar o fluxo com o AWS Batch?
- ✅ Utilizar AWS Step Functions para coordenar a execução dos jobs no Batch.
📌 Um projeto precisa de processamento rápido de pequenas tarefas acionadas por eventos e alta escalabilidade automática. O AWS Batch é adequado para esse cenário?
- ❌ Não. O uso do AWS Lambda seria mais apropriado para pequenas tarefas baseadas em eventos.
Atenção às diferenças entre AWS Batch e AWS Lambda. Questões costumam abordar quando usar cada serviço de maneira mais eficiente.
📌 Sua aplicação precisa processar milhares de imagens de forma rápida e econômica, sem se preocupar com a infraestrutura subjacente. Qual serviço utilizar?
- ✅ AWS Lambda para processamento serverless, especialmente se cada execução levar menos de 15 minutos.
AWS EMR
O Amazon EMR (Elastic MapReduce) é um serviço gerenciado da AWS para processamento de grandes volumes de dados utilizando frameworks como Apache Hadoop, Spark, HBase, Presto e Flink. Ele é amplamente utilizado em cenários de Big Data, Machine Learning e Web Indexing, sendo capaz de processar petabytes de dados de forma rápida e econômica.
Principais Características
- Criação de clusters Hadoop para análise de grandes volumes de dados.
- Capacidade de escalar automaticamente utilizando Spot Instances, reduzindo custos de processamento.
- Suporte a frameworks populares de Big Data: Apache Spark, HBase, Presto, Flink.
- Pode ser implantado em centenas de instâncias EC2 para maximizar a capacidade de processamento.
- Uso recomendado em Single AZ para maximizar a performance, evitando latência de comunicação entre zonas de disponibilidade.
- Suporte a armazenamento temporário via EBS com sistema de arquivos HDFS (Hadoop File System).
- Integração nativa com S3 (EMRFS) para armazenamento de longo prazo, garantindo persistência e durabilidade dos dados.
- Integrações adicionais com DynamoDB para consultas rápidas e armazenamento de dados estruturados.
Estrutura de Nós (Nodes) no Amazon EMR
O cluster EMR é composto por três tipos de nós:
- Master Node: Coordena o cluster, distribuindo as tarefas para os outros nós.
- Core Nodes: Executam tarefas de processamento e armazenam dados no HDFS.
- Task Nodes: Executam tarefas de processamento, mas não armazenam dados no HDFS.

Configurações de Instâncias
O Amazon EMR oferece dois modelos principais para configurar as instâncias dos nós:
1. Uniform Instance Group:
- Define um único tipo de instância para cada função do nó (Master, Core, Task).
- Opções de compra: On-Demand ou Spot Instances.
- Suporte a Auto Scaling para ajustar automaticamente a capacidade com base na demanda.
2. Instance Fleet:
- Maior flexibilidade ao permitir combinar diferentes tipos de instâncias (On-Demand e Spot).
- Permite definir um mix de instâncias para otimizar custos.
- Não possui Auto Scaling automático; a expansão do cluster deve ser gerenciada manualmente.
Armazenamento no EMR
- EBS (HDFS): Utilizado para armazenamento temporário de dados enquanto o cluster está em execução.
- S3 (EMRFS): Armazenamento de longo prazo com alta durabilidade. Ideal para persistência de dados.
- DynamoDB: Usado para consultas rápidas e armazenamento de dados não relacionais.
Caso de Uso
- Processamento de grandes volumes de dados para análises em tempo quase real.
- Treinamento de modelos de Machine Learning em larga escala.
- Indexação e análise de conteúdo da web.
- Análise de logs de servidores ou eventos de dispositivos IoT.
- AWS Glue: Pode ser integrado ao EMR para catálogos de dados e ETL (Extract, Transform, Load).
- AWS Lambda: Processamento de dados em tempo real para ingestão no cluster EMR.
- Amazon Athena: Consultas SQL sobre dados armazenados no S3 tratados pelo EMR.
- Documentação Oficial do EMR
Implantações multi-AZ podem gerar latência na comunicação entre os nós do cluster, impactando negativamente a performance.
Questões sobre Amazon EMR geralmente abordam casos de uso para processamento de Big Data, otimização de custos com Spot Instances e integrações com outros serviços AWS, como S3 e DynamoDB.
📌 Uma empresa precisa processar grandes volumes de dados utilizando Apache Spark para análise de logs. O processamento precisa ser econômico, e os dados devem ser armazenados de forma durável. Qual a configuração recomendada?
- ✅ Utilizar um cluster EMR com Spot Instances para reduzir custos e armazenar os dados no S3 via EMRFS para persistência.
O uso de Instance Fleet no EMR permite maior flexibilidade na escolha de instâncias, mas pode limitar a escalabilidade automática.
📌 Um time de cientistas de dados deseja criar um cluster EMR altamente flexível para testes exploratórios, utilizando diferentes tipos de instâncias EC2. Eles não querem depender de escalabilidade automática. Qual a abordagem correta?
- ✅ Configurar o cluster EMR com Instance Fleet para combinar instâncias On-Demand e Spot manualmente.
A escolha entre Single AZ e Multi AZ pode impactar diretamente a performance do cluster EMR.
📌 Para minimizar a latência durante o processamento de grandes volumes de dados em tempo real, qual a melhor prática para configurar a implantação do cluster EMR?
- ✅ Implantar o cluster EMR em Single AZ para evitar latência de comunicação entre zonas de disponibilidade.
O HDFS é utilizado para armazenamento temporário em clusters EMR, enquanto o S3 é recomendado para persistência de dados a longo prazo.
📌 Uma empresa deseja armazenar dados processados por um cluster EMR de forma durável e acessível por outras aplicações analíticas. Qual a melhor prática?
- ✅ Utilizar o EMRFS para salvar os dados diretamente no Amazon S3, garantindo durabilidade e acessibilidade.
O AWS Glue pode ser integrado ao EMR para catálogos de dados e tarefas de ETL.
📌 Um analista de dados precisa executar transformações complexas de ETL em um grande volume de dados antes de armazená-los no S3. Qual combinação de serviços é recomendada?
- ✅ Utilizar AWS Glue para catalogar e transformar os dados e um cluster EMR para processar grandes volumes com Apache Spark.
AWS Glue
- Serviço gerenciado de ETL (Extract, Transform, Load), que facilita a preparação e transformação de dados para análises.
- É um serviço serverless, ou seja, não há necessidade de gerenciar infraestrutura. Oferece três componentes principais:
- Componentes do AWS Glue:
- AWS Crawler: Rastreia automaticamente dados de diferentes fontes, identifica esquemas, classifica e armazena metadados no AWS Glue Data Catalog.
- AWS ETL: Núcleo do serviço ETL, que gera código Python ou Scala para realizar tarefas complexas de transformação de dados, como limpeza, enriquecimento e remoção de duplicatas.
- AWS Glue Data Catalog: Armazena metadados de forma centralizada para consulta, transformação e rastreamento de dados. Funciona como uma "biblioteca" dos dados disponíveis.
- Permite extrair dados de fontes como S3 e bancos de dados relacionais (RDBMS), transformá-los e carregá-los em serviços como Amazon Redshift.
- Possui integração com outros serviços AWS, como Athena, Redshift e EMR, para criar catálogos de dados reutilizáveis (AWS Glue Data Catalog).
- Ideal para pipelines de dados complexos, preparação para análises de Big Data e projetos de ciência de dados.
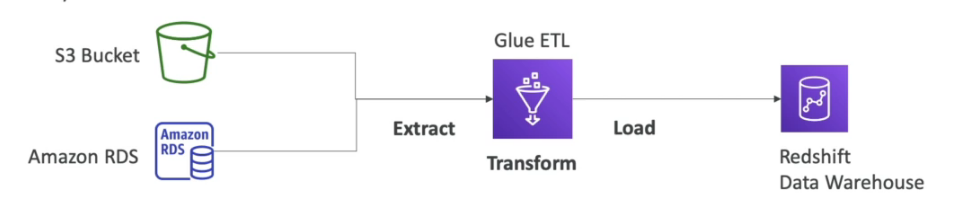
Integração com Serviços AWS:
- Athena: Consultas SQL diretamente no catálogo de dados criado no Glue.
- Redshift: Carregamento eficiente de dados transformados para análises de data warehouse.
- EMR: Integração para processamento distribuído de grandes volumes de dados.
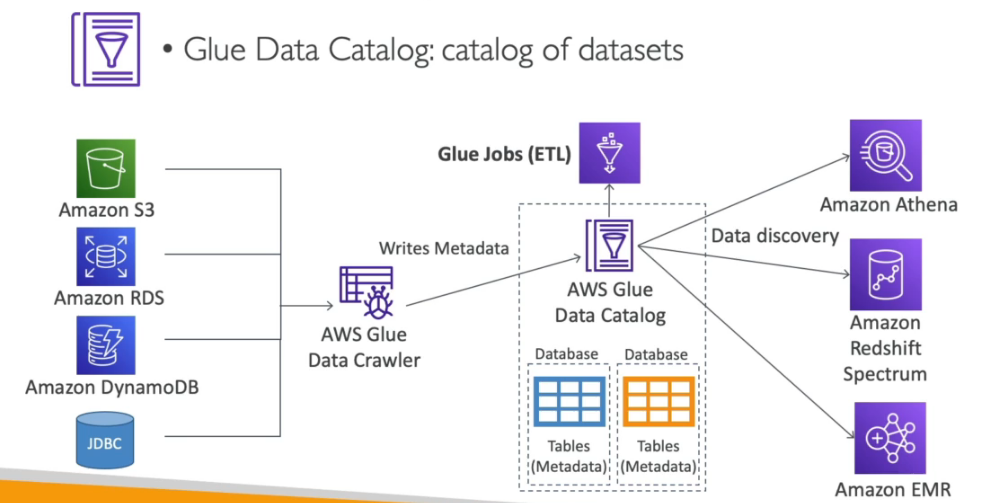
- O AWS Glue é serverless, então não há necessidade de provisionar ou gerenciar servidores.
- Utiliza o Apache Spark como mecanismo de execução para processar dados em escala.
- Pode trabalhar com Workflows para encadear e gerenciar tarefas de ETL de forma orquestrada.
- A integração com o AWS Lake Formation permite implementar controle de acesso baseado em permissões no nível do catálogo de dados.
📌 Pergunta: Uma empresa precisa transformar dados armazenados no S3 e carregá-los no Amazon Redshift para relatórios analíticos. Qual a abordagem mais recomendada?
- ✅ Configurar um AWS Glue Crawler para catalogar os dados no S3, usar um script ETL do Glue para transformação e carregar os dados no Redshift.
📌 Pergunta: Um cientista de dados deseja consultar dados diretamente do catálogo de dados do Glue sem configurar um cluster EMR. Qual serviço AWS pode ser utilizado?
- ✅ Amazon Athena, pois permite consultas SQL diretamente sobre os dados catalogados no Glue.
AWS Redshift
- Serviço de banco de dados para Data Warehouse da AWS, projetado para análises em larga escala (OLAP - Online Analytical Processing).
- Baseado no PostgreSQL, mas não é adequado para transações OLTP (Online Transaction Processing).
- Processa dados em larga escala, com desempenho até 10 vezes superior a outros sistemas OLAP, capaz de escalar para petabytes (PB) de dados.
- Utiliza armazenamento em colunas e permite execução massiva de consultas paralelas (MPP - Massively Parallel Processing) para otimizar o processamento de grandes volumes de dados.
- Modelo de pagamento baseado em instâncias provisionadas — você paga apenas pelos recursos utilizados.
- Suporta interface SQL para consultas, facilitando a integração com ferramentas de BI como AWS QuickSight ou Tableau.
Redshift Workload Management (WLM):
- Permite configurar múltiplas filas para otimizar a execução de diferentes cargas de trabalho.
- Exemplo: fila para superusuário, fila para trabalhos curtos e fila para trabalhos longos.
- Pode ser ajustado manualmente ou configurado para ajuste automático.
- Minimiza o risco de bloqueio de tarefas rápidas por execuções demoradas.
Carga de Dados e Integrações:
- Suporta carregamento de dados a partir de Amazon S3, DynamoDB, bancos de dados externos via AWS DMS (Data Migration Service) ou fluxos contínuos com Kinesis Firehose.
- Pode escalar de 1 a 128 nós, com cada nó tendo até 16 TB de espaço de armazenamento.
- Estrutura de nós:
- Nó líder: Planeja as consultas e agrega os resultados.
- Nó de computação: Executa as consultas e envia os resultados ao nó líder.

Recursos Adicionais:
- Redshift Spectrum: Permite executar consultas diretamente no S3 sem necessidade de carregar os dados para dentro do cluster Redshift.
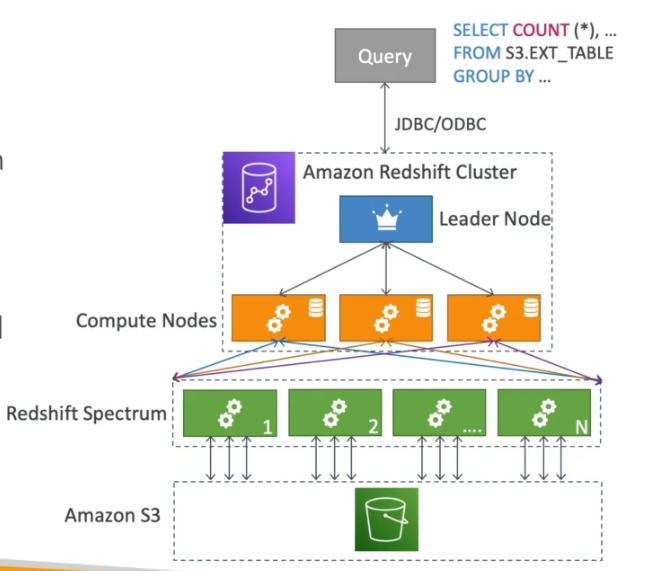
- Redshift Enhanced VPC Routing: Permite que os dados sejam copiados e carregados através da VPC, evitando tráfego de internet pública, aumentando a segurança.
- Snapshots: São realizados automaticamente a cada 8 horas, a cada 5 GB de dados modificados ou conforme agendamento manual.
- Os snapshots são armazenados no S3.
- Para restaurações de snapshots criptografados, é necessário copiar a chave KMS para o novo cluster.
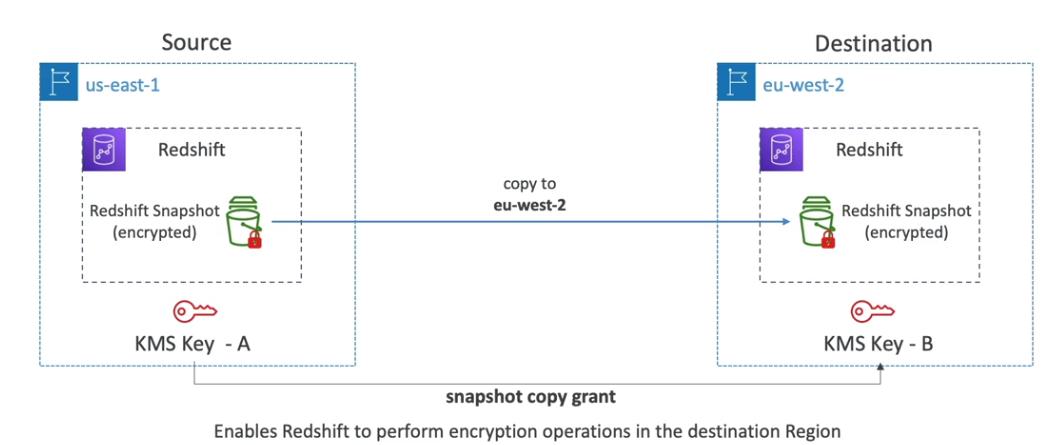
- Recuperação de Desastres:
- O Redshift não é Multi-AZ, ou seja, cada nó está em uma única AZ (Zona de Disponibilidade).
- A recuperação de desastres é feita com base em snapshots armazenados no S3.
- Para alguns tipos de cluster, há suporte limitado a múltiplos nós distribuídos entre AZs.
Cenário de Utilização:
- Ideal para cargas de trabalho analíticas de larga escala (OLAP) e não para transações rápidas (OLTP).
- Se as consultas forem esporádicas, é recomendável utilizar o Amazon Athena, que é serverless e cobra apenas pelas consultas realizadas.
Well-Architected para Redshift:
- Implementação de boas práticas para segurança, otimização de desempenho e custos.

Questões relacionadas ao Amazon Redshift frequentemente exploram otimização de performance, recuperação de desastres e integração com outros serviços da AWS.
📌 Uma empresa precisa realizar análises complexas e periódicas em um grande volume de dados armazenados no Amazon S3. Para evitar a necessidade de copiar os dados para o cluster do Redshift, qual recurso pode ser utilizado?
- ✅ Amazon Redshift Spectrum
📌 Durante a configuração do Redshift, um administrador deseja garantir que consultas curtas não fiquem presas aguardando a execução de tarefas longas. Como ele pode fazer isso?
- ✅ Configurando o Redshift Workload Management (WLM) para criar múltiplas filas de processamento.
O Redshift Enhanced VPC Routing pode ser cobrado em questões para verificar seu entendimento sobre a segurança de tráfego de dados.
📌 Uma organização deseja garantir que todo o tráfego de dados entre o Redshift e o Amazon S3 ocorra dentro da rede privada da VPC. Qual recurso deve ser ativado?
- ✅ Redshift Enhanced VPC Routing
📌 Um snapshot criptografado de um cluster Redshift precisa ser restaurado em uma conta AWS diferente. O que é necessário para garantir que a restauração seja bem-sucedida?
- ✅ Certificar-se de que a chave KMS usada na criptografia esteja compartilhada com a nova conta.
Redshift vs Athena: Certifique-se de entender as diferenças entre esses serviços, especialmente em relação a consultas esporádicas e cargas analíticas pesadas.
📌 Um analista de dados precisa consultar periodicamente pequenos conjuntos de dados no S3, mas com uma carga de trabalho imprevisível. Qual serviço é mais adequado?
- ✅ Amazon Athena, pois cobra apenas pelas consultas realizadas, sendo mais econômico para cenários esporádicos.
AWS Timestream
- Serviço de banco de dados para séries temporais (Time Series), projetado para armazenar e analisar grandes volumes de dados temporais.
- Totalmente gerenciado pela AWS, com alta escalabilidade, desempenho otimizado e arquitetura serverless (sem necessidade de gerenciamento de servidores).
- Permite armazenar e analisar trilhões de registros de dados por dia.
- 1000 vezes mais rápido e 1/10 mais barato que bancos de dados relacionais tradicionais para casos de uso específicos de séries temporais.
- Compatível com SQL, facilitando consultas analíticas complexas em dados temporais.
- Os dados recentes são armazenados em memória para consultas rápidas e, posteriormente, movidos para um armazenamento mais barato e durável.
- Oferece suporte para criação de funções analíticas de séries temporais, como cálculos de média móvel, agregações por janela de tempo e análises preditivas.
- Possui criptografia em trânsito (TLS) e em repouso (integrado ao AWS KMS).
- Casos de Uso:
- Monitoramento de dispositivos IoT.
- Análise de dados em tempo real para sistemas de monitoramento de infraestrutura, telemetria e aplicações financeiras.
- Integração com outros serviços AWS, como IoT Core, Lambda, QuickSight e Grafana, para visualização e análise de dados.
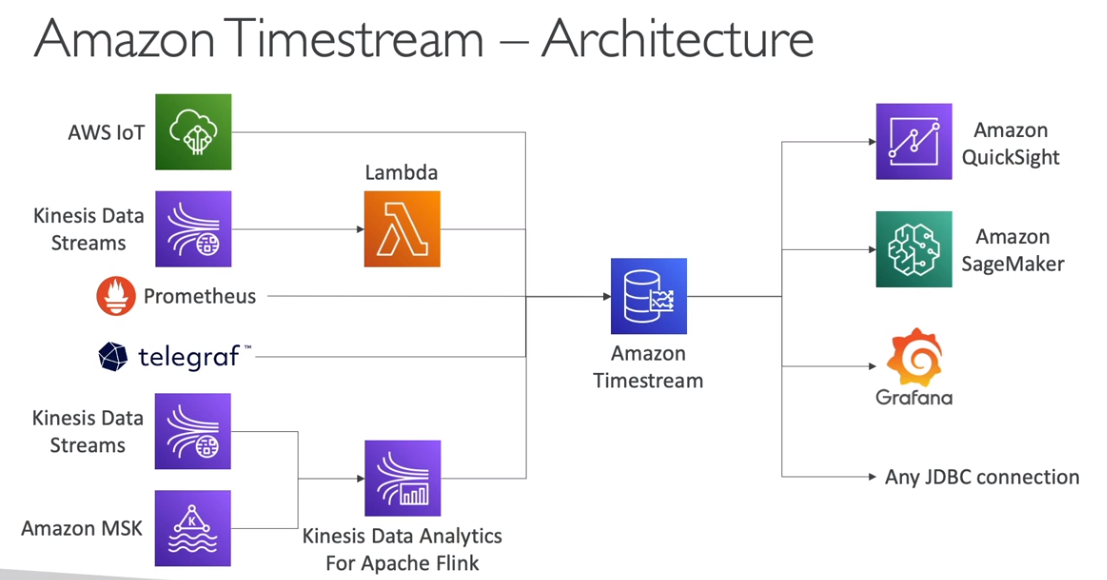
O AWS Timestream é otimizado para leitura e escrita de grandes volumes de dados temporais, sendo ideal para cenários onde a latência baixa é crucial. No entanto, não é adequado para transações complexas ou relacionamentos entre dados como um banco de dados relacional tradicional.
Documentação oficial do AWS Timestream
Questões relacionadas ao AWS Timestream geralmente abordam sua aplicação em cenários de séries temporais, integração com outros serviços da AWS e comparação de desempenho e custo com bancos de dados relacionais tradicionais.
📌 Uma empresa de monitoramento de dispositivos IoT precisa coletar dados de temperatura de milhares de sensores distribuídos globalmente. Esses dados precisam ser processados e analisados em tempo real para ajustar condições ambientais. Qual solução AWS é mais adequada para lidar com esse cenário?
- ✅ AWS Timestream, devido à capacidade de armazenar e consultar grandes volumes de dados temporais rapidamente.
O AWS Timestream armazena dados recentes em memória para consulta rápida e automaticamente migra para armazenamento mais barato à medida que envelhecem. Questões podem explorar o funcionamento dessa estrutura de armazenamento em camadas.
📌 Uma organização precisa de um banco de dados para analisar dados históricos de vendas para prever tendências futuras. O volume de dados é alto e cresce diariamente. Qual serviço da AWS é recomendado para lidar com esse volume e fornecer respostas analíticas rápidas?
- ✅ AWS Timestream, pois é otimizado para análises de séries temporais e dados históricos.
Questões podem abordar a criptografia e a segurança dos dados no AWS Timestream, considerando conformidades de segurança e uso do AWS KMS.
📌 Uma empresa está preocupada com a segurança dos dados transmitidos para o AWS Timestream e precisa garantir criptografia em trânsito e em repouso. Qual abordagem o Timestream utiliza para garantir essa segurança?
- ✅ O AWS Timestream usa criptografia em trânsito com TLS e em repouso com integração ao AWS Key Management Service (KMS).
O AWS Timestream se integra bem com outros serviços da AWS, como IoT Core, Lambda e QuickSight, para visualização e processamento em tempo real.
📌 Um time de engenharia deseja visualizar dados de sensores em tempo real com gráficos e dashboards dinâmicos. Qual a combinação de serviços AWS mais adequada para atingir esse objetivo?
- ✅ AWS Timestream para armazenamento e consulta, AWS IoT Core para ingestão de dados e AWS QuickSight para visualização.
O desempenho e a escalabilidade do AWS Timestream são frequentemente comparados com bancos de dados relacionais tradicionais em questões de prova.
📌 Um analista precisa armazenar e consultar dados de séries temporais com alta frequência de escrita e leitura. Por que o AWS Timestream seria preferido a um banco de dados relacional tradicional?
- ✅ Porque o AWS Timestream é até 1000 vezes mais rápido e até 10 vezes mais barato para esse tipo de cenário.
AWS Athena
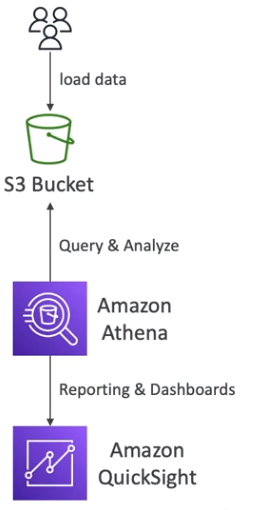
Serviço de consulta Serverless que permite realizar análises diretamente em arquivos armazenados no Amazon S3 utilizando SQL. Ideal para consultas ad hoc, análises rápidas e integração com ferramentas de BI como AWS QuickSight.
Características principais:
- Serverless: Não requer provisionamento de infraestrutura ou gerenciamento de servidores.
- Linguagem SQL: Realiza consultas nos dados diretamente no S3.
- Conectores JDBC e ODBC: Possibilitam a conexão com ferramentas de BI e análise de dados.
- Suporta múltiplos formatos de dados: CSV, JSON, ORC, Avro, Parquet.
- Cobrança baseada em uso:
- $5 por TB de dados escaneados.
- Quanto mais eficiente a consulta (menos dados escaneados), menor o custo.
- Uso comum: BI, Analytics, relatórios, análise de VPC Flow Logs, ELB Logs e análise complexa com junções e funções de janela.
- Baseado em Presto:
- O Athena usa o mecanismo de consulta distribuído Presto, com suporte completo ao SQL padrão.
- Mais informações: Presto na AWS.
Integração com outros serviços:
- AWS QuickSight: Para visualização de dados e criação de dashboards interativos.
- Queries federadas: Permitem consultar dados em outras fontes além do S3 (RDS, DynamoDB, Redshift), utilizando funções Lambda para integração.
- Armazenamento de resultados no S3: O resultado das queries pode ser armazenado diretamente no S3 para análises futuras.
- Possibilidade de se conectar a bancos de dados relacionais e NoSQL usando a Lambda como conector.
Well-Architected:
- O Athena segue as práticas recomendadas do Well-Architected Framework da AWS para eficiência de custo, performance e segurança.

Melhorando a performance:
- Particione os dados no S3 para limitar a quantidade de dados escaneados.
- Converta os dados para formatos colunarizados como Parquet ou ORC para melhorar a eficiência de leitura.
- Utilize compressão para reduzir o volume de dados e, consequentemente, o custo das queries.
- Considere otimizar as consultas para evitar full scans desnecessários.

- Quando realizar queries ad hoc, utilize filtros de data ou partições para evitar a varredura de todo o dataset.
- Avalie a aplicação de AWS Glue Data Catalog para catalogar e organizar os metadados dos dados armazenados no S3, facilitando a consulta.
- Para alta disponibilidade e consistência dos dados, sempre utilize buckets S3 configurados adequadamente, com versionamento habilitado.
Questões sobre o AWS Athena frequentemente pedem para identificar cenários de uso adequado, integração com outras ferramentas de BI e otimização de custos.
📌 Uma empresa deseja realizar análises ad hoc de grandes volumes de dados armazenados no Amazon S3, sem precisar gerenciar servidores. Qual serviço da AWS é mais indicado?
- ✅ AWS Athena
📌 Um time de dados está enfrentando custos elevados nas consultas do Athena devido à varredura de grandes volumes de dados. Quais práticas podem ser adotadas para reduzir os custos?
- ✅ Particionar os dados no S3 e utilizar formatos colunarizados como Parquet ou ORC.
Questões também podem abordar integrações do Athena com outros serviços da AWS, como AWS Glue para catalogação de dados.
📌 Como o AWS Glue pode ser utilizado para otimizar as consultas do AWS Athena?
- ✅ Catalogando os dados no AWS Glue Data Catalog, facilitando a organização e otimização das queries.
📌 Qual é o mecanismo de consulta subjacente ao Athena, conhecido por sua alta performance em análise distribuída de grandes volumes de dados?
- ✅ Presto, com suporte completo ao SQL padrão.
AWS QuickSight
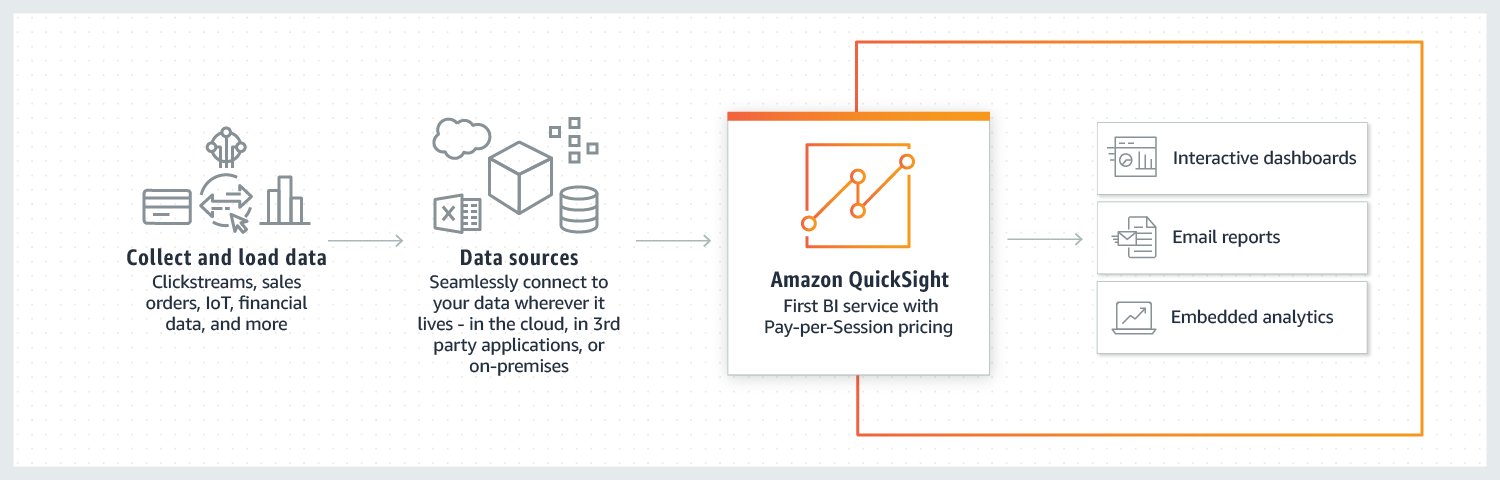
Visão Geral:
O AWS QuickSight é um serviço de inteligência comercial (BI) totalmente gerenciado, escalável e alimentado por machine learning. Ele permite criar e compartilhar painéis interativos e insights visuais rapidamente, sendo ideal para análise de dados baseada na nuvem.
Características Principais:
- Serviço de BI serverless, escalável e incorporável.
- Utiliza Machine Learning para criar insights automáticos.
- Modelo de pagamento: "Pay-per-session" — você paga apenas pelas sessões ativas de uso.
- Controle de acesso via usuários ou grupos, que podem ser gerenciados fora do IAM, facilitando a administração.
- Baseado no mecanismo de cálculos paralelos em memória chamado SPICE (Super-fast, Parallel, In-memory Calculation Engine), otimizando consultas e melhorando o desempenho.
- Oferece Column-Level Security (CLS) — controle de acesso a nível de coluna para restringir visualização de dados sensíveis.
Conexões e Fontes de Dados:
O QuickSight pode se conectar a diversas fontes de dados, incluindo:
- Bancos de dados gerenciados da AWS como Aurora e RDS.
- Serviços analíticos como Athena e S3.
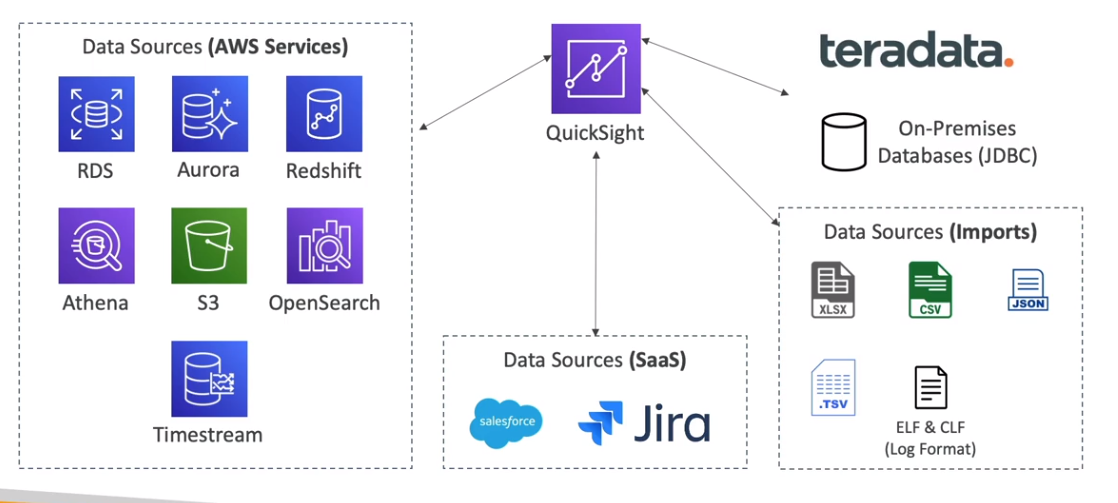
Vantagens e Casos de Uso:
- Criação rápida de dashboards interativos para visualização de dados.
- Análises avançadas com o uso de machine learning para detectar anomalias e prever tendências.
- Uso compartilhado para equipes internas ou clientes externos com autenticação segura e acesso controlado.
- Análise integrada com outras ferramentas de dados da AWS, como Athena e Redshift.
- O uso do CLS (Column-Level Security) é essencial para proteger dados sensíveis e garantir conformidade com regulamentações.
- O gerenciamento de usuários e permissões fora do IAM pode simplificar o acesso para grandes equipes de análise ou clientes externos.
- O SPICE permite a manipulação de grandes volumes de dados com alta performance, sendo uma alternativa eficiente para queries pesadas.
Well-Architected
Ao integrar o QuickSight em uma arquitetura bem planejada, considere:
- Utilizar o AWS Glue Data Catalog para organização de dados.
- Aplicar boas práticas de segurança no armazenamento dos dados no S3.
- Monitorar e controlar os custos do modelo Pay-per-session, especialmente em equipes grandes.
Questões sobre o AWS QuickSight geralmente envolvem integração com fontes de dados AWS, estratégias de segurança como o Column-Level Security (CLS) e otimização de custos no modelo Pay-per-session.
📌 Uma equipe de análise deseja criar painéis interativos no QuickSight usando dados armazenados no Amazon Athena e S3, sem precisar configurar um servidor. Qual característica do QuickSight torna isso possível?
- ✅ O QuickSight é um serviço serverless com suporte a múltiplas fontes de dados da AWS.
📌 Um cliente deseja garantir que apenas membros específicos da equipe possam visualizar colunas sensíveis em um painel do QuickSight. Qual recurso deve ser configurado?
- ✅ Column-Level Security (CLS) para controle de acesso a nível de coluna.
O modelo de precificação do QuickSight pode gerar custos inesperados se não gerenciado corretamente, especialmente para equipes grandes ou acessos externos.
📌 Uma organização deseja fornecer acesso esporádico a relatórios de BI para uma equipe de 200 pessoas. Qual estratégia de precificação seria mais econômica no QuickSight?
- ✅ Utilizar o modelo Pay-per-session, pagando apenas pelos acessos efetivos.
📌 Um analista precisa integrar o QuickSight a dados armazenados no Amazon Aurora para criar painéis interativos. Quais permissões devem ser concedidas para essa integração?
- ✅ Permissão no IAM para leitura dos dados no Amazon Aurora e acesso ao QuickSight.
Executando Jobs na AWS
- A AWS oferece diversas soluções para execução de jobs, variando de acordo com a demanda e o nível de gerenciamento necessário. A escolha correta depende de fatores como tempo de execução, escalabilidade e complexidade de implementação.
Exemplos de soluções para execução de jobs:
-
EC2 (Amazon Elastic Compute Cloud)
- Ideal para longas execuções, mas requer gerenciamento de infraestrutura.
- Não escala automaticamente de forma nativa; precisa de configurações adicionais com Auto Scaling.
-
AWS Lambda
- Escalável e gerenciado, porém limitado a um tempo máximo de execução de 15 minutos.
- Bom para tarefas curtas e baseadas em eventos, como ETL em tempo real.
-
AWS Step Functions
- Orquestração de workflows serverless com AWS Lambda.
- Reage a eventos complexos, mas herda a limitação de tempo do Lambda.
-
AWS Batch
- Ideal para jobs longos, processando em larga escala.
- Suporte para workloads com grande volume de dados; complexidade maior para configurar.
-
AWS Fargate
- Executa contêineres sem necessidade de gerenciamento de infraestrutura.
- Bom para jobs longos e workloads event-driven.
-
EMR (Elastic MapReduce)
- Usado para grandes volumes de dados no estilo Big Data.
- Baseado no Hadoop e Apache Spark, sendo mais complexo e custoso.
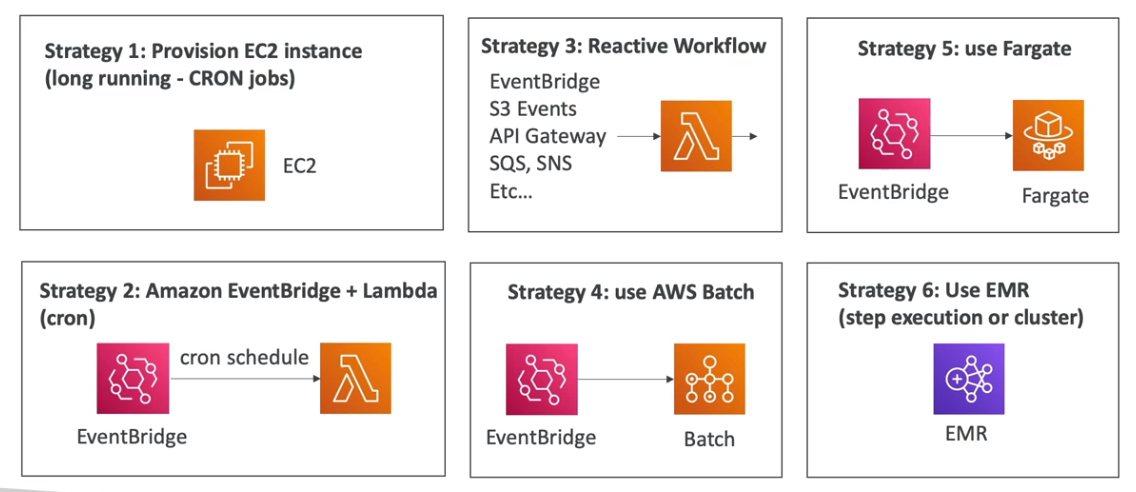
Para workloads de Big Data, o AWS EMR é recomendado, enquanto jobs event-driven e curtos são mais adequados para o AWS Lambda.
Pipelines para trabalhar com dados
A AWS oferece diversas ferramentas e abordagens para pipelines de dados. A escolha depende do caso de uso, seja análise de dados, ingestão de grandes volumes ou comparação de tecnologias.
Análise de dados: Identificar tendências e insights com rapidez.
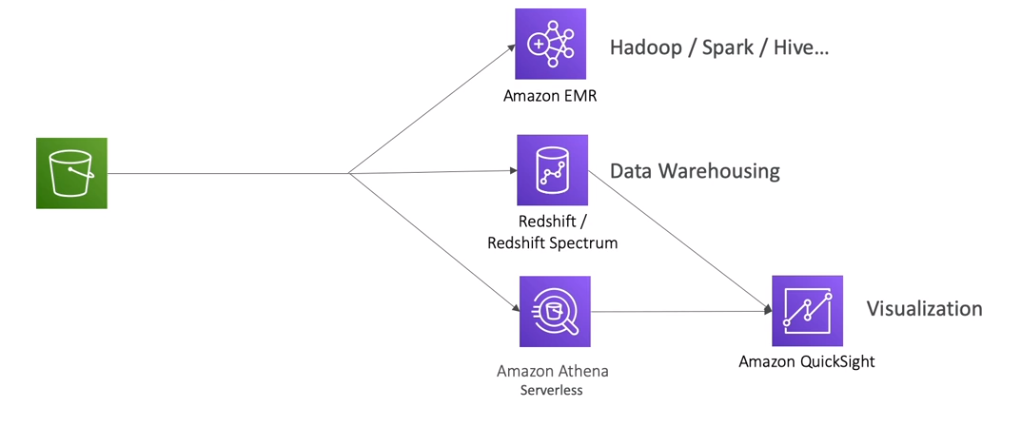
Ingestão de dados Big Data: Processar grandes volumes de dados de maneira escalável.
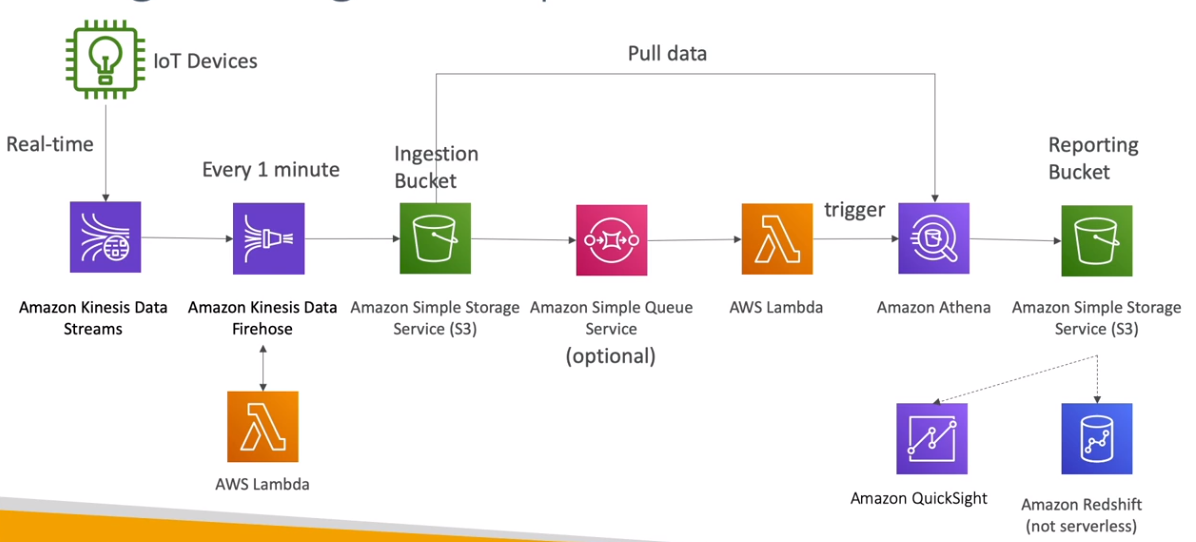
Comparação de tecnologias: Identificar a melhor abordagem com base nos requisitos do projeto.

Explicações Adicionais
- AWS Glue: Serviço de ETL serverless, recomendado para processar e mover dados entre serviços AWS.
- Amazon Kinesis: Excelente para ingestão de dados em tempo real.
- AWS Data Pipeline: Permite orquestrar e automatizar a movimentação de dados e processos periódicos.
- Amazon Redshift: Análise de dados estruturados em grande escala.
É fundamental entender os casos de uso ideais de cada ferramenta para escolher a melhor opção em uma arquitetura de Big Data.