Bem vindo
Bem vindo a minha pagina de anotações, aqui com minhas unilises (erros de português) deixo minhas observações sobre os temas que estudo.
Paginas:
Bem vindo a minha pagina de anotações, aqui com minhas unilises (erros de português) deixo minhas observações sobre os temas que estudo.
Paginas:
Em construção
Paginas:
Em construção
Paginas:
# hack para terminal
sudo apt install fonts-hack-ttf -y
# Fira code
sudo apt install fonts-firacode cat /etc/apt/sources.confls /var/cache/apt/archivesls /var/lib/apt/listsapt-get option nome_do_pacoteOptions:
apt-cache search pacote
apt-cache depends pacoteO pré-carregamento é um daemon que é executado em segundo plano e analisa o comportamento do usuário e executa aplicativos com freqüência. Abra um terminal e use o seguinte comando para instalar o pré-carregamento
sudo apt-get install preloadlink: https://wiki.archlinux.org/index.php/Installation_guide
Inicie o archlinux e:
loadkeys br-abnt2ip link
ping google.com.brwifi-menuAbre um diálogo simples de escaneamento de rede, permitindo que você selecione com o teclado a rede desejada, digite a senha e pronto.
Use o comando para iniciar o particionamento do disco
# Para listar as partições existentes
lsblk
fdisk -l
# Para cira novas partições GPT, para a partição /dev/sda
cfdisk /dev/sda| Partição | Tipo de partirção | Sugestão de tamanho | Ponto de montagem |
|---|---|---|---|
| /dev/efi_system_partition | EFI system partition | 500MB | /mnt/boot |
| /dev/swap_partition | Linux swap | 2G | [SWAP] |
| /dev/root_partition | Linux x86-64 root (/) | O resto | /mnt |

#mkfs.fat -F32 /dev/boot_partition
mkfs.fat -F32 /dev/sda1# mkswap /dev/swap_partition
mkswap /dev/sda2# mkfs.ext4 /dev/root_partition
mkfs.ext4
mount /dev/sda3 /mnt# mount /dev/root_partition/mnt
mount /dev/sda3 /mnt
mkdir /mnt/home
mkdir /mnt/boot
mkdir /mnt/boot/efi# mount /dev/boot_partition/mnt
mount /dev/sda1 /mnt/boot/efi# swapon /dev/swap_partition
swapon /dev/sda2pacstrap /mnt base linux linux-firmwareIsso pode demorar um tempinho, vá tomar um chá
Vamos gerar a nossa tabela FSTAB, que vai dizer para o sistema onde estão montadas cada uma das partições, faremos isso usando este comando:
# Cria a tabela do fstab
genfstab -U -p /mnt >> /mnt/etc/fstab
# mostra o conteudo da tabela fstab
cat /mnt/etc/fstabEsse “-U” ali “no meio da turma” é para que seja usados os IDs dos discos no FSTAB, ao invés dos rótulos
arch-chroot /mntUma vez logado no seu sistema (repare que o terminal mudou de aparência), tudo o que você fizer agora, ficará em definitivo no seu Arch Linux.
Para alterar ajustar o fuso horario precisamos criar um link simbolivo
# ln -sf /usr/share/zoneinfo/Região/Cidade /etc/localtime
Ex:
ln -sf /usr/share/zoneinfo/America/Sao_Paulo /etc/localtimehwclock --systohcdatepacman -S nanoPara alterar para português
nano /etc/locale.genlocale-genecho LANG=pt_BR.UTF-8 >> /etc/locale.confecho KEYMAP=br-abnt2 >> /etc/vconsole.conf# coloquei uni_arch
nano /etc/hostnamePorem vc deve adicionalos na tabela hosts
nano /etc/hosts
# ADD
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
127.0.1.1 uni_arch.localdomain uni_archpasswdsenha: unisenha
# useradd -m -g users -G wheel nome_desejado_para_o_usuario
useradd -m -g users -G wheel uni_user# pacman -S dosfstools os-prober mtools network-manager-applet networkmanager wpa_supplicant wireless_tools dialog sudo
# na vm
pacman -S dosfstools os-prober mtools systemd-networkd, systemd-resolved iwd sudonano /etc/sudoersuni_user ALL=(ALL) ALLpacman -S grub-efi-x86_64 efibootmgr
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=arch_grub --recheck
cp /usr/share/locale/en@quot/LC_MESSAGES/grub.mo /boot/grub/locale/en.mogrub-mkconfig -o /boot/grub/grub.cfgChegamos ao final da instalação padrão, digite “exit” ou pressione “Ctrl+D” e use o comando “reboot” para reiniciar o computador, remova o pen drive da máquina.
pacman -Sy
pacman -S xorg-serverpacman -S virtualbox-guest-utils virtualbox-guest-modules-arch mesa mesa-libglpacman -S gnome gnome-terminal nautilus gnome-tweaks gnome-control-center gnome-backgrounds adwaita-icon-theme
pacman -S firefox
systemctl enable gdmEm construção
Paginas:
Em construção
Caso no windows crie via interface.
mkdir -p C:\opt\jetty
mkdir -p C:\opt\nexus-app
mkdir -p C:\opt\tempDescrição
Os propósitos do diretório são os seguintes:
C:\opt\jetty - Onde a distribuição do cais será descompactada
C:\opt\nexus-app - Onde seu conjunto específico de aplicativos da web estará localizado, incluindo toda a configuração necessária do servidor para torná-los operacionais.
C:\opt\temp - Este é o diretório temporário designado a Java pela Camada de Serviço (é o que Java vê como java.io.tmpdir Propriedade do Sistema).
Isso é intencionalmente mantido separado do diretório temporário padrão de /tmp, pois esse local também funciona como o diretório de trabalho Servlet Spec. É nossa experiência que o diretório temporário padrão é frequentemente gerenciado por vários scripts de limpeza que causam estragos em um servidor Jetty de longa execução.
JETTY_HOME=C:\opt\jetty
JETTY_BASE=C:\opt\nexus-app
TMPDIR=C:\opt\tempEdite o arquivo
%JETTY_HOME%\etc\webdefault.xml, procure pordirAllowede mudar parafalse<init-param> <param-name>dirAllowed</param-name> <param-value>false</param-value> </init-param>
Após configurar as variáveis de ambiente, use os comandos abaixo para criar o base dir:
cd %JETTY_BASE%
java -jar %JETTY_HOME%\start.jar --create-startd
java -jar %JETTY_HOME%\start.jar --add-to-start=http,deploy,jsp,console-capture # Caso sem https
java -jar %JETTY_HOME%\start.jar --add-to-start=https,ssl,deploy,jsp,console-capture # Caso https - Item https
Descrição dos arquivos criados
console-capture.ini - Onde fica as configurações de log. deploy.ini - Configurações dos path e arquivos do deploys. http.ini - Configuração do http (porta, host …)
https.ini - Configuração do http (porta, host …)
ssl.ini - Configuração de certificados
Crie um arquivo start.ini (caso não exista), para adicionar configurações personalizadas na inicialização do jetty, como debug, plugin do apm-server ….
touch %JETTY_BASE%\start.d\start.ini # touch serve pra criar arquivo, você pode criar na mãoCausa problema no banco, porque a maquina está em uma timezone diferente.
Edite o arquivo %JETTY_BASE%\start.ini e adicione:
Abra no editor de texto o arquivo
%JETTY_BASE%\start.ini
# Adiciona e as configurações ao final do arquivo
--exec
-Doracle.jdbc.timezoneAsRegion=false # Serve para descosiderarEdite o arquivo %JETTY_BASE%\start.d\console-capture.ini e deixe:
## Para que cada novo log anexe ao arquivo existente
jetty.console-capture.append=true
## Quantos dias para reter arquivos de log antigos
jetty.console-capture.retainDays=30Edite o arquivo %JETTY_BASE%\start.d\http.ini e defina em qual porta o jetty vai rodar.
jetty.http.port=8080Caso não tenha executado o item de https no passo 4: Use o comando abaixo para adicionar o modulo ssl e https no jetty:
java -jar %JETTY_HOME%\start.jar --add-to-start=https,ssl,deploy,jsp,console-captureNecessário pra segurança.
A senha deve ser a senha do certificado e do keystore. (veremos isso mais pra frente)
cd %JETTY_HOME%\lib
java -cp jetty-util-<versao>.jar org.eclipse.jetty.util.security.Password suaSenhaSuperSecretaOBF:20ld1i9a1ysy1ri71x8c1bim1bhs1x8i1ri71yto1i6o20l9
MD5:f6440512900830666d40fbe12b88adafEsta é a nossa senha de exemplo: suaSenhaSuperSecreta. Sua representação ofuscada é OBF:20ld1i9a1ysy1ri71x8c1bim1bhs1x8i1ri71yto1i6o20l9.
Esse procedimento considera que você já tenha um certificado, do tipo pfx, caso seja diferente busque como criar um keystore do tipo JKS com o tipo do seu certificado.
Caso use linux use o comando abaixo:
keytool -importkeystore -srckeystore Wildkns.pfx -srcstoretype pkcs12 -destkeystore keystore -deststoretype JKSCaso use windows us os passos abaixo:
Use o aplicativo key explore
Abra ele como administrador, e crie um certificado vazio.









# Entre na pasta onde salvou o keystore
cp keystore %JETTY_BASE%\etcAdicione as linhas abaixo no arquivo
%JETTY_BASE%\start.d\ssl.ini
## Porta da https
jetty.ssl.port=8443
## Keystore password
jetty.sslContext.keyStorePassword=OBF:20ld1i9a1ysy1ri71x8c1bim1bhs1x8i1ri71yto1i6o20l9 # senha gerada anteriormente - passo 6.2
## KeyManager password
jetty.sslContext.keyManagerPassword=OBF:20ld1i9a1ysy1ri71x8c1bim1bhs1x8i1ri71yto1i6o20l9 # senha gerada anteriormente - passo 6.2
## Truststore password
jetty.sslContext.trustStorePassword=OBF:20ld1i9a1ysy1ri71x8c1bim1bhs1x8i1ri71yto1i6o20l9 # senha gerada anteriormente - passo 6.2https://localhost:8443 # vai falar que esta inseguro
https://<url do dominio>:8443 # vai falar que esta seguroPara ver os logs da aplicação
# abra a powershell
# entre na pasta %JETTY_BASE%\webapps
# digite o comando:
Get-Content nome_arquivo_log -Wait -Tail 100
# ou digite o comando com o caminho
# ex:
Get-Content c:\opt\nexus-app\logs\2020-11-02.log -Wait -Tail 100Para ver os logs do serviço do Windows
# abra a powershell
# entre na pasta c:/opt/logs
# digite o comando:
Get-Content nome_arquivo_log -Wait -Tail 100
# ou digite o comando com o caminho
# ex:
Get-Content c:\opt\logs\2020-11-02.log -Wait -Tail 100Caso queria redirecionar o que recebe em uma url crie um arquivo xml junto as aplicações
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd">
<Configure class="org.eclipse.jetty.webapp.WebAppContext">
<Set name="contextPath">/</Set>
<Set name="war">/opt/jetty/webapps/<app>.war</Set>
</Configure>
@echo off
set SERVICE_NAME=JettyService
set JETTY_HOME=C:\opt\jetty
set JETTY_BASE=C:\opt\nexus-app
set STOPKEY=secret
set STOPPORT=50001
set PR_INSTALL=C:\opt\prunsrv.exe
@REM Service Log Configuration
set PR_LOGPREFIX=%SERVICE_NAME%
set PR_LOGPATH=C:\opt\logs
set PR_STDOUTPUT=auto
set PR_STDERROR=auto
set PR_LOGLEVEL=Debug
@REM Path to Java Installation
set JAVA_HOME=C:\Program Files\Java\jdk1.7.0_45
set PR_JVM=%JAVA_HOME%\jre\bin\server\jvm.dll
set PR_CLASSPATH=%JETTY_HOME%\start.jar;%JAVA_HOME%\lib\tools.jar
@REM JVM Configuration
set PR_JVMMS=128
set PR_JVMMX=512
set PR_JVMSS=4000
set PR_JVMOPTIONS=-Duser.dir="%JETTY_BASE%";-Djava.io.tmpdir="C:\opt\temp";-Djetty.home="%JETTY_HOME%";-Djetty.base="%JETTY_BASE%"
@REM Startup Configuration
set JETTY_START_CLASS=org.eclipse.jetty.start.Main
set PR_STARTUP=auto
set PR_STARTMODE=java
set PR_STARTCLASS=%JETTY_START_CLASS%
set PR_STARTPARAMS=STOP.KEY="%STOPKEY%";STOP.PORT=%STOPPORT%
@REM Shutdown Configuration
set PR_STOPMODE=java
set PR_STOPCLASS=%JETTY_START_CLASS%
set PR_STOPPARAMS=--stop;STOP.KEY="%STOPKEY%";STOP.PORT=%STOPPORT%;STOP.WAIT=10
"%PR_INSTALL%" //IS/%SERVICE_NAME% ^
--DisplayName="%SERVICE_NAME%" ^
--Install="%PR_INSTALL%" ^
--Startup="%PR_STARTUP%" ^
--LogPath="%PR_LOGPATH%" ^
--LogPrefix="%PR_LOGPREFIX%" ^
--LogLevel="%PR_LOGLEVEL%" ^
--StdOutput="%PR_STDOUTPUT%" ^
--StdError="%PR_STDERROR%" ^
--JavaHome="%JAVA_HOME%" ^
--Jvm="%PR_JVM%" ^
--JvmMs="%PR_JVMMS%" ^
--JvmMx="%PR_JVMMX%" ^
--JvmSs="%PR_JVMSS%" ^
--JvmOptions=%PR_JVMOPTIONS% ^
--Classpath="%PR_CLASSPATH%" ^
--StartMode="%PR_STARTMODE%" ^
--StartClass="%JETTY_START_CLASS%" ^
--StartParams="%PR_STARTPARAMS%" ^
--StopMode="%PR_STOPMODE%" ^
--StopClass="%PR_STOPCLASS%" ^
--StopParams="%PR_STOPPARAMS%"
if not errorlevel 1 goto installed
echo Failed to install "%SERVICE_NAME%" service. Refer to log in %PR_LOGPATH%
goto end
:installed
echo The Service "%SERVICE_NAME%" has been installed
:end
- Depois execute o arquivo, clicando duas vezes no install-jetty-service.bat.
- Abra o Service Local e inicie o serviço.

Supondo que você tenha seu aplicativo da web implantado no jetty, há duas maneiras diferentes de abordar isso:
java -Xdebug -agentlib:jdwp=transport=dt_socket,address=9999,server=y,suspend=n -jar start.jar#===========================================================
# Configure JVM arguments.
# If JVM args are include in an ini file then --exec is needed
# to start a new JVM from start.jar with the extra args.
# If you wish to avoid an extra JVM running, place JVM args
# on the normal command line and do not use --exec
#-----------------------------------------------------------
--exec
-Xdebug
-agentlib:jdwp=transport=dt_socket,address=9999,server=y,suspend=n
# -Xmx2000m
# -Xmn512m
# -XX:+UseConcMarkSweepGC
# -XX:ParallelCMSThreads=2
# -XX:+CMSClassUnloadingEnabled
# -XX:+UseCMSCompactAtFullCollection
# -XX:CMSInitiatingOccupancyFraction=80
# -verbose:gc
# -XX:+PrintGCDateStamps
# -XX:+PrintGCTimeStamps
# -XX:+PrintGCDetails
# -XX:+PrintTenuringDistribution
# -XX:+PrintCommandLineFlags
# -XX:+DisableExplicitGC


Em construção
# nginx
nginx -s [ stop | quit | reopen | reload ]
# via system d
sudo systemctl [ stop | quit | reopen | reload ] nginx
## copiar site andre
sudo cp -r /home/uni/Downloads/andre-xbox-series-x/nexus-new-cadastro-front/distwar/src/main/webapp/* /usr/share/nginx/htmlFerramentas Windows
–
Documentação - 2.2. Configuração do NGINX
Virtual hosts - Como criar Virtual Hosts com Nginx
## Do site estatico
# mkdir -p /var/www/<nome-site>/public_html
mkdir -p /var/www/unisite.com/public_html# mkdir /var/log/nginx/<nome-site>/
mkdir /var/log/nginx/unisite.com/# sudo chown -R www-data:www-data /var/www/<nome-site>/public_html
sudo chown -R www-data:www-data /var/www/unisite.com/public_html
# todos estejam aptos a ler seus arquivos. Para isso, utilize o comando abaixo:
# sudo chmod 755 /var/www# cp -r /<path-do-site>/* /var/www/<nome-site>/public_html# sudo cp /etc/nginx/sites-available/default /etc/nginx/sites-available/<nome-site>
sudo cp /etc/nginx/sites-available/default /etc/nginx/sites-available/unisite.com# code /etc/nginx/sites-available/<nome-site>
# sudo nano /etc/nginx/sites-available/<nome-site>
code /etc/nginx/sites-available/unisite.com
# Add os itens abaixo
server {
listen 80; ## listen for ipv4; this line is default and implied
#listen [::]:80 default ipv6only=on; ## listen for ipv6
# root /var/www/<nome-site>/public_html;
root /var/www/unisite.com/public_html;
index index.html index.htm;
# access_log /var/log/nginx/<nome-site>/access.log;
access_log /var/log/nginx/ unisite.com/access.log;
# error_log /var/log/nginx/<nome-site>/error.log;
error_log /var/log/nginx/ unisite.com/error.log;
# Make site accessible from http://localhost/
# server_name <nome-site>;
server_name unisite.com;
}# sudo ln -s /etc/nginx/sites-available/<nome-site> /etc/nginx/sites-enabled/<nome-site>
sudo ln -s /etc/nginx/sites-available/unisite.com /etc/nginx/sites-enabled/ unisite.com
# Desabilite o Default Virtual Host
sudo unlink /etc/nginx/sites-enabled/defaultsystemctl restart nginx
# ou
sudo service nginx restartnano /etc/hosts
#Virtual Hosts
localhost www.example.com # Logs de acesso default
tail /var/log/nginx/access.log -f
# personalizado
# tail /var/log/nginx/<nome-site>/access.log -f
tail /var/log/nginx/unisite.com/access.log -f
# Erros default
tail /var/log/nginx/error.log
# personalizado
# tail /var/log/nginx/<nome-site>/error.log
tail /var/log/nginx/unisite.com/error.logsudo unlink /etc/nginx/sites-enabled/default# Criando arquivo
touch etc/nginx/sites-available/reverse-proxy.conf
# Edite
code etc/nginx/sites-available/reverse-proxy.conf
# sudo nano etc/nginx/sites-available/reverse-proxy.conf
# Adicione
server {
listen 80;
location / {
proxy_pass http://192.x.x.2; # redireciona o que vem para esse ip
}
}sudo ln -s /etc/nginx/sites-available/reverse-proxy.conf /etc/nginx/sites-enabled/reverse-proxy.confservice nginx configtestsystemctl restart nginx
# ou
sudo service nginx restartEm construção
Paginas:
Em construção
# Lista as tasks
gradle tasks
# Mostrar o help
gradle help --taks init
# Inicia um projeto
gradle init
# Executar o projeto
gradle run
# Executa os testes
gradle test
# Installar as dependencias
gradle build --scan
# Builda3 o projeto
gradle build
# Ver cobertura de testes
/app/build/reports/tests/test/index.htmljar tf app.jar# extrai manifest
jar xf app.jar META-INF/MANIFEST.MF
# exibe
cat META-INF/MANIFEST.MFjava -jar app.jartasks.register('teste') {
println 'Hello world'
}
tasks.register('hello') {
doLast {
println 'Hello world!'
}
}gradle -q teste
-ou
gradle teste // mostra status da execuçãolink: https://docs.gradle.org/current/userguide/tutorial_using_tasks.html#sec:projects_and_tasks
tasks.register('upper') {
doLast {
String someString = 'mY_nAmE'
println "Original: $someString"
println "Upper case: ${someString.toUpperCase()}"
}
}
// exemplo de repetição
tasks.register('count') {
doLast {
4.times { print "$it " }
}
}gradle uppertasks.register('taskX') {
dependsOn 'taskY'
doLast {
println 'taskX'
}
}
tasks.register('taskY') {
doLast {
println 'taskY'
}
}gradle taskX
# mostrar a execução das duas tasks, pois a taskX depende da taskYtasks.register('hello') {
doLast { // definie a ordem de execução
println 'Hello Earth'
}
}
tasks.named('hello') {
doFirst { // defini a orde de execução
println 'Hello Venus'
}
}
tasks.named('hello') {
doLast {
println 'Hello Mars'
}
}
tasks.named('hello') {
doLast {
println 'Hello Jupiter'
}
}gradle -q hello
#saida
#Olá Vênus
#Olá terra
#Olá marte
#Ola jupiterhttps://docs.gradle.org/current/userguide/plugins.html#plugins | –> Aplicando plug-ins com o DSL de plug-ins
- As dependências pode ser de dois tipos:
- como configurações do tipo api - que serão expostas transitivamente aos consumidores da biblioteca e, como tal, aparecerão no classpath de compilação dos consumidores
- como configuração do tipo implementation que, por outro lado, não serão expostas aos consumidores e, portanto, não vazarão para o classpath de compilação dos consumidores
dependencies {
api 'org.apache.httpcomponents:httpclient:4.5.7'
implementation 'org.apache.commons:commons-lang3:3.5'
}OBS: As configurações compile e runtime foram removidas com o Gradle 7.0. Consulte o guia de atualização como migrar para implementatione apiconfigurações. - compile –> implementation - runtime –> api
Prefira a configuração de implementation em vez de api quando possível.
Em construção
Paginas:
Em construção
# Lista o conteudo do jar
java -jar tf app.jar
# Mostra o conteudo do arquivo manifest
## extrai manifest
java -jar xf app.jar META-INF/MANIFEST.MF
## exibir conteudo
cat META-INF/MANIFEST.MF
# Executa aplicação
java -jar app.jarpackage streams;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
public class MinMax {
public static void main(String[] args) {
Aluno a1 = new Aluno("Ana", 7.1);
Aluno a2 = new Aluno("Luna", 6.1);
Aluno a3 = new Aluno("Gui", 8.1);
Aluno a4 = new Aluno("Gabi", 10);
List<Aluno> alunos = Arrays.asList(a1, a2, a3, a4);
Comparator<Aluno> melhorNota = (aluno1, aluno2) -> {
if(aluno1.nota > aluno2.nota) return 1;
if(aluno1.nota < aluno2.nota) return -1;
return 0;
};
Comparator<Aluno> piorNota = (aluno1, aluno2) -> {
if(aluno1.nota > aluno2.nota) return -1;
if(aluno1.nota < aluno2.nota) return 1;
return 0;
};
System.out.println(alunos.stream().max(melhorNota).get());
System.out.println(alunos.stream().min(piorNota).get());
System.out.println(alunos.stream().min(melhorNota).get());
System.out.println(alunos.stream().max(piorNota).get());
}
}Metodos uteis - limit / skip / distinct / takeWhile
package streams;
import java.util.Arrays;
import java.util.List;
public class Outros {
public static void main(String[] args) {
Aluno a1 = new Aluno("Ana", 7.1);
Aluno a2 = new Aluno("Luna", 6.1);
Aluno a3 = new Aluno("Gui", 8.1);
Aluno a4 = new Aluno("Gabi", 10);
Aluno a5 = new Aluno("Ana", 7.1);
Aluno a6 = new Aluno("Pedro", 9.1);
Aluno a7 = new Aluno("Gui", 8.1);
Aluno a8 = new Aluno("Maria", 10);
List<Aluno> alunos =
Arrays.asList(a1, a2, a3, a4, a5, a6, a7, a8);
System.out.println("distinct...");
// recuperar os valores distintos (precisa do equals e hash code)
alunos.stream().distinct().forEach(System.out::println);
System.out.println("\nSkip/Limit");
alunos.stream()
.distinct()
.skip(2) // pulo uma quantidade de itens
.limit(2) // limita a quantidade de retorno
.forEach(System.out::println);
System.out.println("\ntakeWhile");
alunos.stream()
.distinct()
.skip(2)
.takeWhile(a -> a.nota >= 7) // retorna ate achar a condição
.forEach(System.out::println);
}
}Em construção
Em construção
link: Como posso instalar o protobuf no ubuntu 12.04?
ou
sudo apt-get install libprotobuf-java protobuf-compilerprotoc -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/<file>.protolink: https://developers.google.com/protocol-buffers/docs/proto3
message SearchRequest {
string query = 1;
int32 page_number = 2; // Which page number do we want?
int32 result_per_page = 3; // Number of results to return per page.
}message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
// Usando alias para representar a mesma coisa
message MyMessage1 {
enum EnumAllowingAlias {
option allow_alias = true; // necessario deixar essa opção como true, senão vai dar erro, como abaixo
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
}
message MyMessage2 {
enum EnumNotAllowingAlias {
UNKNOWN = 0;
STARTED = 1;
// RUNNING = 1; // Uncommenting this line will cause a compile error inside Google and a warning message outside.
}
}
//Observe que você não pode misturar nomes de campo e valores numéricos na mesma reservedinstrução.
message SearchResponse {
repeated Result results = 1; //o repeat dis que pode ser repetido os itens, semelhate a uma lista
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
// Tipo aninhado
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}
// chamdando tipo aninhado
message SomeOtherMessage {
SearchResponse.Result result = 1;
}
// Exemplo de message aninhada
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Level 1
message Inner { // Level 2
int32 ival = 1;
bool booly = 2;
}
}
}caso a mensagem que queira colocar dentro da mensagem esteja em outro proto, vc pode importa-lo
import "myproject/other_protos.proto";O gRPC permite definir quatro tipos de método de serviço:
Em que o cliente envia uma única solicitação ao servidor e obtém uma única resposta, exatamente como uma chamada de função normal.
rpc SayHello(HelloRequest) returns (HelloResponse);Em que o cliente envia uma solicitação ao servidor e obtém um stream para ler uma sequência de mensagens de volta. O cliente lê a partir do fluxo retornado até que não haja mais mensagens. O gRPC garante a ordem das mensagens em uma chamada RPC individual.
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse);Em que o cliente grava uma sequência de mensagens e as envia ao servidor, novamente usando um fluxo fornecido. Depois que o cliente termina de escrever as mensagens, ele espera que o servidor as leia e retorne sua resposta. Mais uma vez, o gRPC garante a ordem das mensagens em uma chamada RPC individual.
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse);Em que ambos os lados enviam uma sequência de mensagens usando um fluxo de leitura e gravação. Os dois fluxos operam de forma independente, para que os clientes e servidores possam ler e escrever na ordem que quiserem: por exemplo, o servidor pode esperar para receber todas as mensagens do cliente antes de escrever suas respostas, ou pode alternativamente ler uma mensagem e depois escrever uma mensagem, ou alguma outra combinação de leituras e gravações. A ordem das mensagens em cada fluxo é preservada.
rpc BidiHello(stream HelloRequest) returns (stream HelloResponse);Paginas:
Paginas:
Em construção
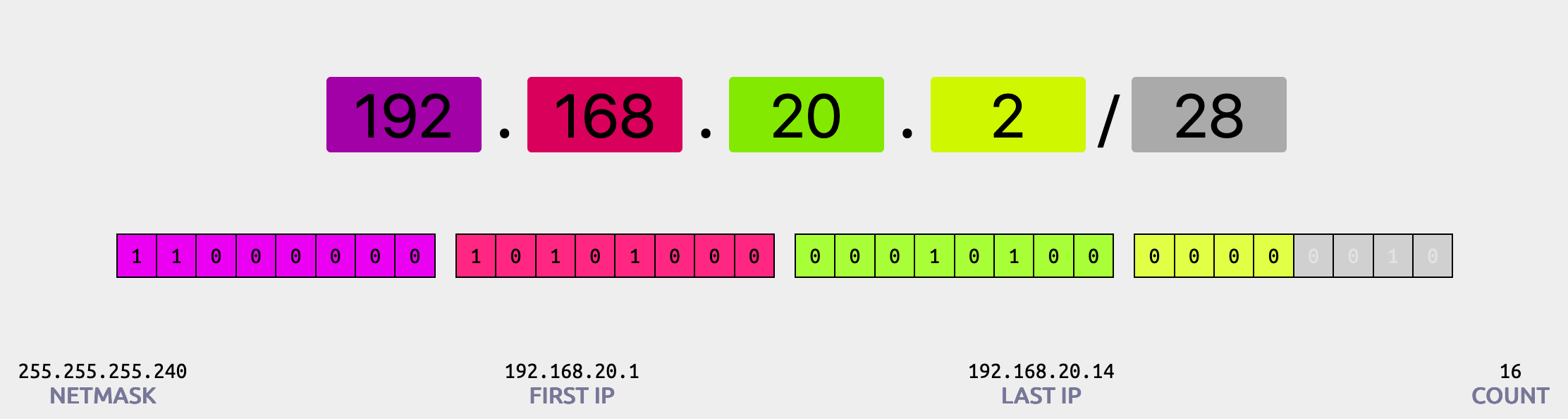
| Dominío | percentual |
|---|---|
| Domínio 1: Design de arquiteturas resilientes | 30% |
| Domínio 2: Design de arquiteturas de alta performance | 28% |
| Domínio 3: Design de aplicações e arquiteturas seguras | 24% |
| Domínio 4: Design de arquiteturas econômicas | 18% |
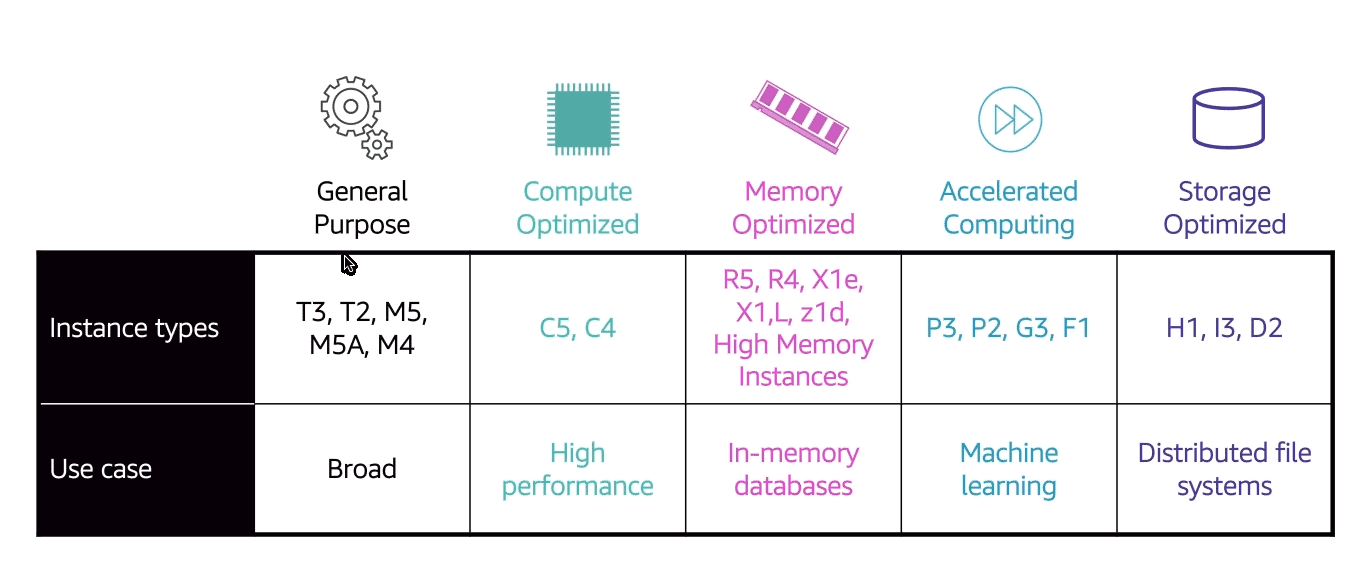
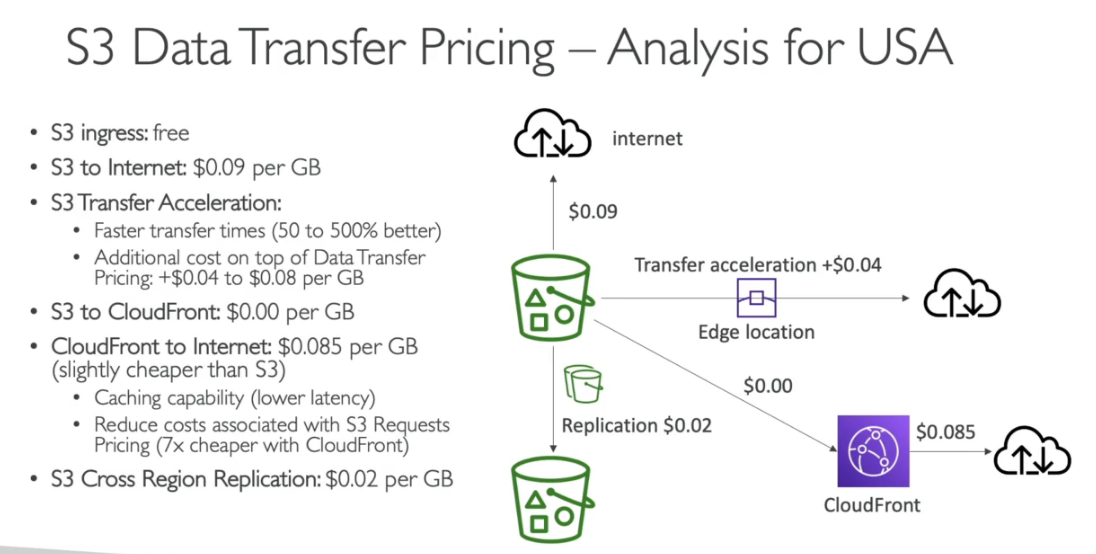
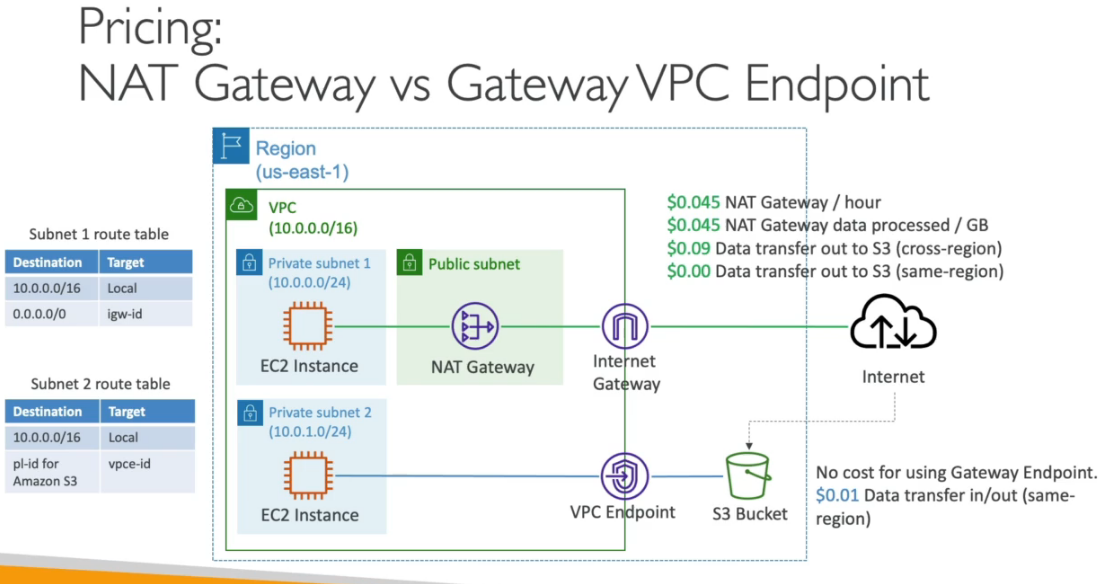
Tecnologias aws que podem vão cair na prova
Serviços abordados
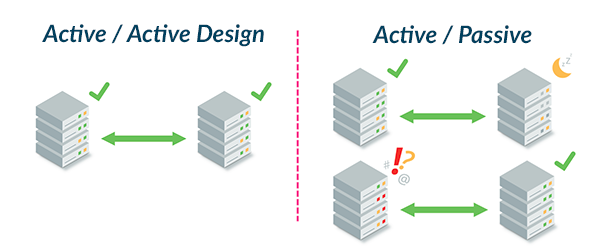
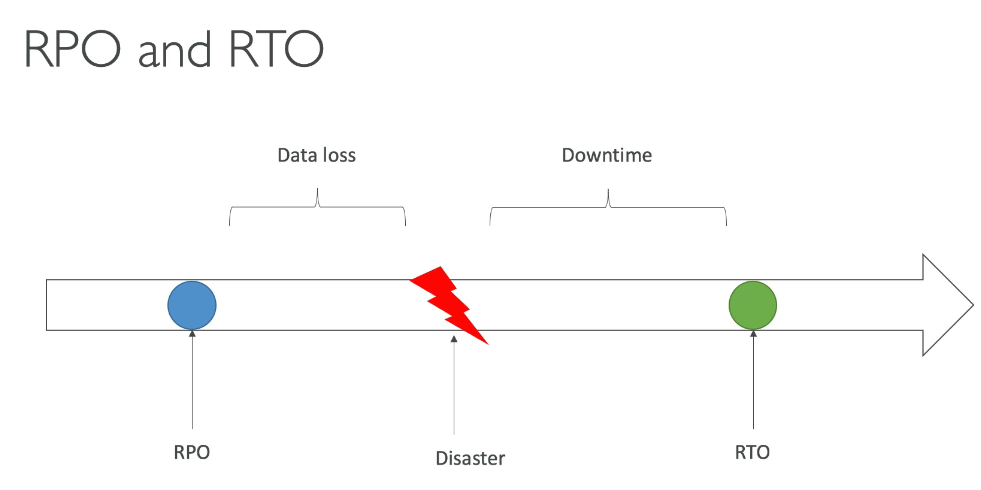
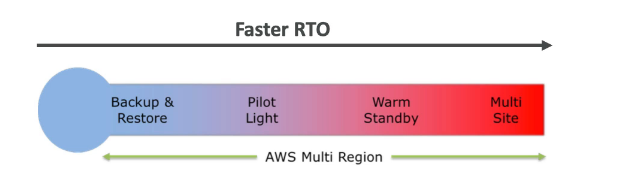
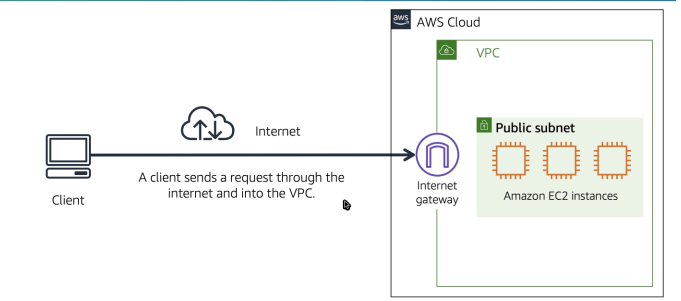
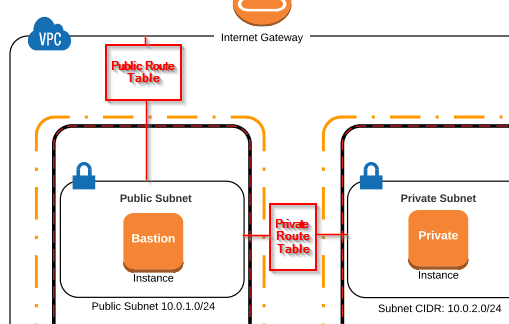
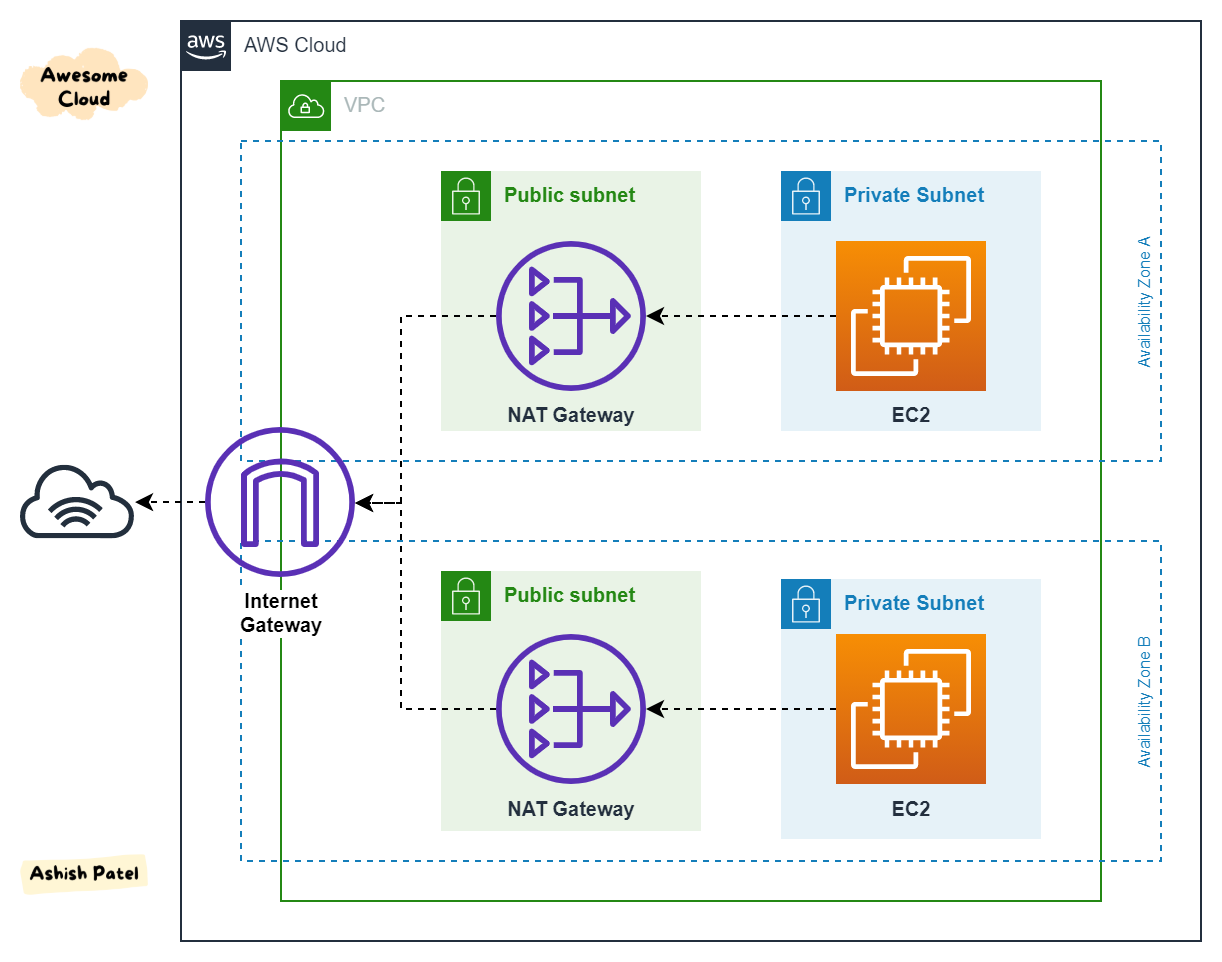
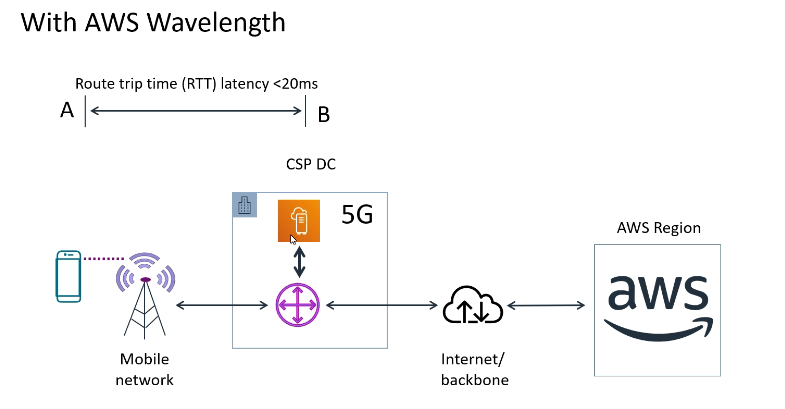
No caso do AWS, refere-se as multi AZs, que dão a segurança de que caso uma fique de fora, a outras ainda estarão disponível.
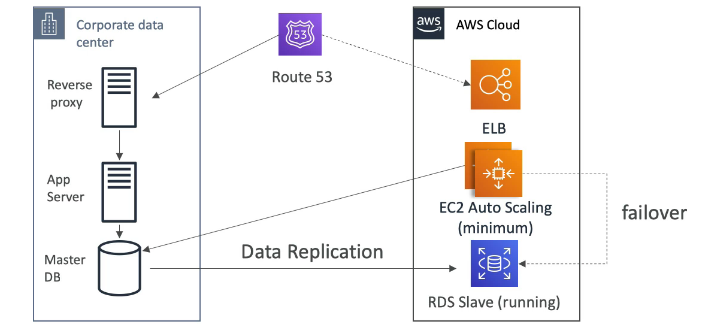
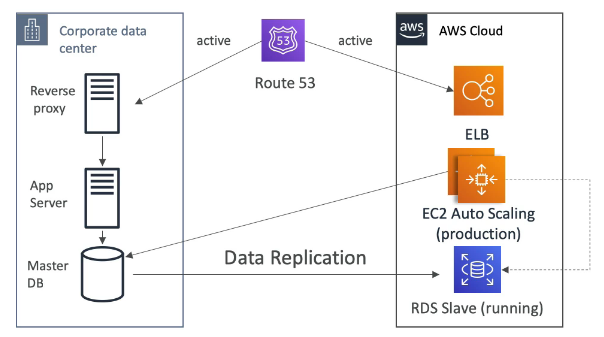
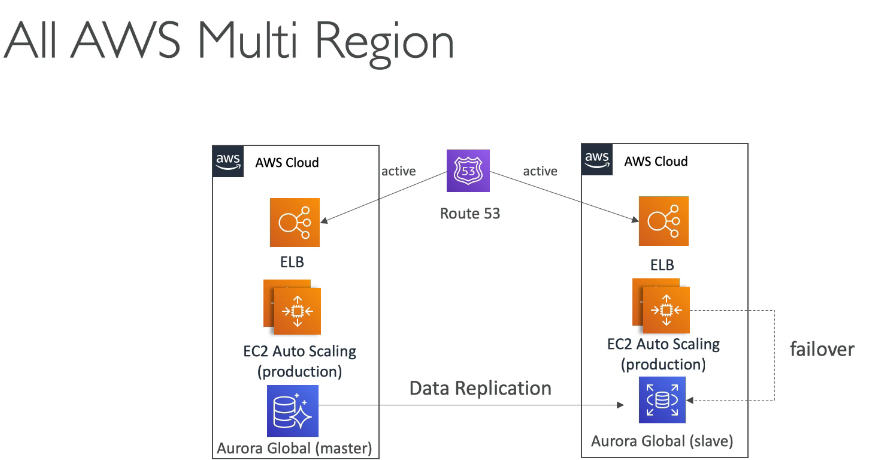






Todas são pagas por horas ativas.
dedicate host
Saving plan
Capacity Reservation
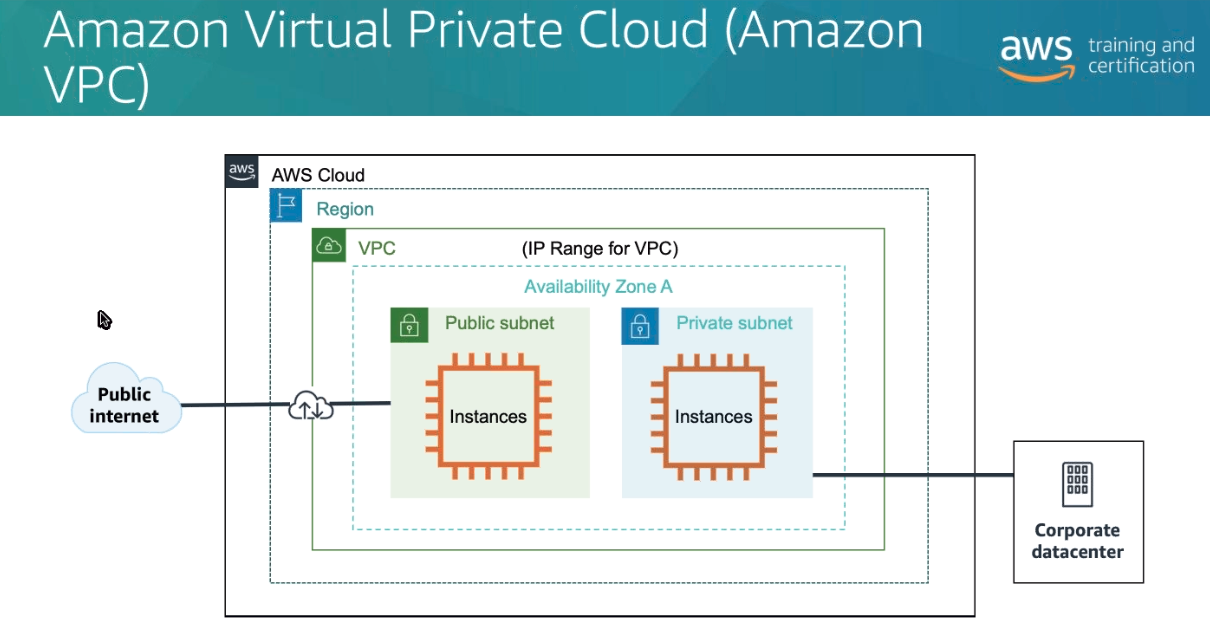
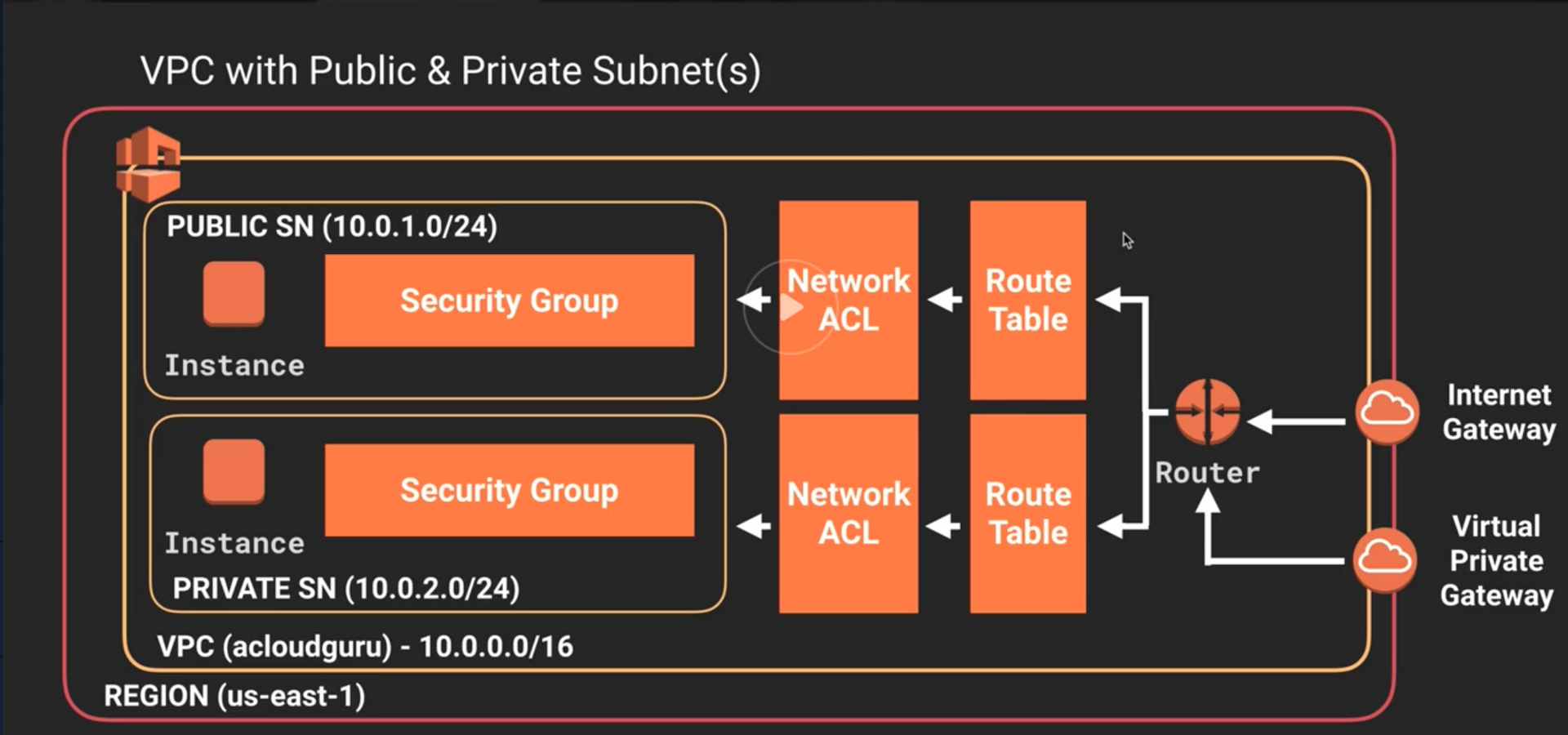
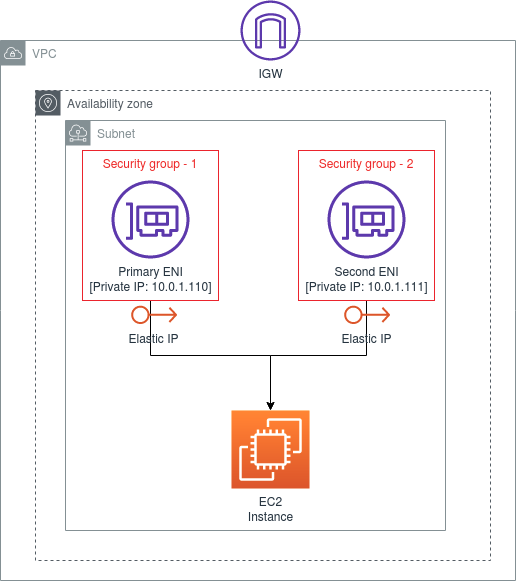
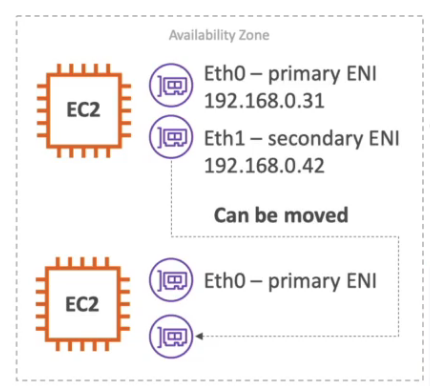
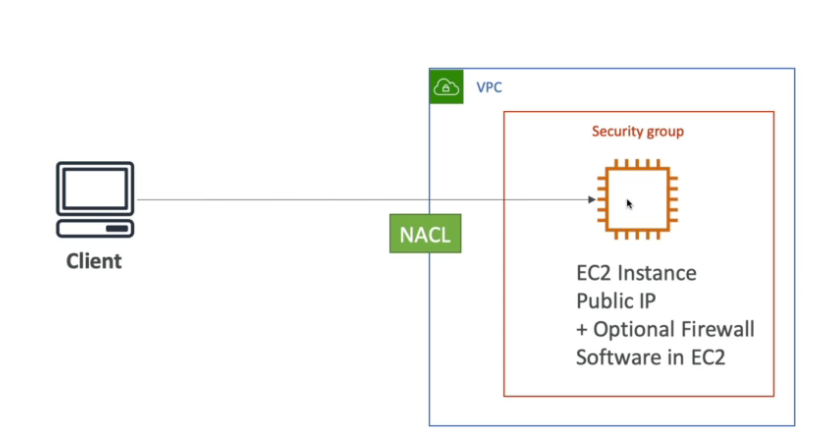
Acessando a API de meta-dados de EC2 e possível acessar informações sobre diversos dados usados pela instância apenas dando um curl 169.254.169.254/latest/meta-data.


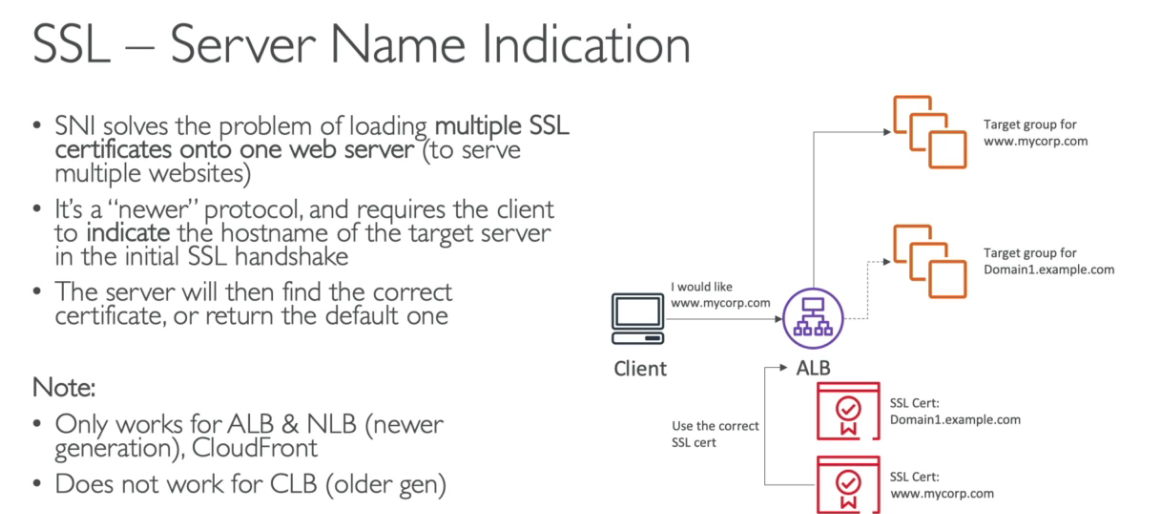

Serviço de banco de dados relacional da AWS.



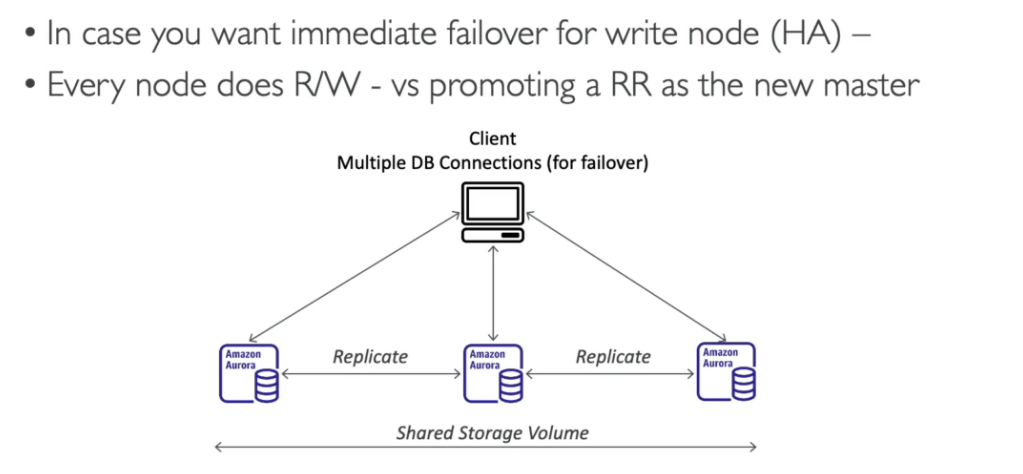
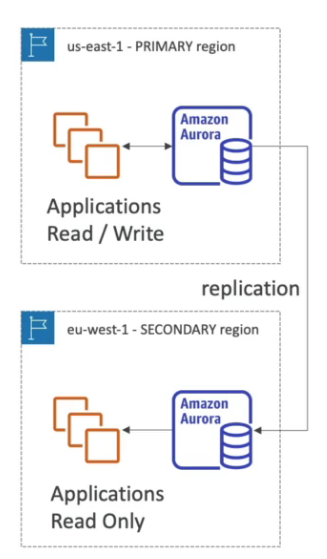
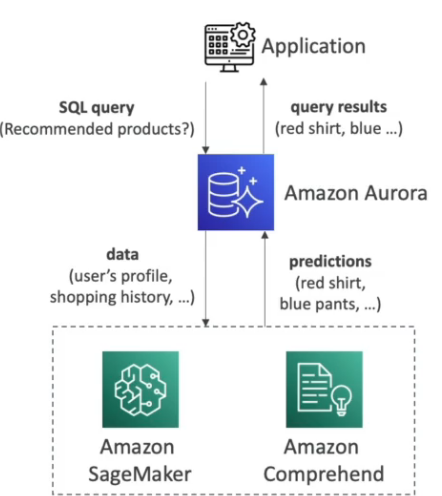
Quando se cria um bando no RDS se passa quando ele deve ter, com essa funcionalidade ele aumenta o tamanho da banco ao se aproximar de limite de uso do espaço.
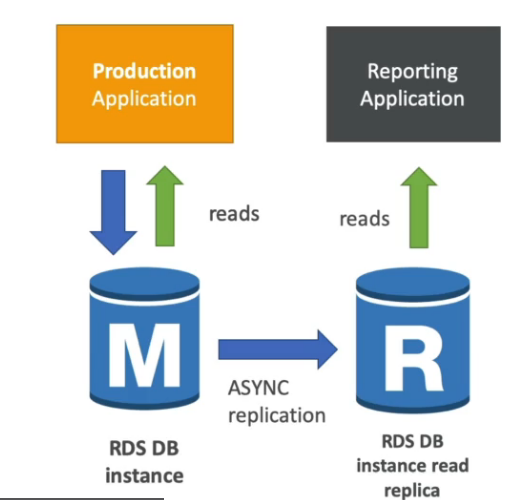
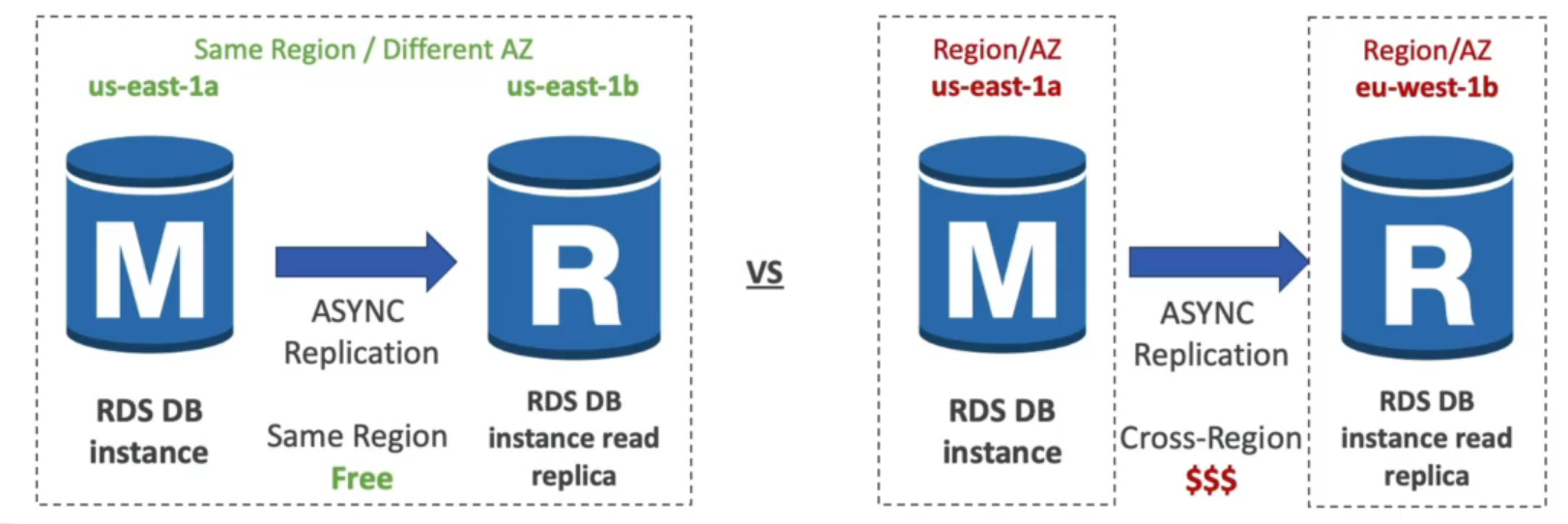
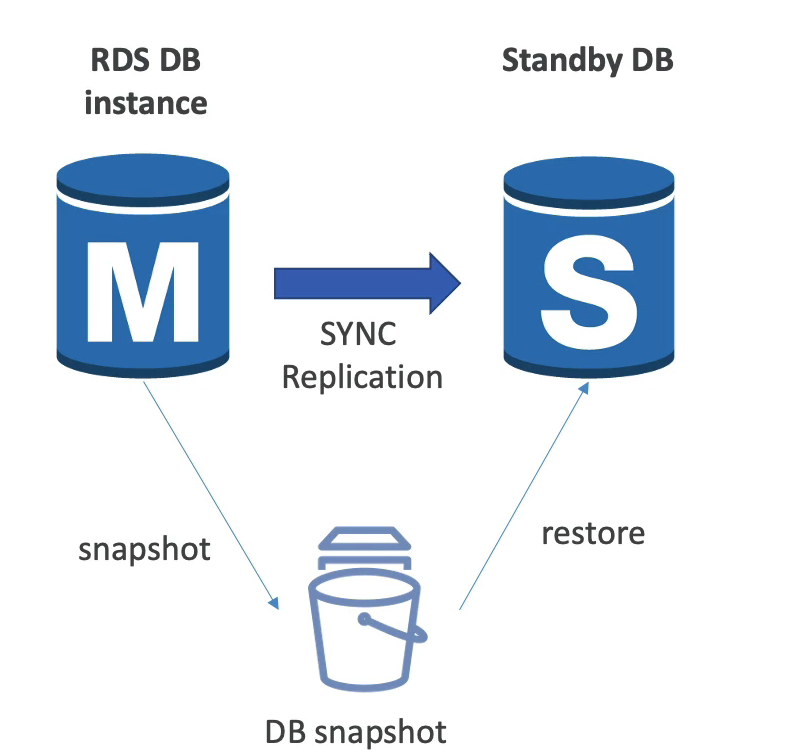
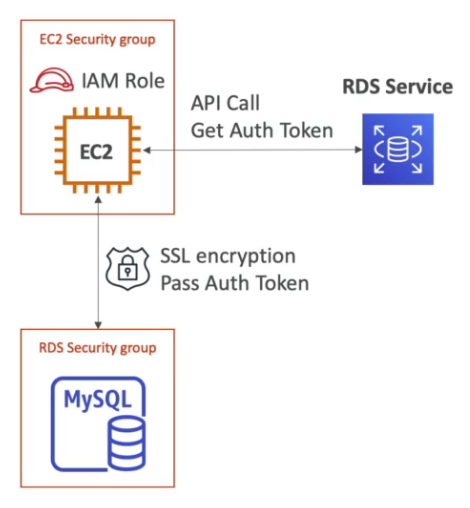


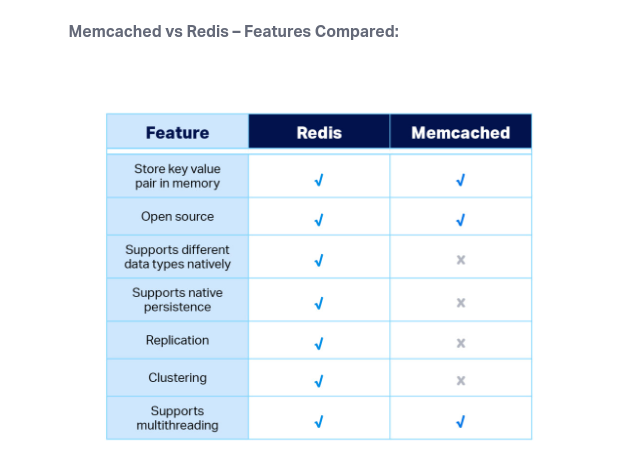




Para escolher o melhor banco de dados para lhe atender algumas perguntas são importantes a se fazer.
- RDS - Postgres, MySql, SqlServer, Oracle
- Aurora - Bons para Joins e Dados normalizados.
- DynamoDB (~Json)
- ElastiCache (key-pairs)
- Neptune (Graphs) - Sem Joins
- S3 (Objetos grandes)
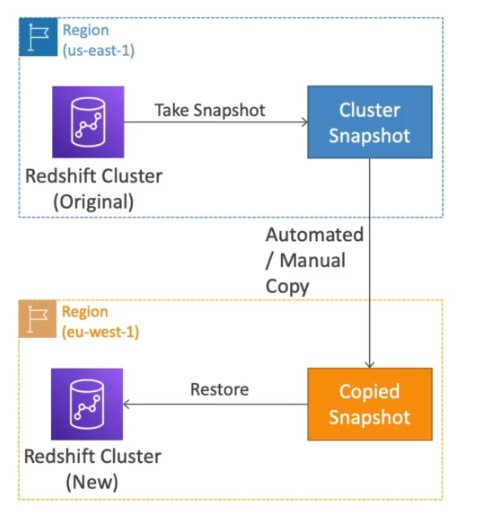
- S3 Glacier - (backups | Arquivamento)
- RedShift (OLAP)
- Athena (S3 Querys)
- ElasticSearch (json) - Busca por texto livre, ou estruturas pré definidas.
- Neptune - Mostra relacionamento entre objetos
| PRODUTO | DESCRIÇÃO |
|---|---|
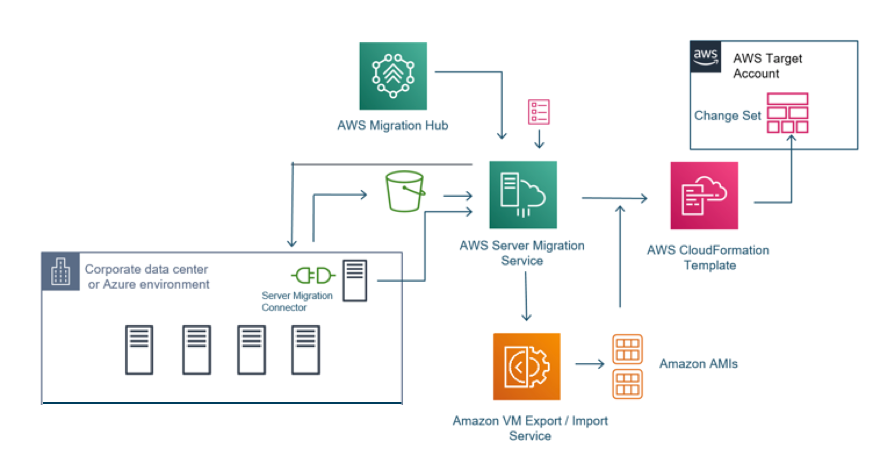
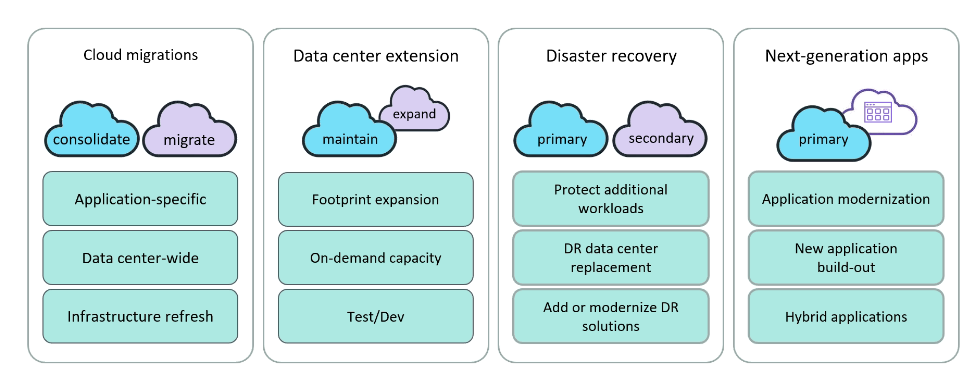
| AWS Migration Hub | Um local único para rastrear o andamento das migrações de aplicações |
| AWS Application Discovery Service | Coleta informações de especificação, dados de performance e detalhes de processos em execução e conexões de rede dos servidores |
| AWS Server Migration Service | Serviço sem agente para migrar workloads apenas virtuais da infraestrutura on-premises ou do Microsoft Azure para a AWS |
| AWS Service Catalog | Crie e gerencie catálogos de serviços de TI aprovados para uso na AWS. |
| AWS Database Migration Service | O AWS Database Migration Service ajuda você a migrar bancos de dados para a AWS de modo rápido e seguro. |
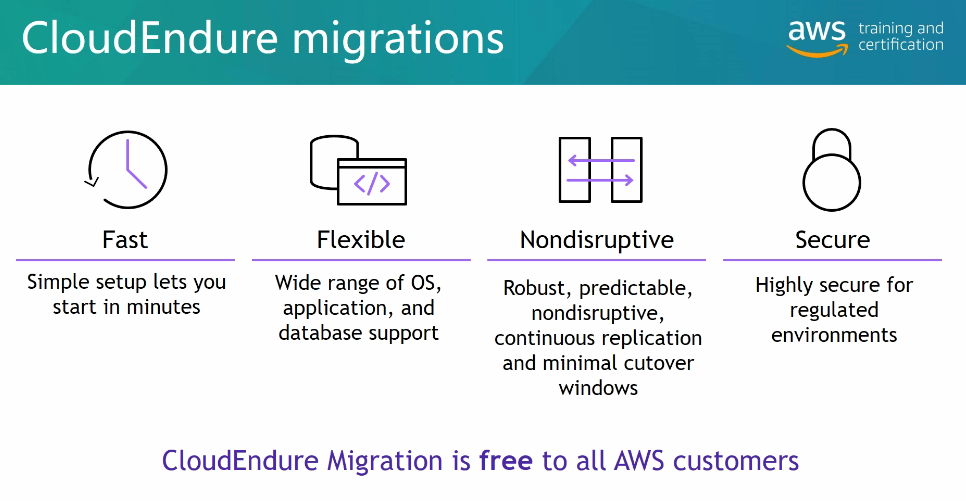
| AWS Application Migration Service | Simplifique e agilize migrações enquanto reduz custos |


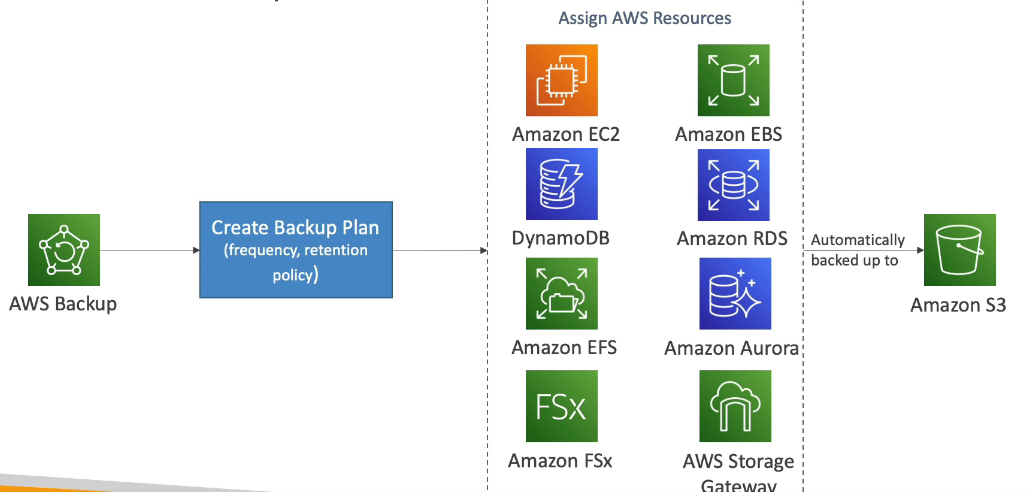
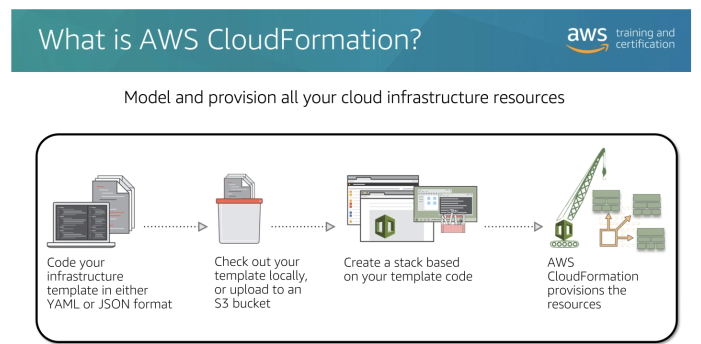
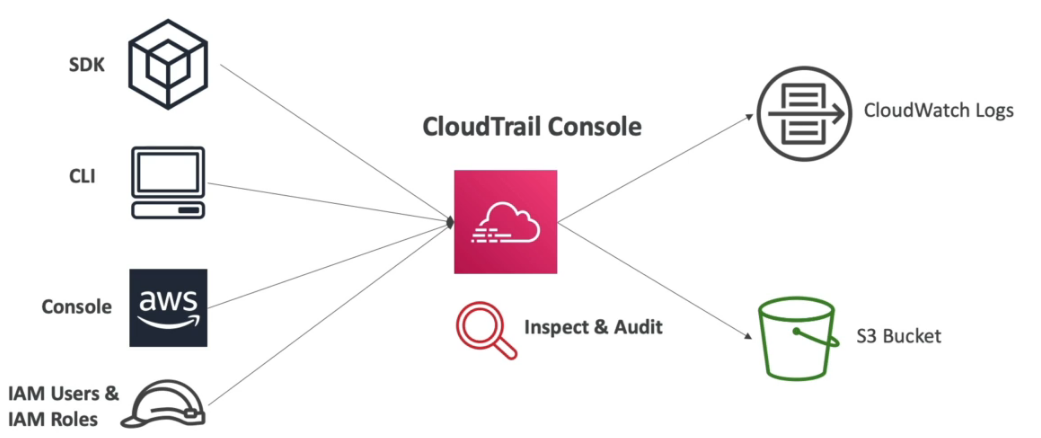


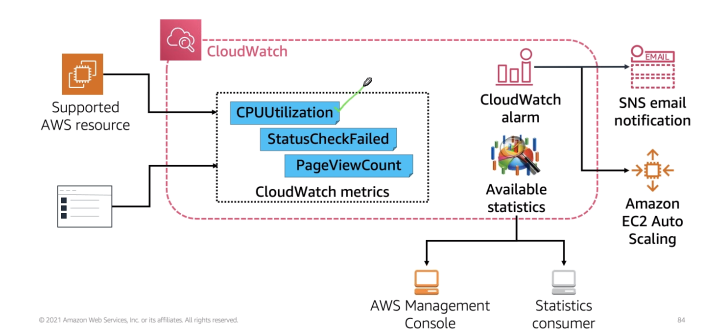
Permite criar eventos, ous seja ações predefinidas ou agendadas que podem disparar alguns serviços AWS (regras que define ações).
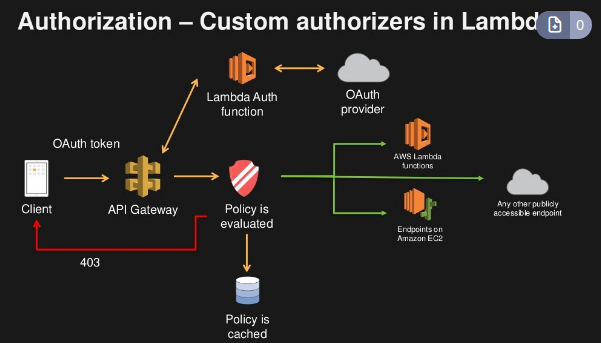
addFilterBefore para adicionar o nosso filtro `Jwt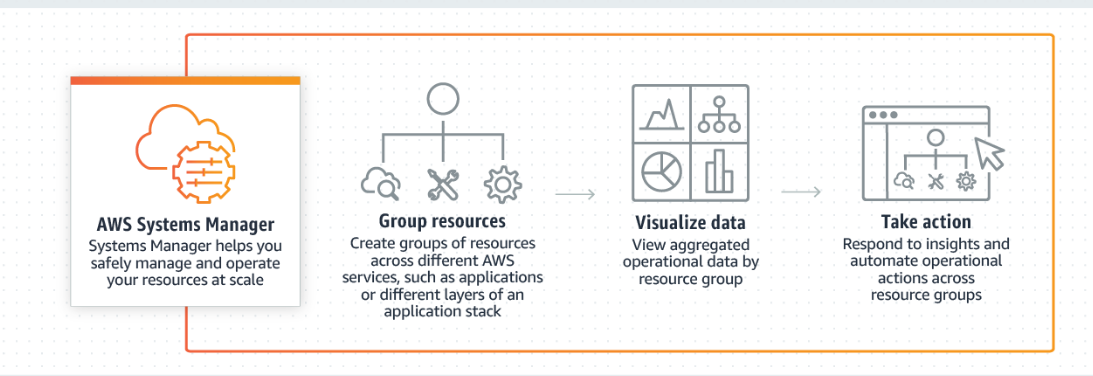


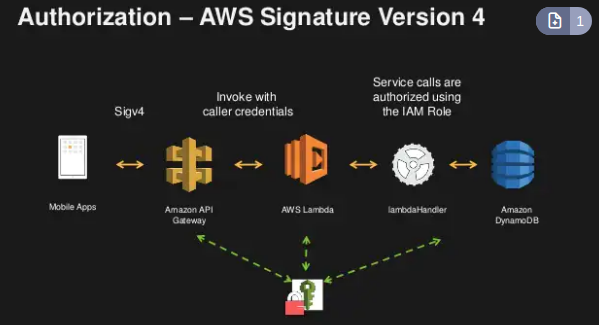
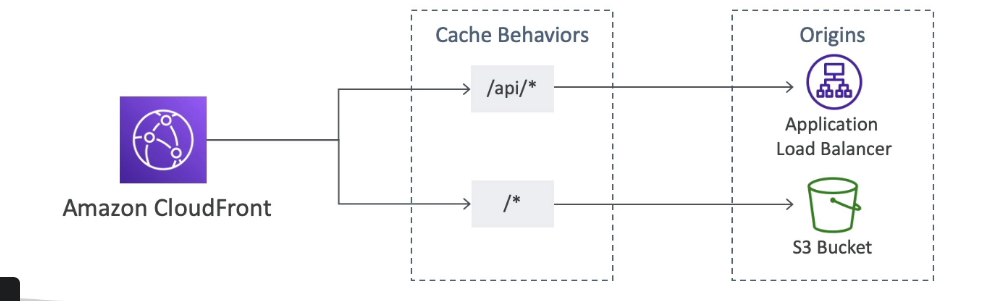
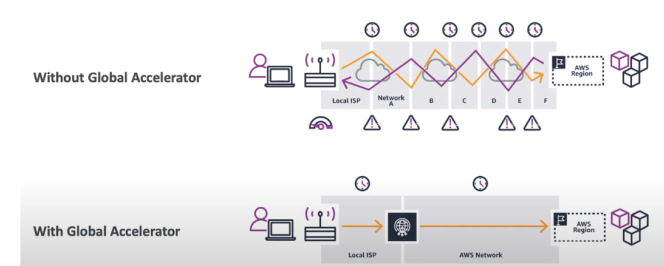
Serviço que melhora a disponibilidade de um serviço usando os ponto de presença, melhora a disponibilidade em cerca de 60%.
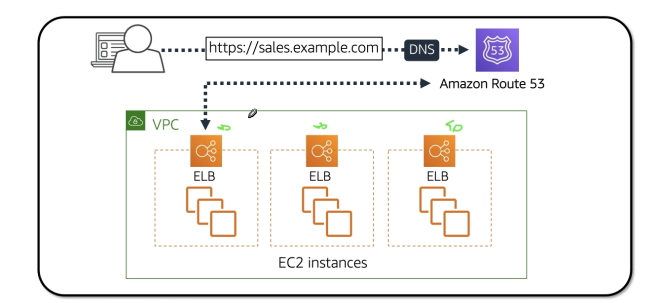
São políticas de redirecionamento que é possível configurar no route 53.
Pode se configurar health checks para monitora a disponibilidade e a saúde da aplicação.



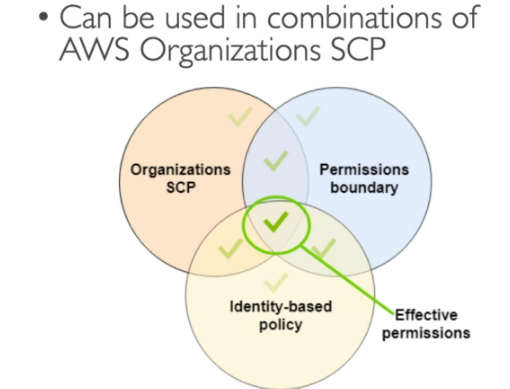
- Há dois via sofware (dispositivo MFA virtual, Chave de chegurança U2F (ex: YUbiKey))
- Há uma opção de Hardware (ex: token Gemalto)Basic recomendations



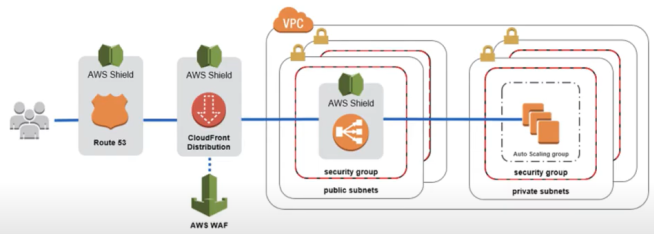

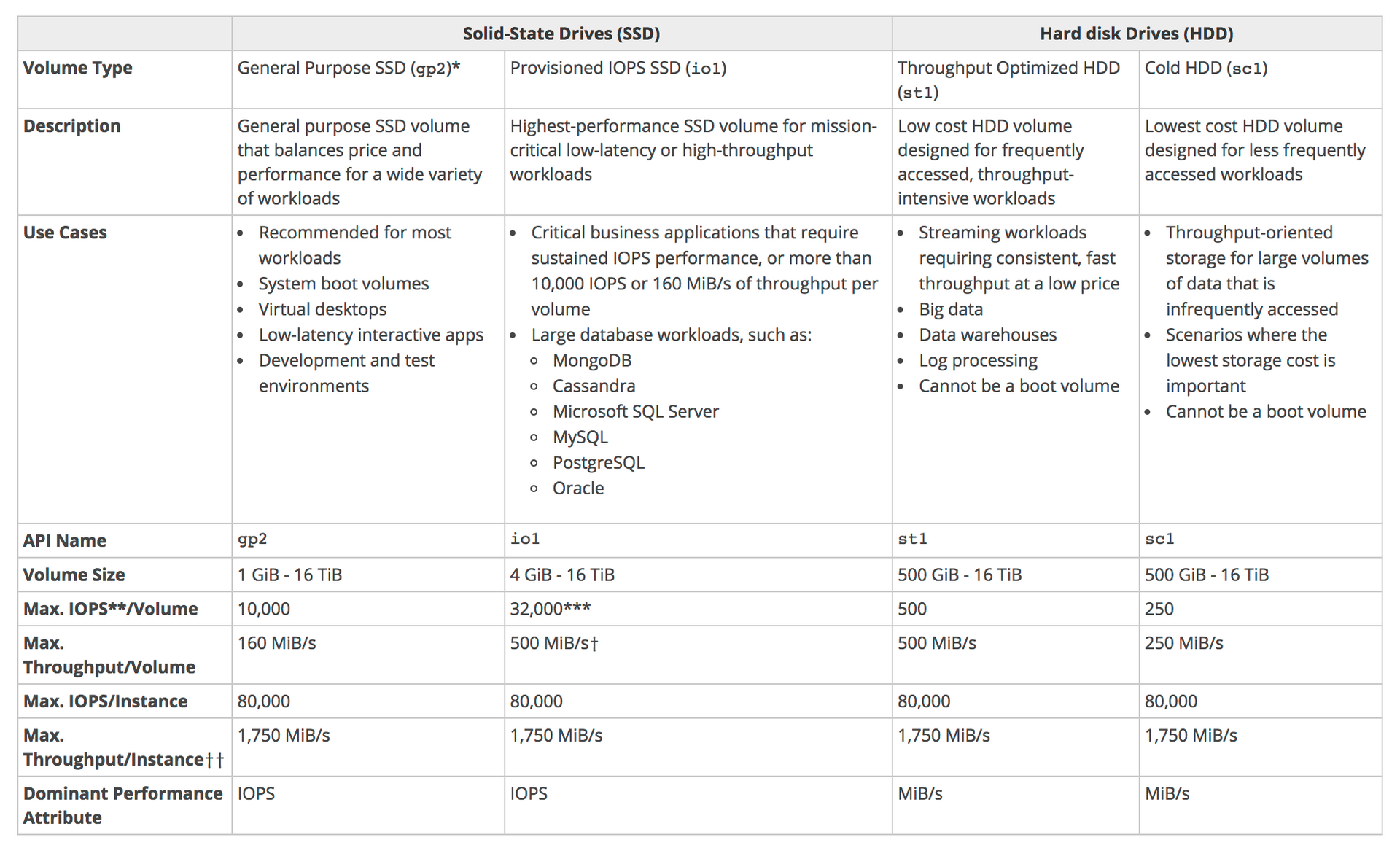
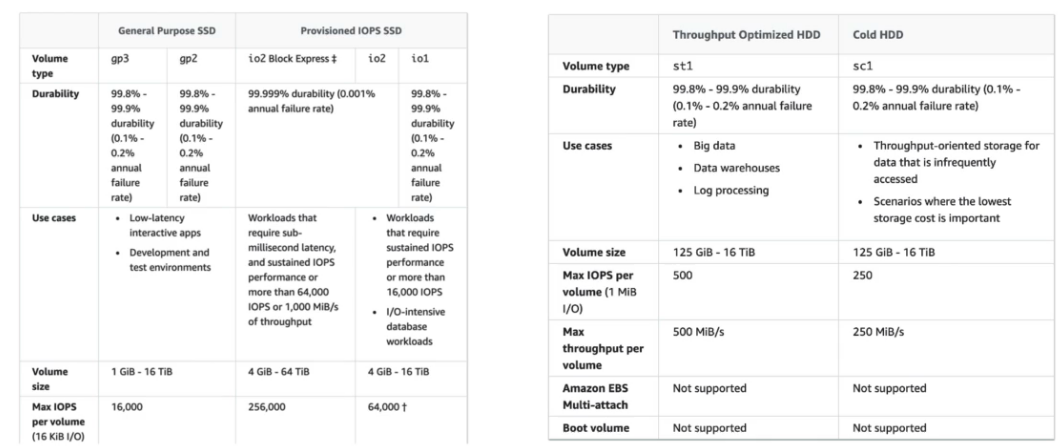 os tipos io1 / io2 permitem conectar o mesmo em mais de uma instância, isso é usado em aplicação de alta disponibilidade, ex Cassandra …
os tipos io1 / io2 permitem conectar o mesmo em mais de uma instância, isso é usado em aplicação de alta disponibilidade, ex Cassandra …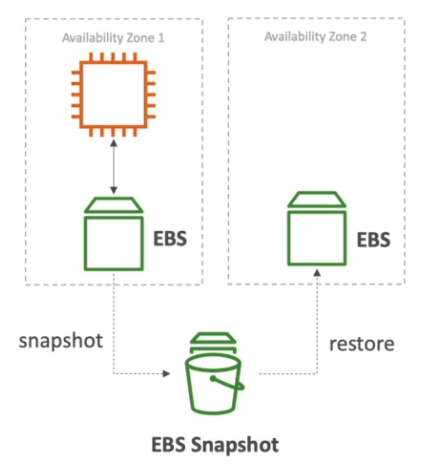
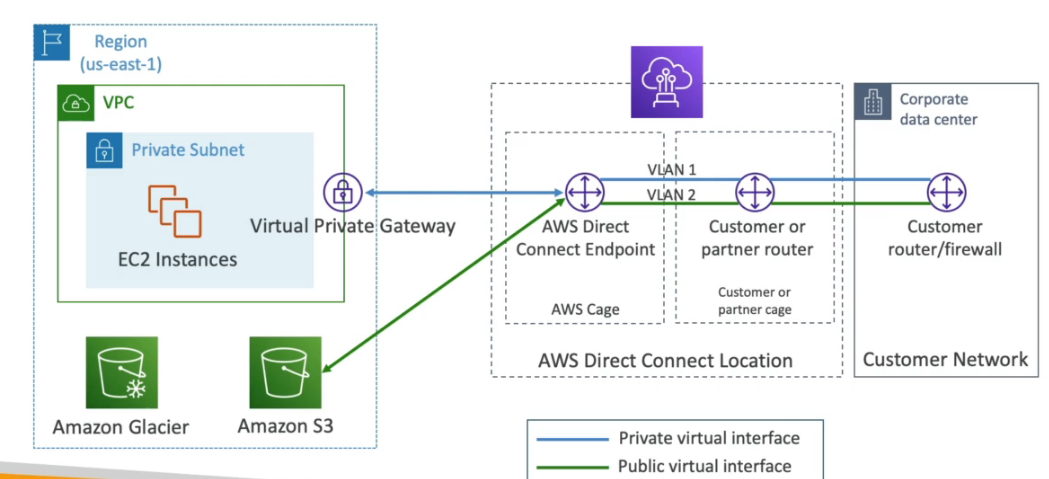
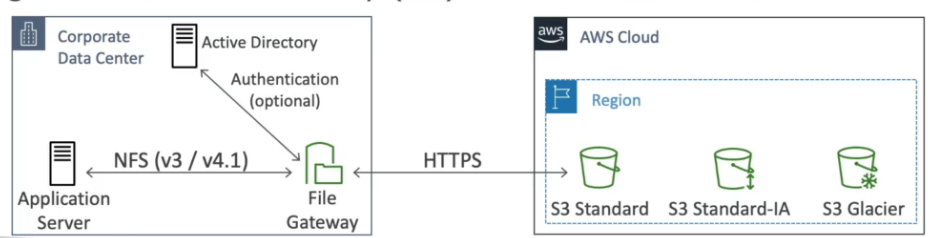
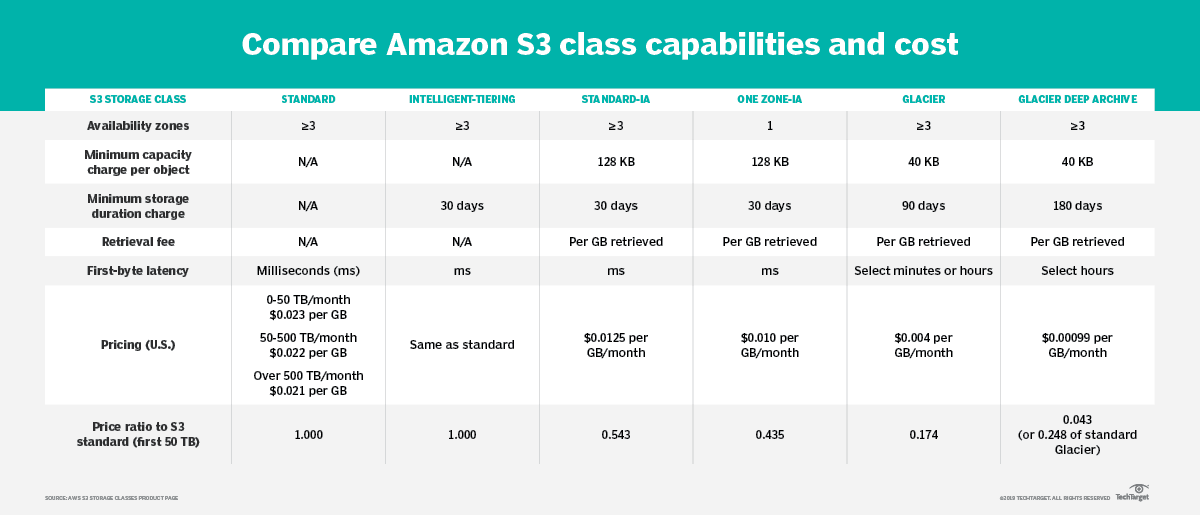 Recomendação de leitura: Analise as classes de armazenamento do Amazon S3, do padrão ao Glacier
Recomendação de leitura: Analise as classes de armazenamento do Amazon S3, do padrão ao Glacier





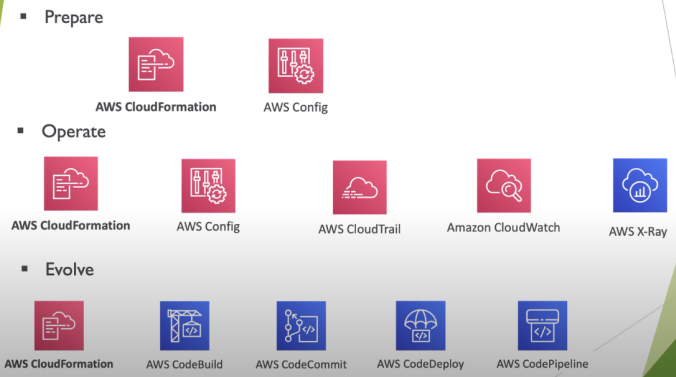
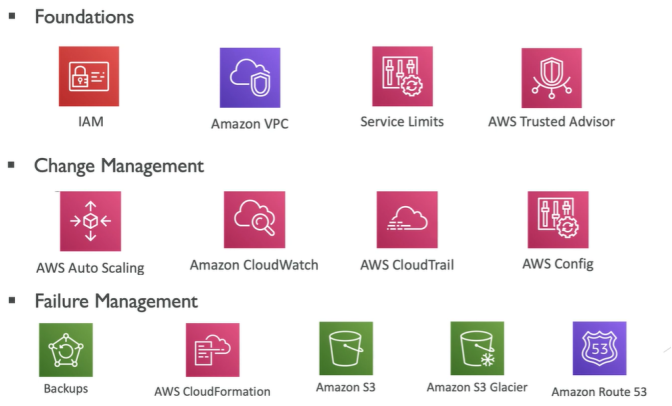
Inclui a capacidade de apoiar o desenvolvimento e executar cargas de trabalho de forma eficaz, obter uma visão sobre sua operação e melhorar continuamente os processos e procedimentos de suporte para entregar valor de negocio.
Design Principles
- Executar operações como código, infraestrutura as code.
- Documente os processos.
- Faça alterações frequentes, pequenas e reversíveis.
- Refine os procedimentos de operações com frequência.
- Antecipar o fracasso
- Aprenda com todas as falhas operacionais.
Capacidade de proteger dados, sistemas e ativos para aproveitar as vantagens das tecnologias de nuvem para melhorar sua segurança.
Design Principles
- Implemente uma base de identidade forte - Mínimo privilegio possível.
- Ative a rastreabilidade. Habilitar tracing integrado.
- Aplique segurança em todas as camadas.
- Automatize as melhores práticas de segurança.
- Proteja os dados em trânsito e em repouso.
- Mantenha as pessoas longe dos dados.
- Prepare-se para eventos de segurança.
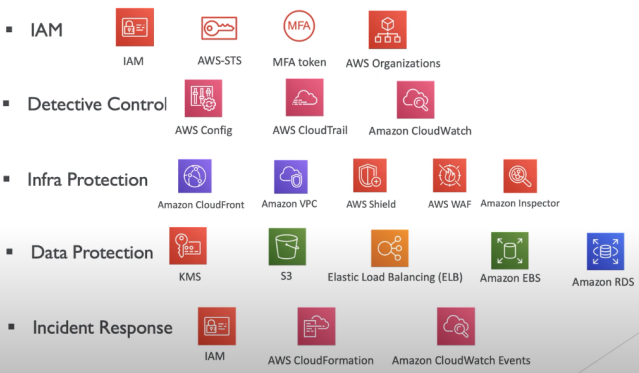
- Engloba a capacidade de uma carga de trabalho de desempenhar sua função pretendida de forma correta e consistente quando é esperado. Isso inclui a capacidade de operar e testar a carga de trabalho em todo o seu ciclo de vida.
- Design Principles
- Recuperar automaticamente da falha ( recuperação de desastre).
- Procedimentos de recuperação de teste.
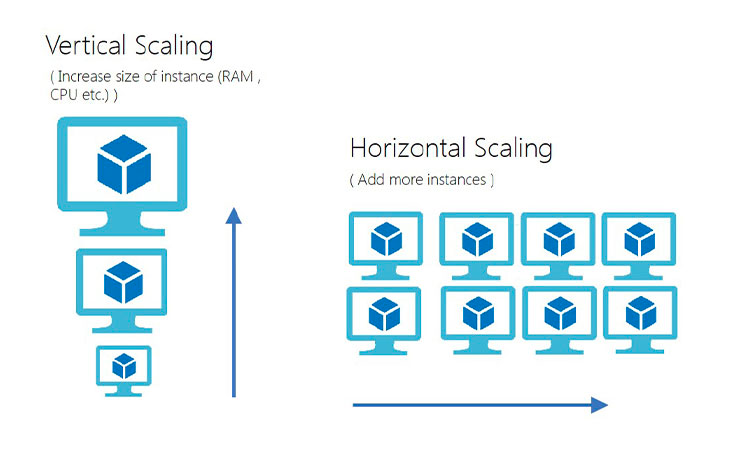
- Escale horizontalmente para aumentar a disponibilidade de carga de trabalho agregada.
- Pare de adivinhar a capacidade.
- Gerenciar mudanças com automações
- Inclui a capacidade de usar recursos de computação de forma eficiente para atender aos requisitos do sistema e manter essa eficiência conforme a demanda muda e as tecnologias evoluem.
- Design Principles
- Democratizar tecnologias avançadas.
- Torne-se global em minutos.
- Use arquiteturas sem servidor (serverless).
- Experimente com mais frequência.
- Considere simpatia mecânica (Conheças os serviços específicos da AWS, para cargas de trabalho especificas)
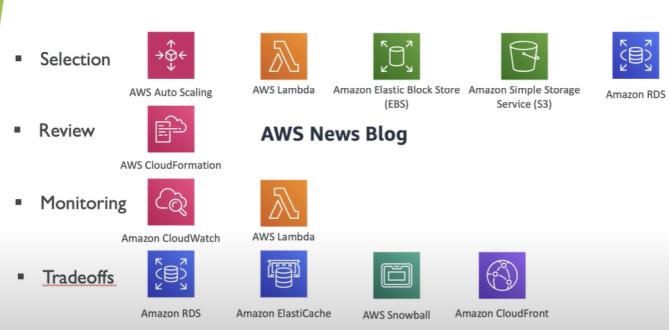
- Inclui a capacidade de executar sistemas para agregar valor ao negócio com o menor preço.
- Design Principles
- Implementar gerenciamento financeiro em nuvem (pague pelo que usa).
- Adote um modelo de consumo.
- Meça a eficiência geral.
- Analisar e atribuir despesas.
- Use serviços gerenciado pela AWS para reduzir custo.

Abaixo alguns case de como usar os recurso AWS no dia a dia.
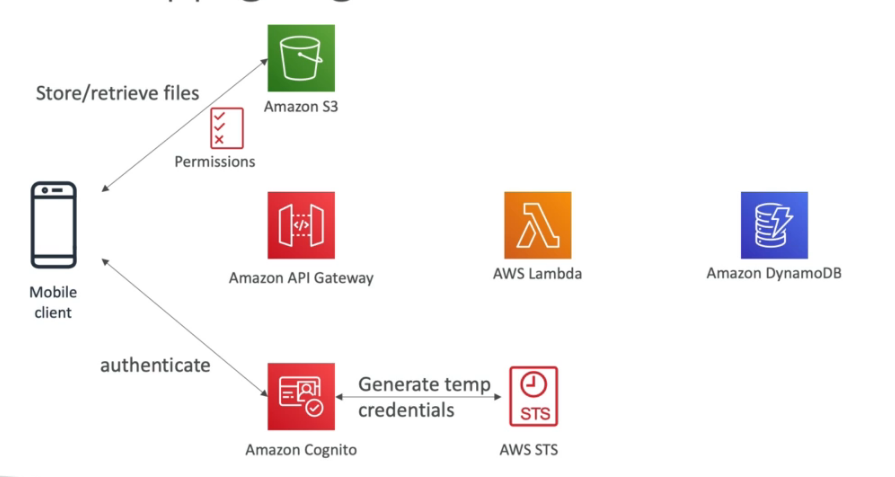
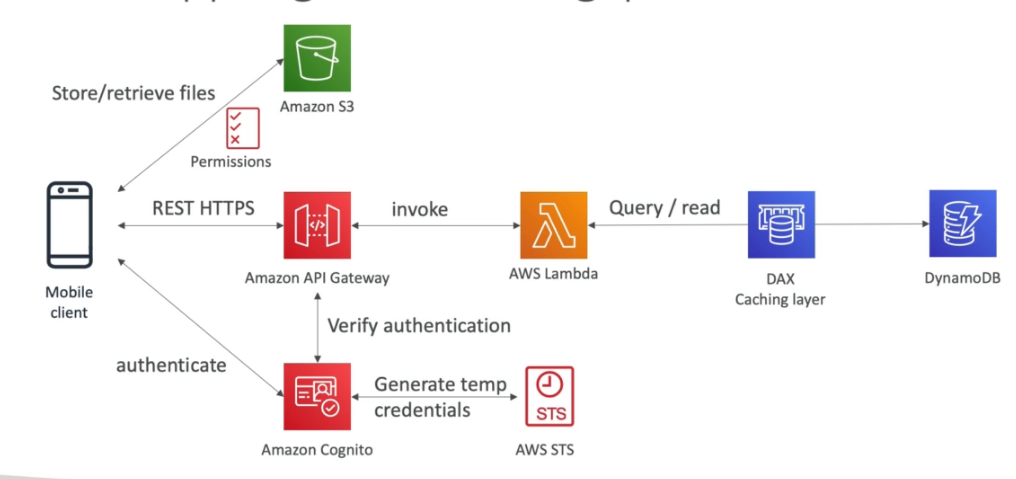
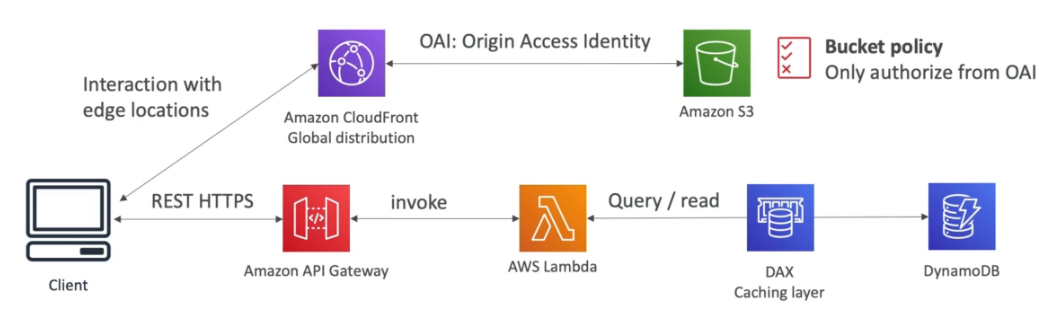
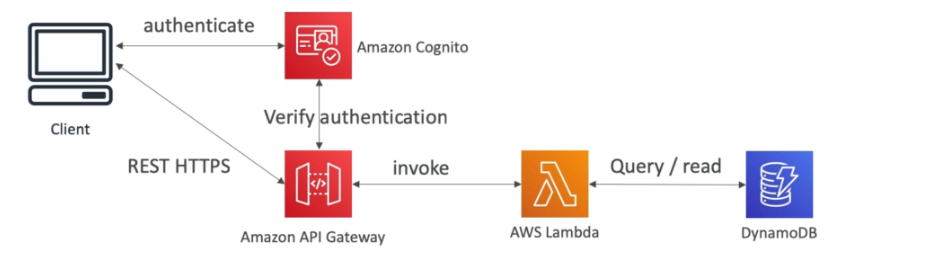
Usuário pode criar lista de tarefas e armazenar dados no S3, tem que ter autenticação.
Se cria uma API com API Gateway, que verifica as credenciais e dispara uma lambda que acessa o banco de dados.
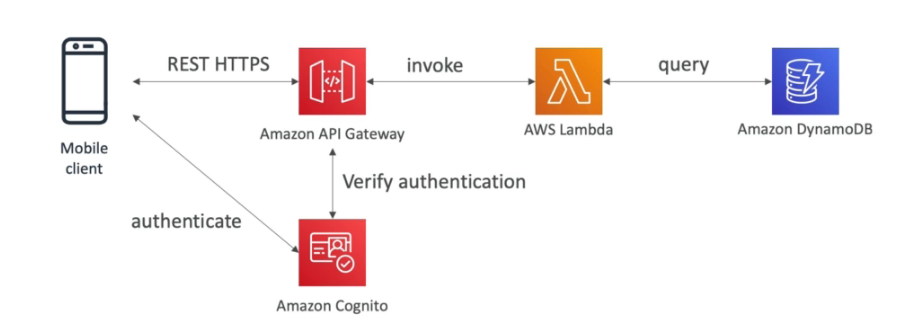
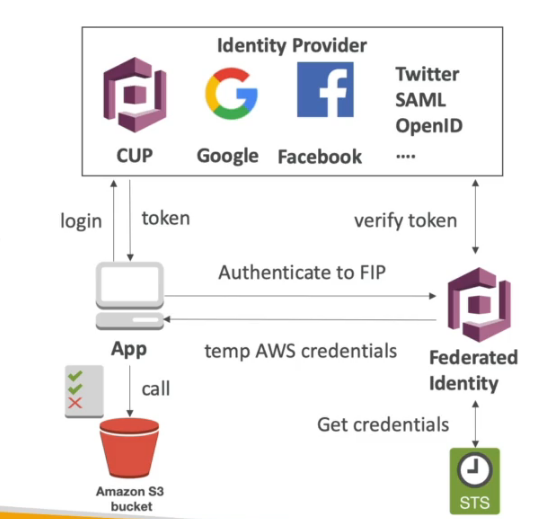
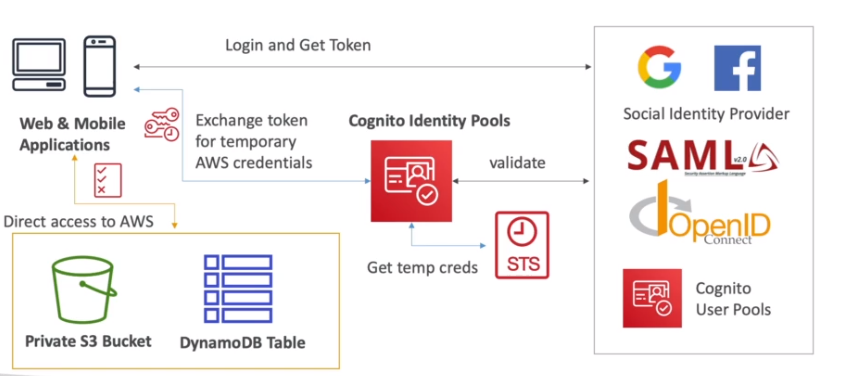
O Cognito via STS gera um token temporario para acessar o S3
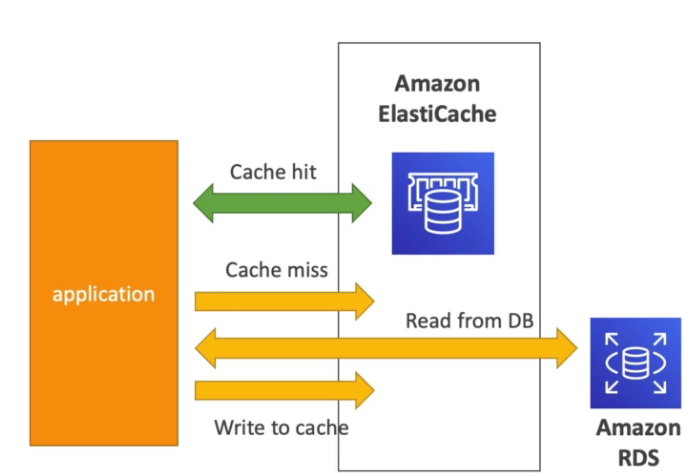
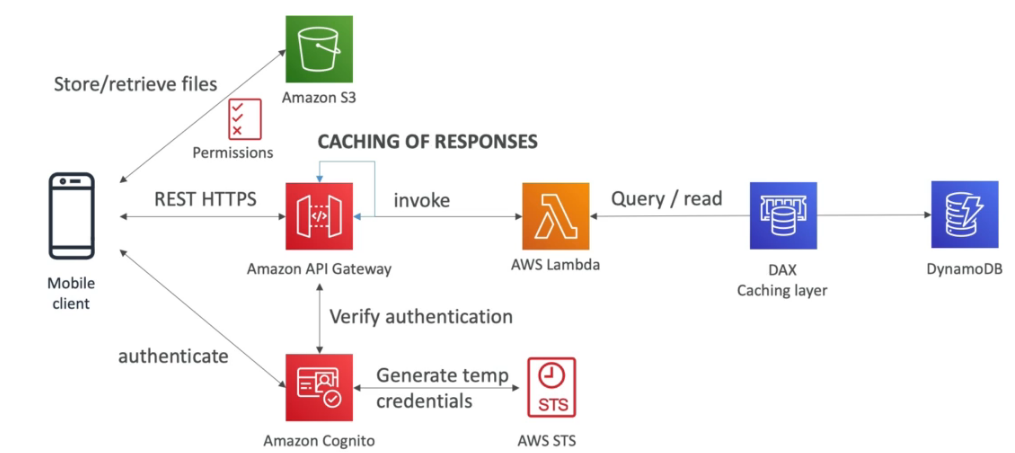
Quando temos muito acesso de leitura a arquivos staticos no DynamoDB, podemos adicionar o DAX, que vai realizar o cache dos dados mais acessados do banco, melhorando assim a leitura.
Cache de responses
Também seria possivel habilitar o caching no gateway, para cachear os requestes.
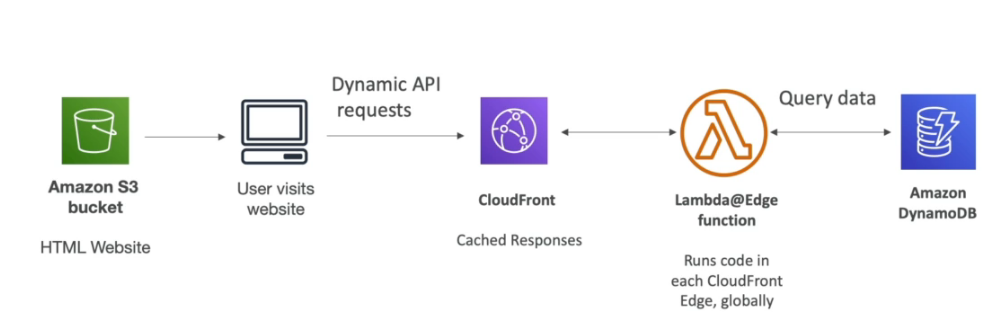
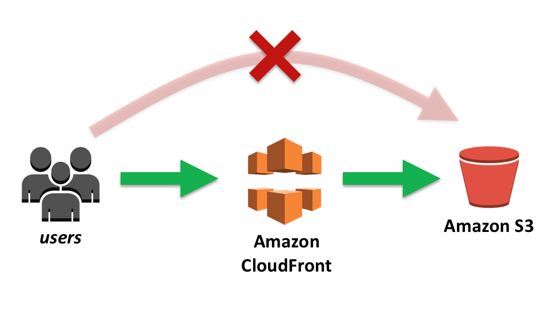
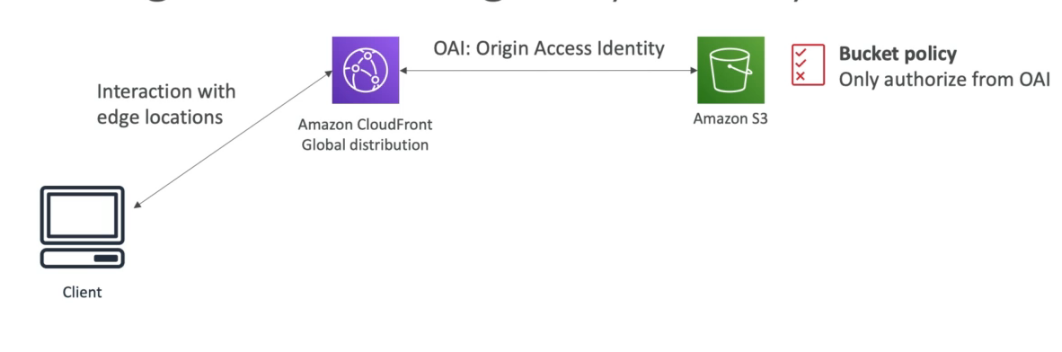
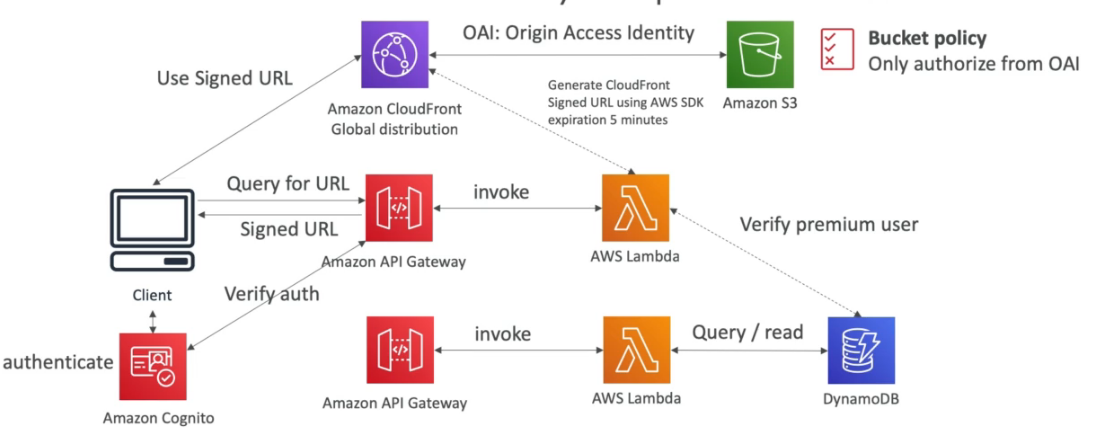
Coloca os arquivos num bucket, e usa o CDN para distribuir globalmente, e habilita OIA que só permitir o CDN acessar o Bucket incrementado a segurança.
Imagine que precise adicionar ações que recupere dados de um banco de dados, para fazer isso se cria um API com API Gateway que acessa uma lambda que acessa o banco conforme visto no case anterior.
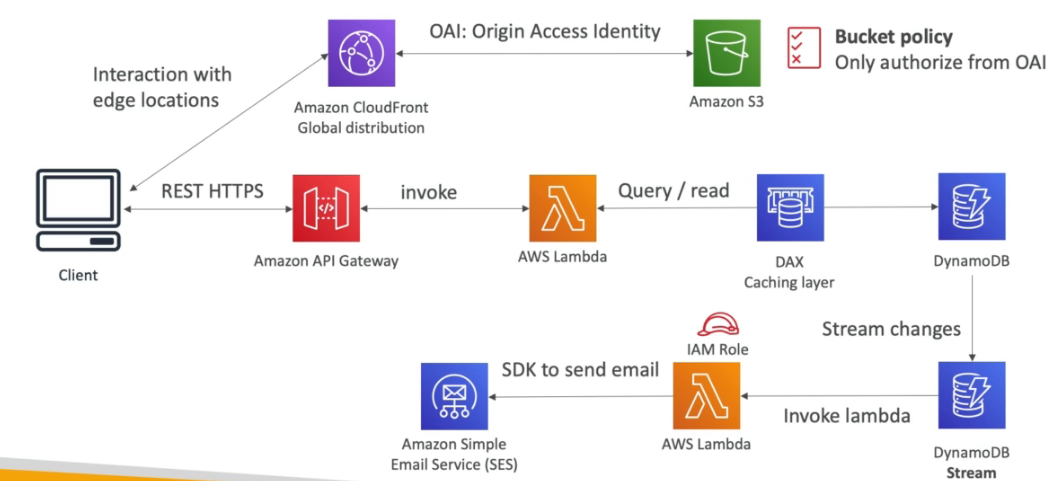
Quando um novo cadastro, o DynamoDB via DynamoDB Stream dispara uma Lambda que tem uma Role que permite acionar o SES (Amazon simple e-mail service) para enviar o e-mail.
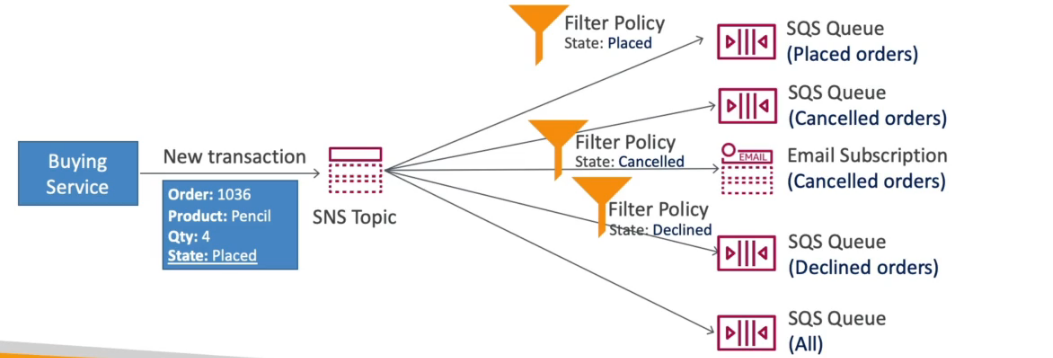
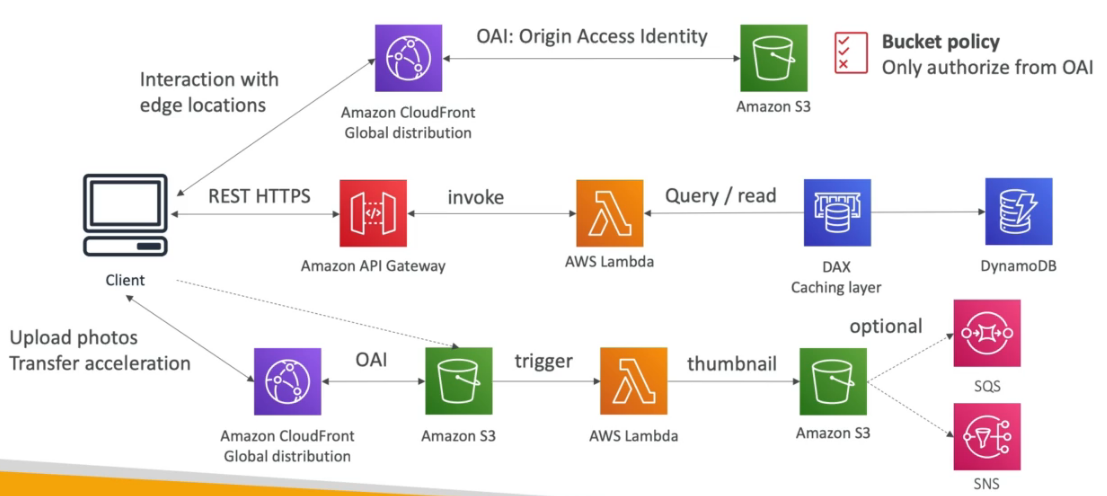
o Usuário vai subir os dados no bucket ou via cloud Front (CDN) que vai enviar via transfrer accelarion para o bucket use isso caso queira evitar acesso direto ao bucket, ao colocar a imagem no bucket isso vai dispara um lamdba para processar a imagem que depois pode ser armazenada em outro bucket, alem disso é possível notificar o cliente via SNS ou executar outro processamento postando numa fila SQS.
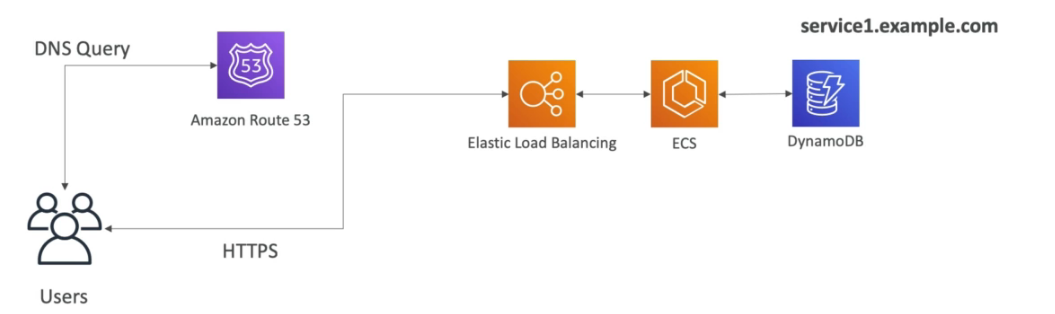
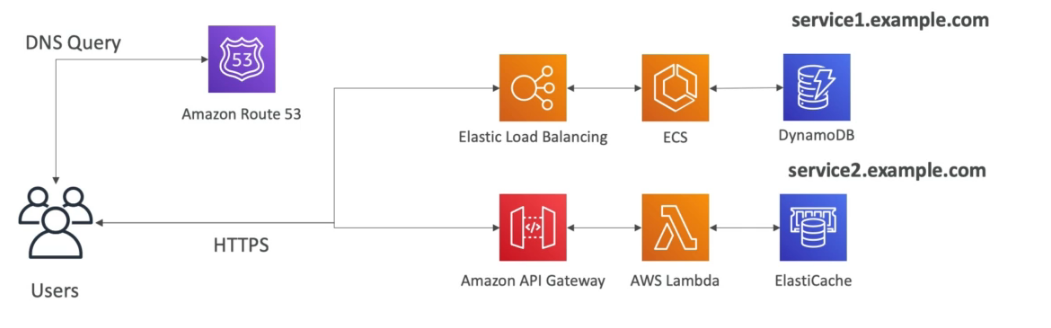
Tem se um conjunto de container no **ECS **ou EKS que acessam um banco e estão atrás de uma ELB e pode se usar o Route 53 par se dar um DNS Name tipo service1.example.com.
Tem se uma lambda que é disparada por requests a um API Gateway que pode consultar um banco de cache ou um **banco qualquer **e pode se usar o Route 53 par se dar um DNS Name tipo service2.example.com.
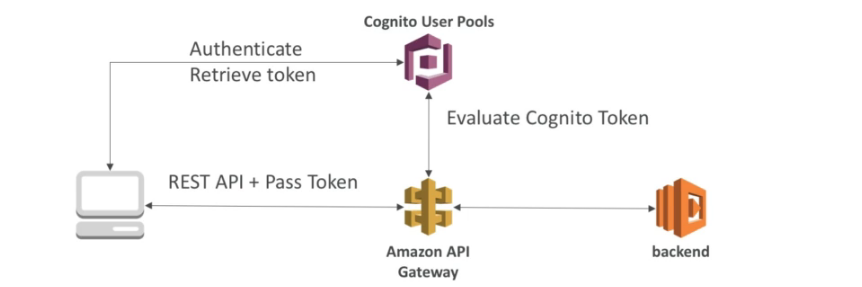
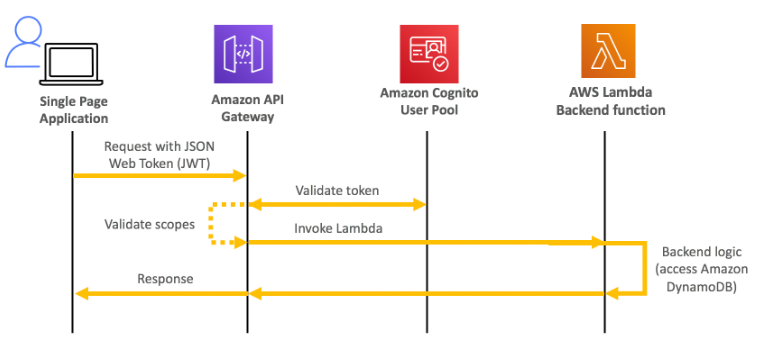
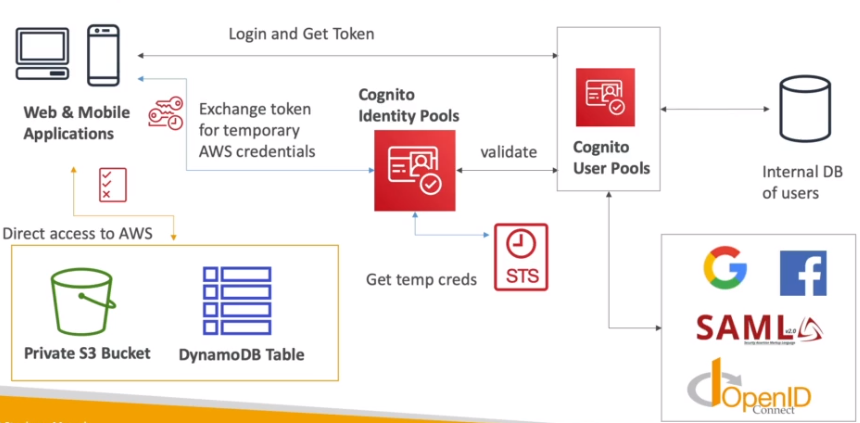
O usuário faz login usando o Cognito, e ao acessar ele bate num API Gateway que aciona um lambda que ira validar quais vídeos ele tem acesso base de dados.
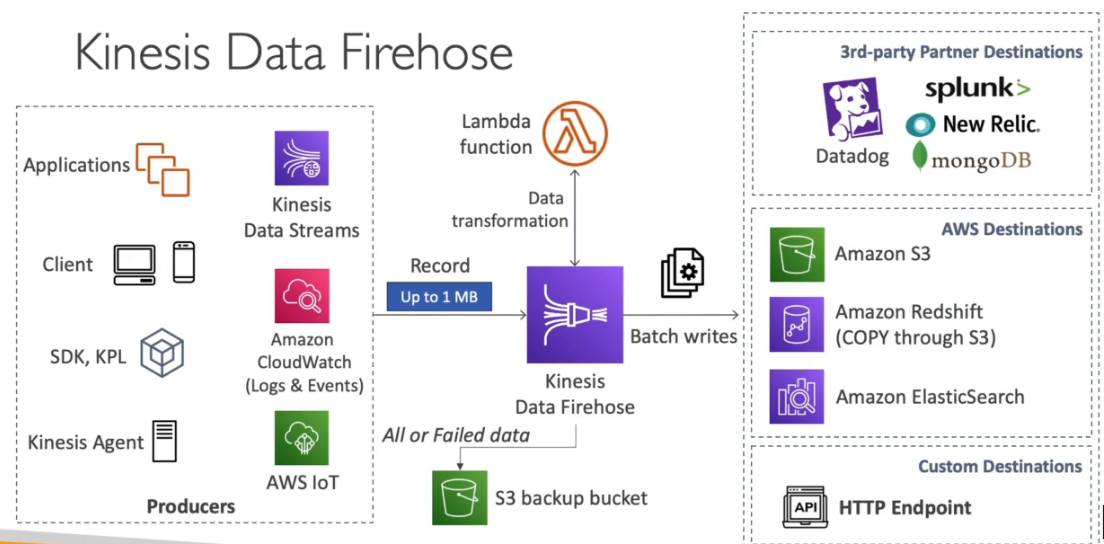
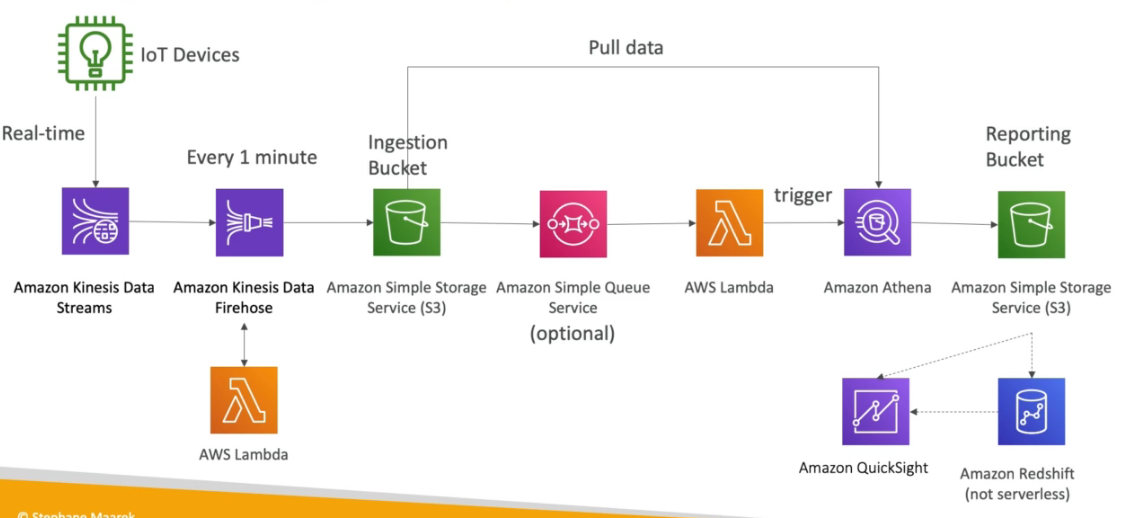
Utilizamos o Kinesis data stream para receber os dados em tempo real dos dispositivos, podemos acionar uma lambda para transformar esses dado e salvar num Bucket, podemos usar um topico SNS ou os próprios eventos do bucket para acionar uma outra lambda que acionaria o Athena para realizar queries nos dados coletados e salvando em outro bucket ou enviar para o Amazon QuickSight para geração de relatórios ou ate mesmo para o RedShilt para data warehouse.
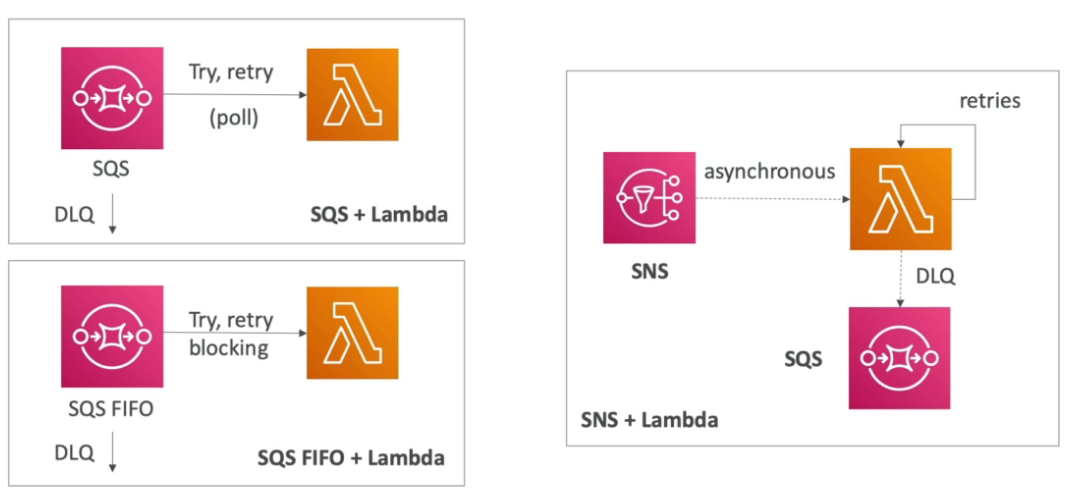
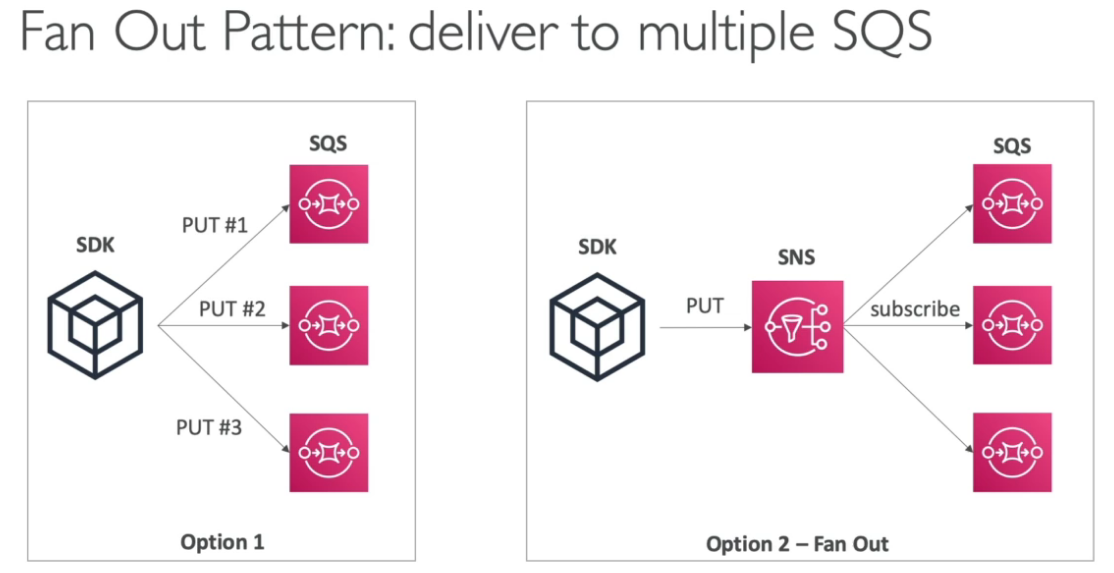
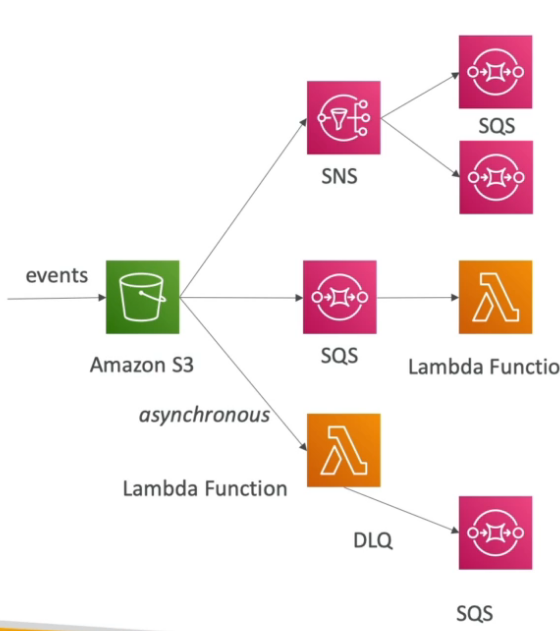
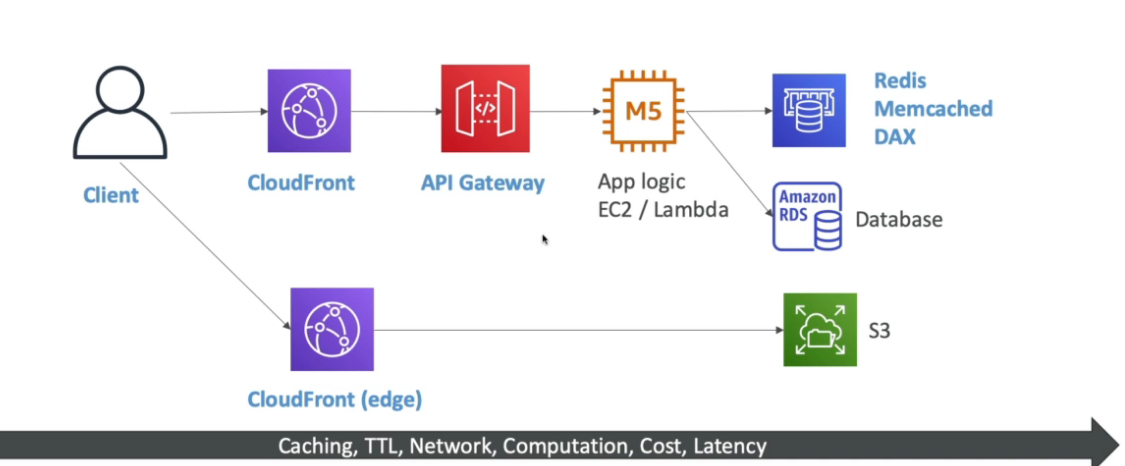
Paginas:
| Dominío | percentual |
|---|---|
| Domínio 1: Soluções de design de complexidade organizacional | 26% |
| Domínio 2: Design de novas soluções | 29% |
| Domínio 3: Melhoria contínua de soluções existentes | 25% |
| Domínio 4: Acelerar a migração e a modernização da carga de trabalho | 20% |
Tecnologias aws que podem vão cair na prova
- Computação
- Gerenciamento de custos
- Banco de dados
- Recuperação de desastres
- Alta disponibilidade
- Gerenciamento e governança
- Microsserviços e desacoplamento de componentes
- Migração e transferência de dados
- Redes, conectividade e entrega de conteúdo
- Segurança
- Princípios de design sem servidor
- Armazenamento
Serviços abordados






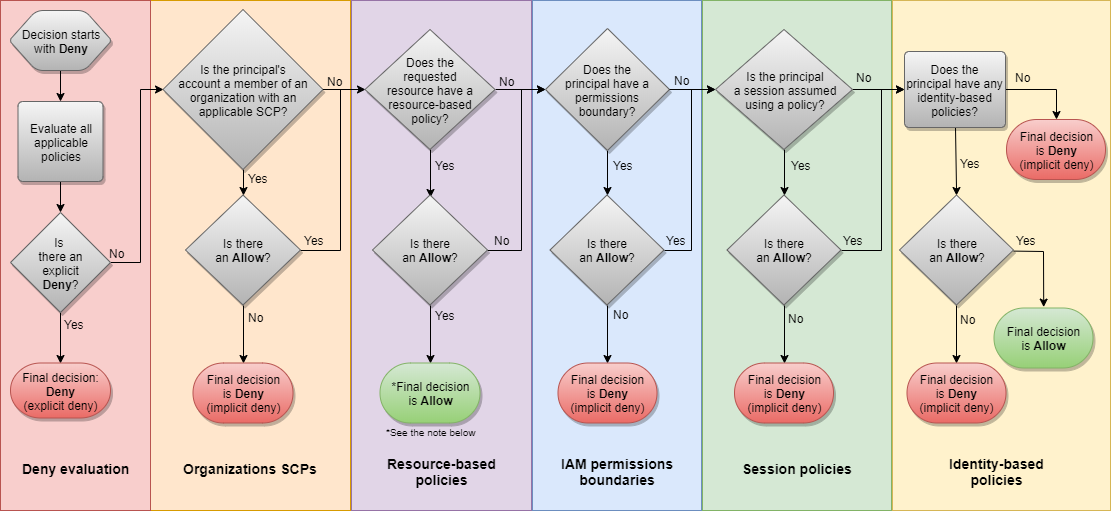
 Lógica da avaliação de política
Lógica da avaliação de política

- Há dois via sofware (dispositivo MFA virtual, Chave de chegurança U2F (ex: YUbiKey))
- Há uma opção de Hardware (ex: token Gemalto)Basic recomendations














Forma de se usar o ADSF (active directory na AWS)












































 Como previnir:
Como previnir:




















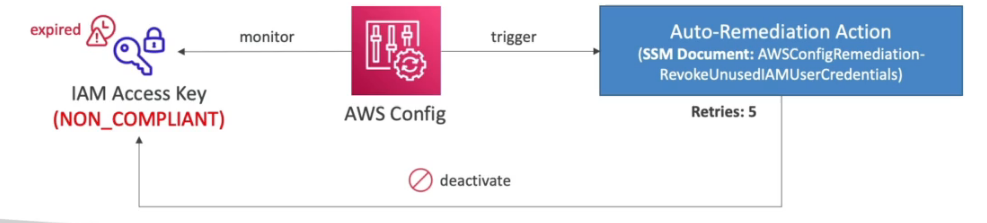
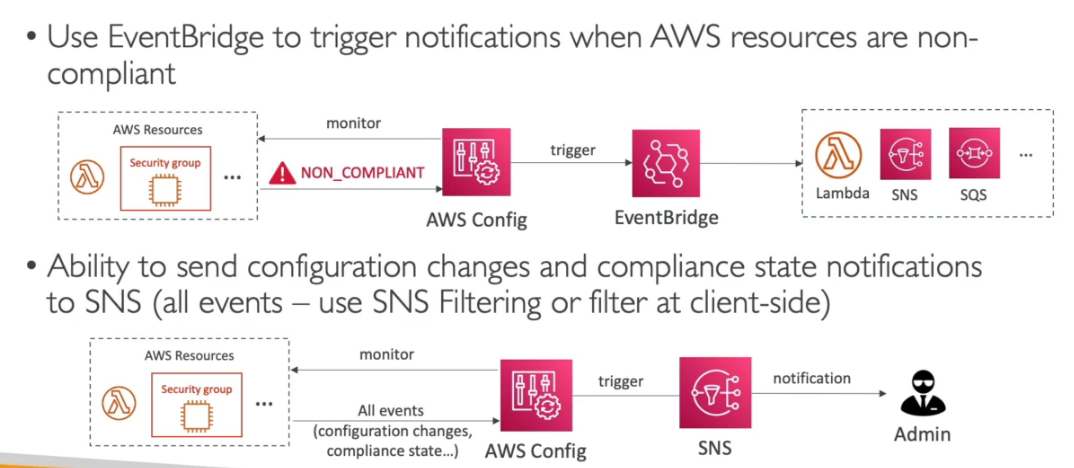
 Perguntas que tem como resposta AWS Config:
Perguntas que tem como resposta AWS Config:

permite usar condições para liberar acesso.




Resource police restritas para a organização








Nomenclatura dos tipos de instâncias:
exemplo: m5.2xlarge


Processos executados pelo auto scaling



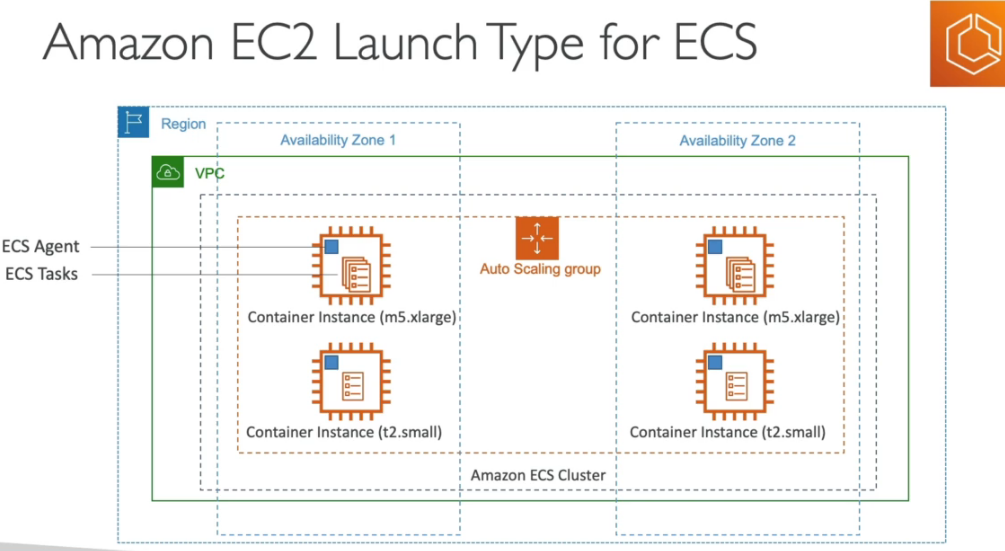
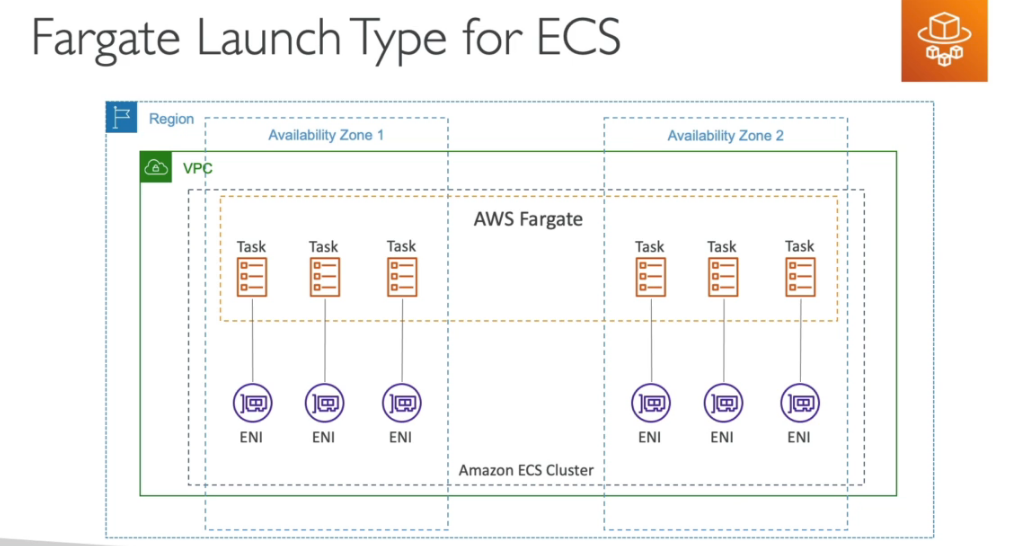
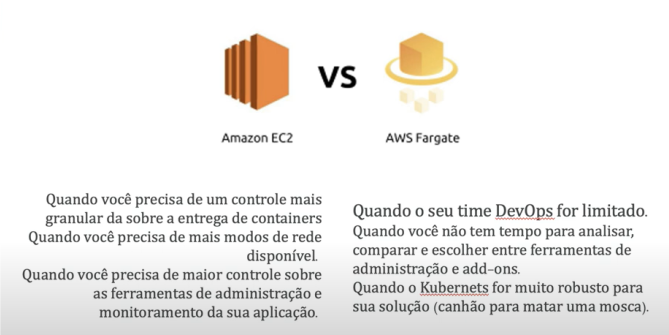
 EC2 x Fargate
EC2 x Fargate














 Request Routing Algoritimo
Request Routing Algoritimo















# para verificar use o comando para verificar os valores retornado pelos dns
nslookup <url>
dig <url> São políticas de redirecionamento que é possível configurar no route 53.


Pode se configurar health checks para monitora a disponibilidade e a saúde da aplicação.







Serviço que melhora a disponibilidade de um serviço usando os ponto de presença, melhora a disponibilidade em cerca de 60%.





 os tipos io1 / io2 permitem conectar o mesmo em mais de uma instância, isso é usado em aplicação de alta disponibilidade, ex Cassandra …
os tipos io1 / io2 permitem conectar o mesmo em mais de uma instância, isso é usado em aplicação de alta disponibilidade, ex Cassandra …










 Recomendação de leitura: Analise as classes de armazenamento do Amazon S3, do padrão ao Glacier
Recomendação de leitura: Analise as classes de armazenamento do Amazon S3, do padrão ao Glacier




























 Ou separados
Ou separados
 Usos:
Usos:
















 Serviço de banco de dados relacional da AWS.
Serviço de banco de dados relacional da AWS.














Quando se cria um banco no RDS se passa quando ele deve ter, com essa funcionalidade ele aumenta o tamanho da banco ao se aproximar de limite de uso do espaço.




























































Permite criar eventos, ous seja ações predefinidas ou agendadas que podem disparar alguns serviços AWS (regras que define ações).

























































Porta que vc deve conhecer :
- 22 -> SSH
- 21 -> FTP
- 22 -> SFTP
- 80 -> HTTP — access unsecured websites
- 443 -> HTTPS — access secured websites
- 3389 -> RDP (Remote Desktop Protocol for Windows instance)






























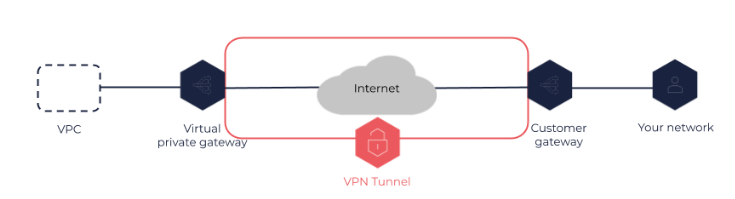
 Client VPN - Permite configurar uma VPN para que os usuários possam conectar via por exemplo (OpenVPN)
Client VPN - Permite configurar uma VPN para que os usuários possam conectar via por exemplo (OpenVPN)






















Data Exchange Data Pipeline Lake Formation AppFlow Managed Blockchain App Runner Lightsail Wavelength EKS Distro EKS Anywhere Keyspaces (for Apache Cassandra) Cloud9 CodeArtifact CodeStar Amplify Pinpoint Internet das Coisas:
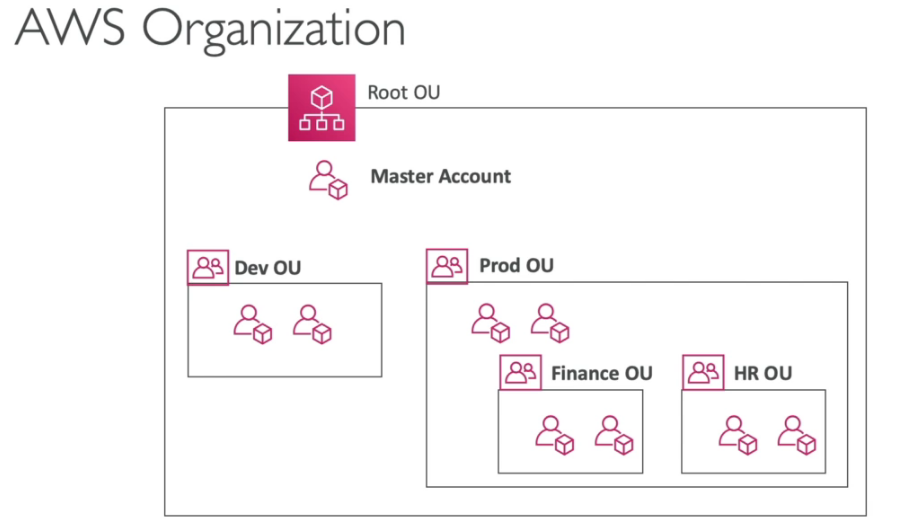
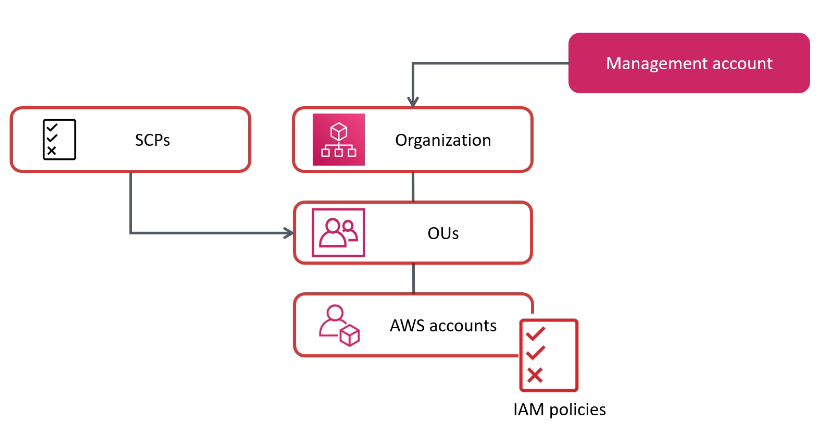
Há um limite de 20 contas por organização.
Role OrganizationAccountAccessRole da permissão de admin dentro das contas da organização
Permite compartilhar instancias reservadas com as contas

Dentro do IAM temos:
IAM Polices - Políticas de acesso (permissões).
Access Advisor - Permite ver as permissões e a ultima vez que foi usada.
Access Analize
Permite analisar quais recursos são compartilhada com entidades externas, ex buckets.
Permite definir uma Zona de confiança com as contas ou as organizações que confia. O que estiver fora dessa Zona terá o acesso sinalizado
Pode ler logs de do CloudTrail e gerar polices com permissões granuladas.
Polices com variaveis e tags



Quando se criar usuário ou Roles e possível dar permissão genéricas, tipo de administrador , e setar um limite para essas permissões, exemplo o cara é administrado apenas nos recursos do S3.
Suportado apenas por usuários e roles (Não grupos).
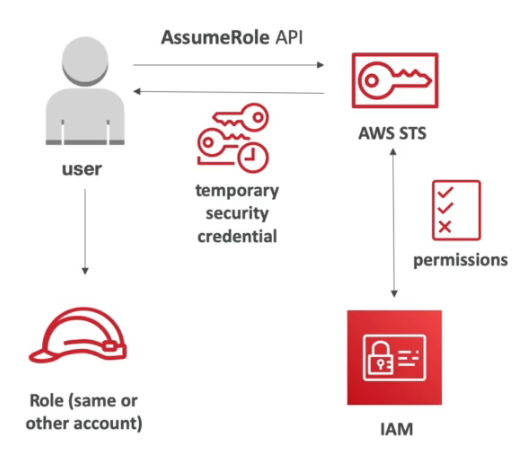
Serviço de geração token para acesso validos de 15 minutos a 12 horas.
Fornece uma api chamada assumeRole, que é usada para assumir outras roles.
Cria se uma police do tipo Trust Police com a ação assume role, e com a principal a que se confia.

Lembrando que quando assuminos uma Role, perdemos nossos acessos anteriores.
Permite revogar o acesso a role adicionando um novo bloco de statement ou usando o AWSRevokeOlderSessions.
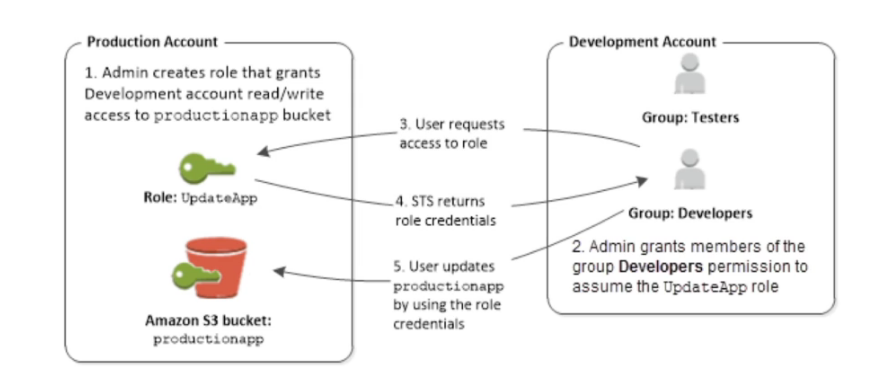
Usando em cross acount

Session Tags
APIs importantes

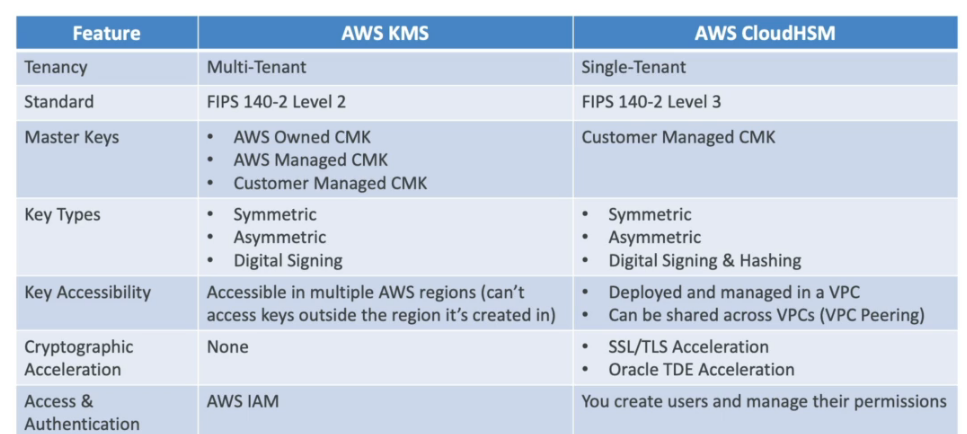
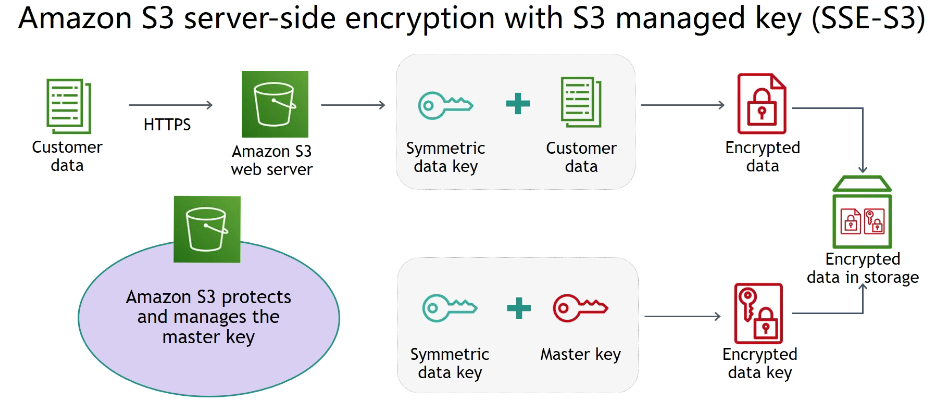
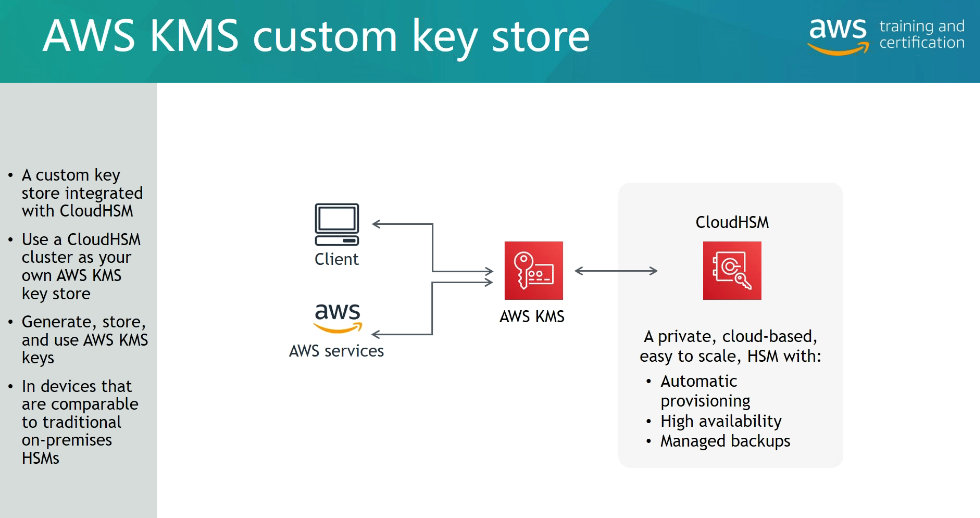
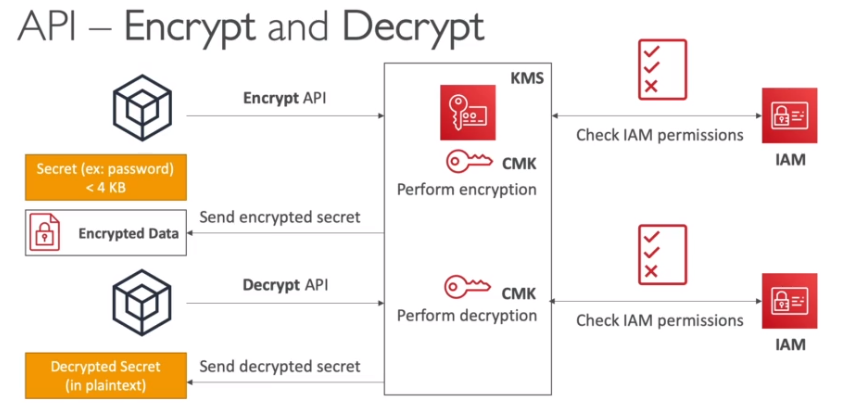
SSE-S3 - Criptografa os objetos do S3 usando chave gerenciada pela AWS (AES-256).
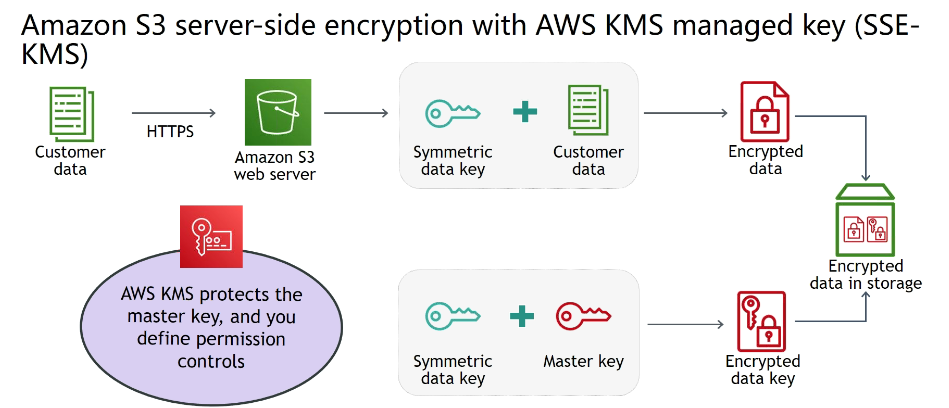
SSE-KMS - Criptografa os objetos do S3 usando chaves criadas no KMS.
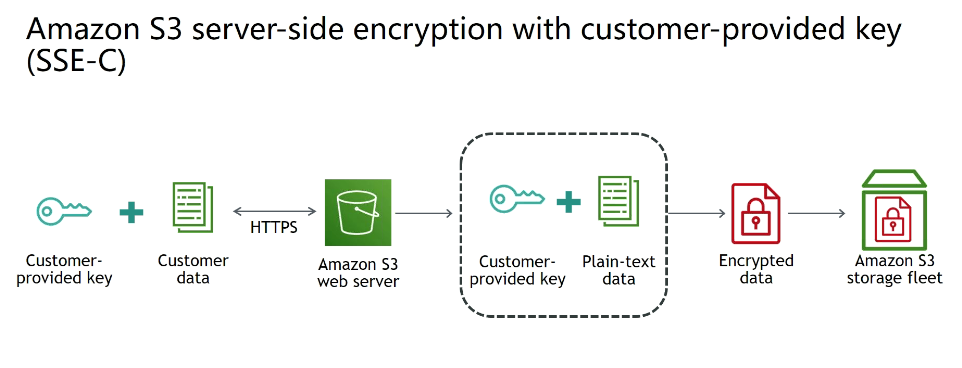
SSE-C - Criptografa os objetos do S3 usando a chave gerenciada pelo usuário, quando se usa por exemplo o Cloud HSM
Criptografia Client-Side - Quando o usuário criptografa os dados antes de enviar ao S#.





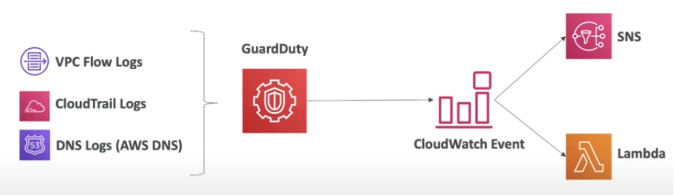
Serviço de inteligência artificial para detectar anomalias na sua conta.
É um serviço regional.
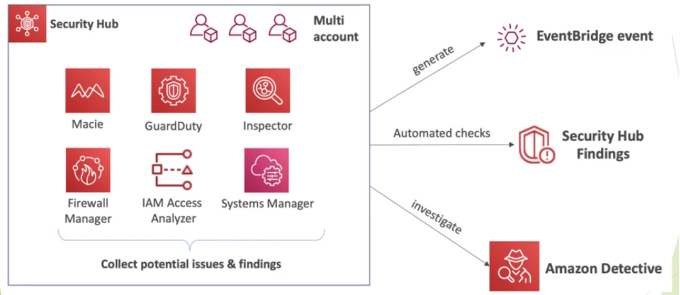
é um serviço inteligente de detecção de ameaças que monitora continuamente suas contas da AWS, instâncias do Amazon Elastic Compute Cloud (EC2), clusters do Amazon Elastic Kubernetes Service (EKS) e dados armazenados no Amazon Simple Storage Service (S3) para atividades maliciosas sem o uso de software ou agentes de segurança.
Se for detectada atividade maliciosa em potencial, como comportamento anômalo, exfiltração de credenciais ou comunicação de infraestrutura de comando e controle (C2), o GuardDuty gera descobertas de segurança detalhadas que podem ser usadas para visibilidade da segurança e assistência na correção.
O GuardDuty pode monitorar atividades de reconhecimento por um invasor, como atividade incomum de API, verificação de porta intra-VPC, padrões incomuns de solicitações de login com falha ou sondagem de porta desbloqueada de um IP ruim conhecido.
EC2 Nitro - nova tecnologia de virtualização adotada pela AWS,
EC2 Graviton

Entregam o melhor performance em relação ao custo. Sendo 46 % mais em contas em comparação com a 5 geração.
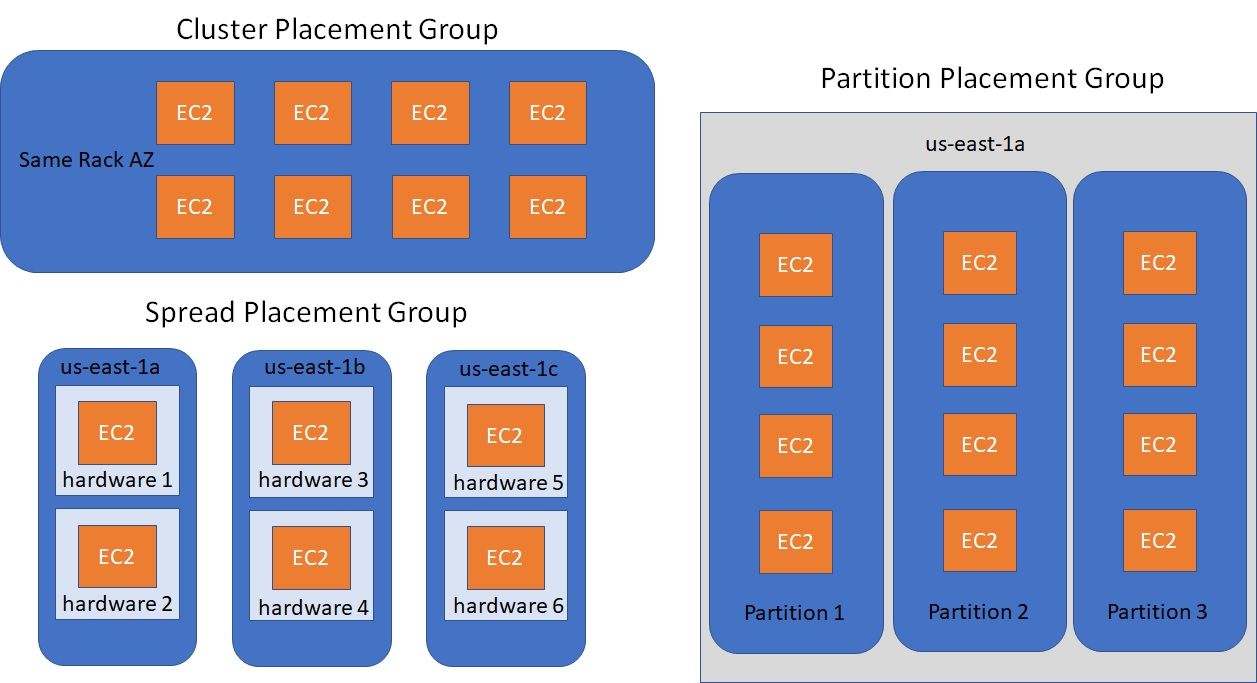
Placement Groups - Grupos de Posicionamento
Permite decide a estratégia posicionamento das instâncias EC2. ou seja onde vai ficar as instâncias de vai ser:
Cluster - Todas ais instâncias ficam juntas, tem baixa latência, mas ficam numa única AZ. (alta performance, mas tem um alto risco).
Spread - (espalhadas) As instâncias ficar espalhadas em servidores em diferentes AZ, com uma máximo de 7 instâncias por grupo por AZ. Usados em aplicações criticas.
Partition - Similar ao Spread, mas as instâncias ficam espalhadas em diferentes partições (conjunto de Racks) numa AZ. Pode escalar para centenas de instâncias por grupo, usadas com o Hadoop, Kafka, Cassandra.
Metricas



Serviços que ajudam ter alta performance na AWS:
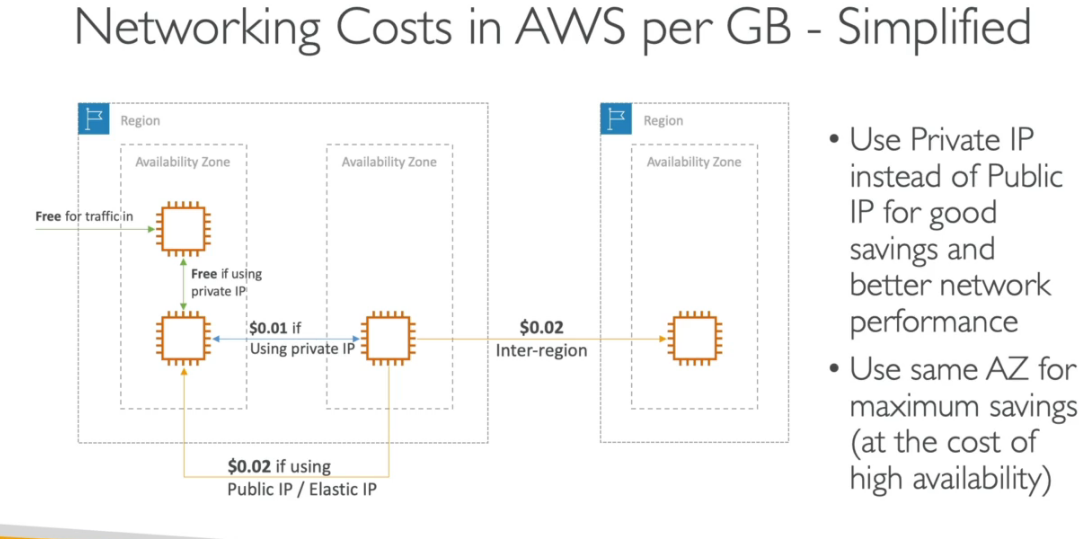
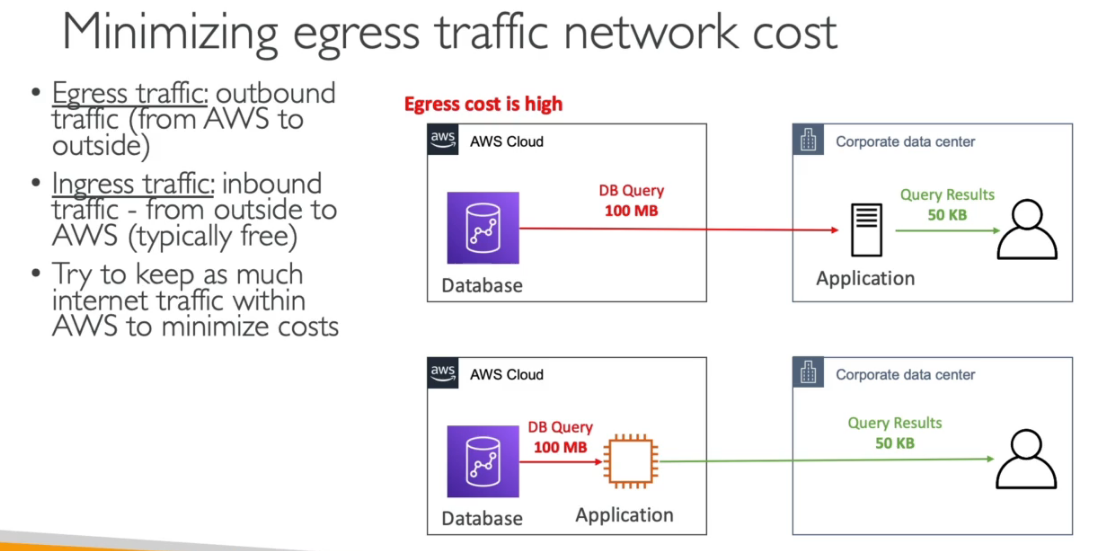
Transferência de dados
Computação
Armazenamento
Automação e Orquestração
AWS Batch - para trabalhar com jobs e agendamentos.
AWS ParallelCluster



Custo de $0,1 por hora por cluster kubernete ($75 por mês) mais os recurso (EC2, EBS).
Tipos dos nodes
Volumes
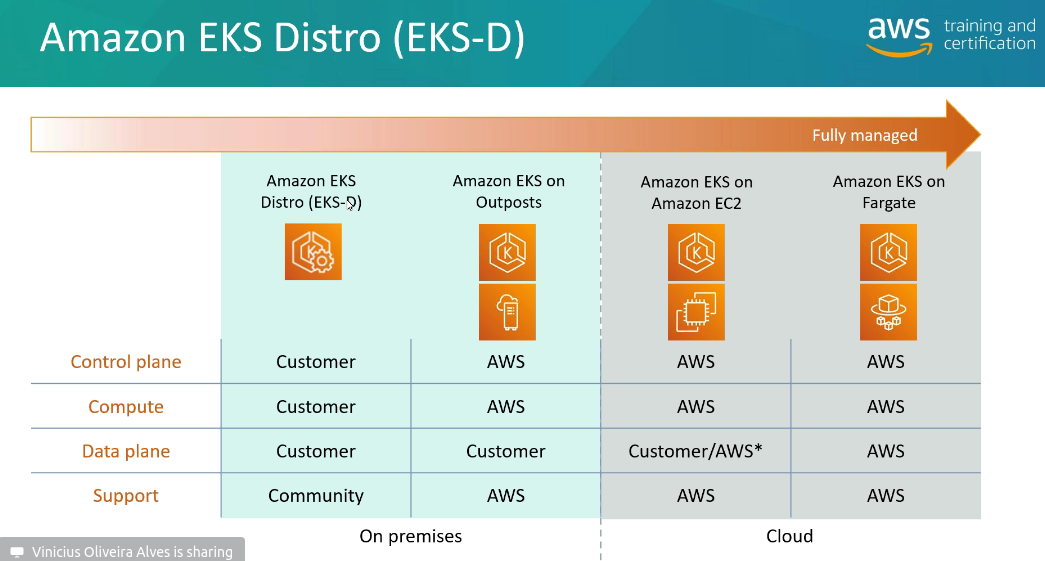
É possivel rodar o EKS no On-primeses usando o EKS AnyWhere
Tem de 128 MB ate 10 GB de memoria que pode ser usado.
Tem escopo regional.
Pague por milissegundo usado para executar o código.
Tempo de execução de ate 15 minutos.
Cobrado de 100 em 100 milissegundos de uso.
Faz escalonamento horizontal e pode ter ate 999 execução simultâneas.
Triggers
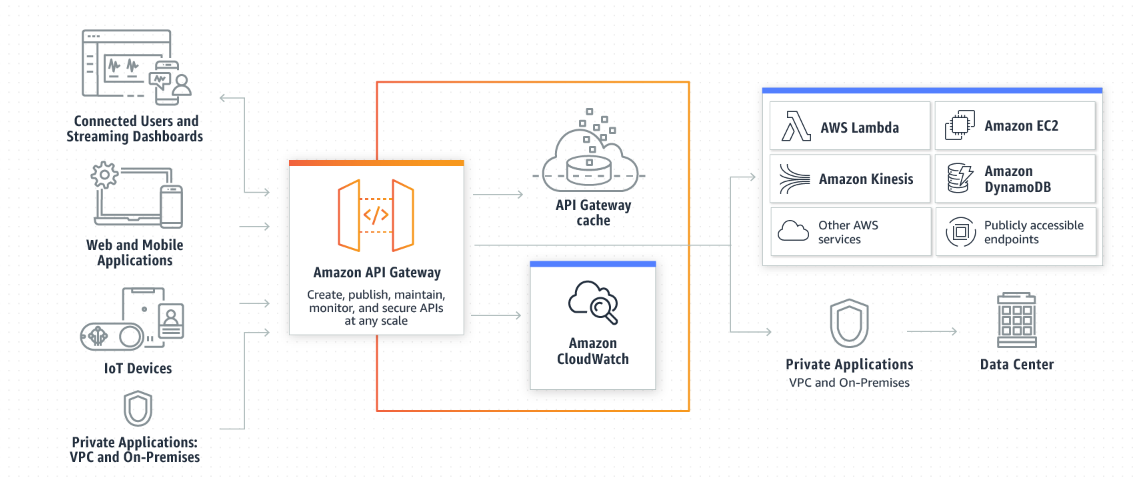
API Gateway
Kinisis
DynamoDB Data Streams
S3 events
EventBridge
SNS, SQS
Cloud Watch Logs
AWS Cognito
Limitações
Lambdas@Edge
É possível executar Lambdas em ponto de presenças, para auxiliar itens relacionados ao CDN , Route 53 ….

Limitações
LOGs
Possivel enviar os logs para o Cloud Watch com os niveis ERRO e INFO
Pode logar o request e response completos.
Pode enviar os logs de acessos de forma customizada
Pode ser enviados diretamente para o Kinesis Data Firehose como alternativa.
Metricas
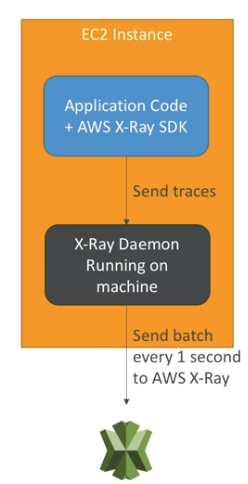
X-Ray
Pode se setar TTL nos Records para controlar o tempo de vida. Ele é obrigatório para todos os tipos de records exceto para o tipo Alias
São políticas de redirecionamento que é possível configurar no route 53.

Pode se configurar health checks para monitora a disponibilidade e a saúde da aplicação.

Hybrid DNS e Resolvers
Hybrid DNS
Resolvers
O Resolver endpoint é um ponto de extremidade em sua VPC, que permite que os recursos em sua VPC resolvam nomes de domínio em outros VPCs.
Podem ser associados a uma ou mais VPC na mesma região.
Cada endpoint suporta ate 10000 queries por segundos por IP.
São divididos em :
Inbound endpoint

Outbound endpoint

Serviço que melhora a disponibilidade de um serviço usando os ponto de presença, melhora a disponibilidade em cerca de 60%.



Oss tipos io1 / io2 permitem conectar o mesmo em mais de uma instância, isso é usado em aplicação de alta disponibilidade, ex Cassandra .
Data Lifecycle Manager
Automatiza a criação, retenção e deleção de snapshot EBS e AMIs.
Qual a diferença dele para o AWS Backup.
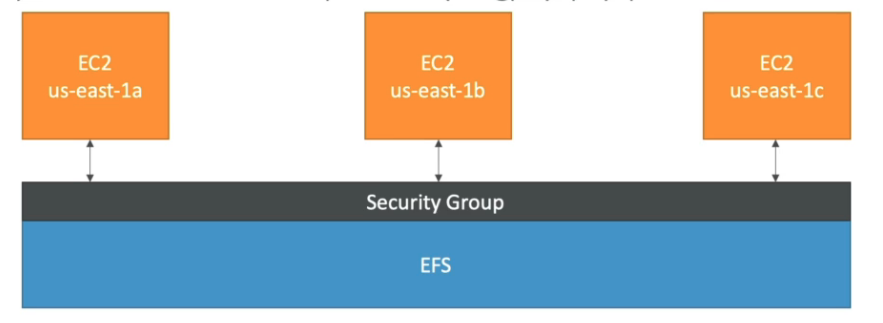
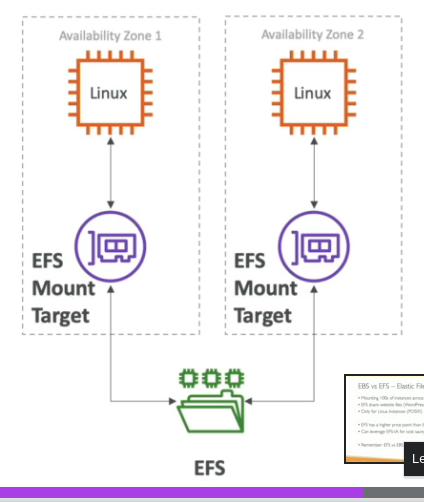
Usa um security group para se linkar as instâncias.
Usados apenas com Linux (AMI), não compatível com Windows.
Pode se usar o AWS Access Point para restringir o acesso aos usuários.
Suporta milhares de clientes, e pode ter ate 10gb+ de thoughput .
O tipo de performance pode ser definido na criação podendo ser:
Throughput mode
Storages Ties (lifecycle management feature - Move os arquivos após 30 dias)





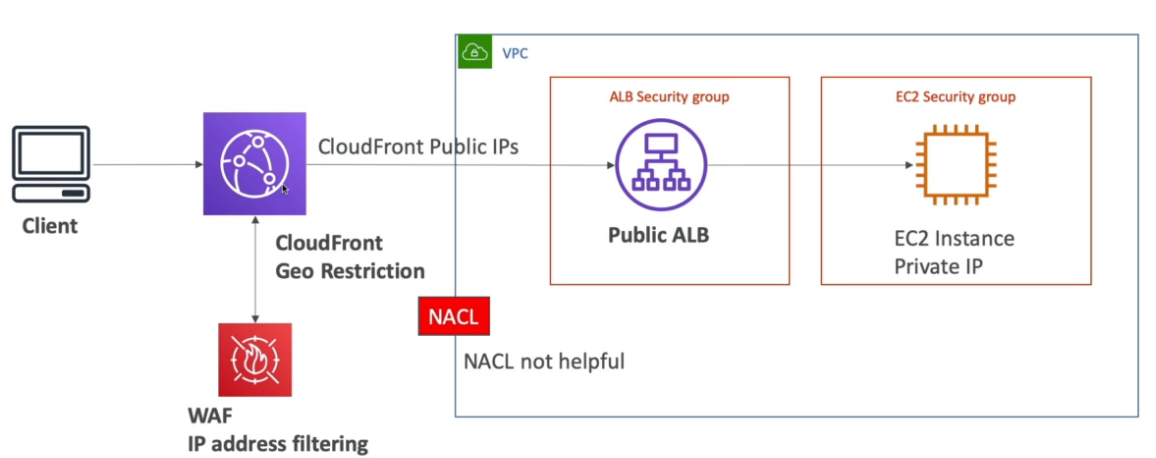
Possível bloquear um pais de acessar via Geo Restriction.
CloudFront Signed URL - são comummente usados para distribuir conteúdo privado por meio da geração dinâmica de CloudFront Signed URL (uma para cada conteúdo).
CloudFront Signed cookies - são comummente usados para distribuir vários conteúdo privados com uma única URL.
Diferença entre CloudFront Signed URL e S3 Signed URL

Pode se usar o Origin Access Identity (OAI) para que apenas CDN acesse o bucket e não redirecione para o bucket. Nesse caso o bucket pode continuar privado e acessando pelo CDN vai aparecer os arquivos, pois eles são acessado por um “usuário cdn” liberado.




Tamanho máximo de objeto (registro aceito 400 KB), para objetos maiores se armazena no S3 e guarda a referencia no DynamoDB.
Permite usar o DAX (DynamoDB Accelarator) para melhorar o IO para milissegundos.
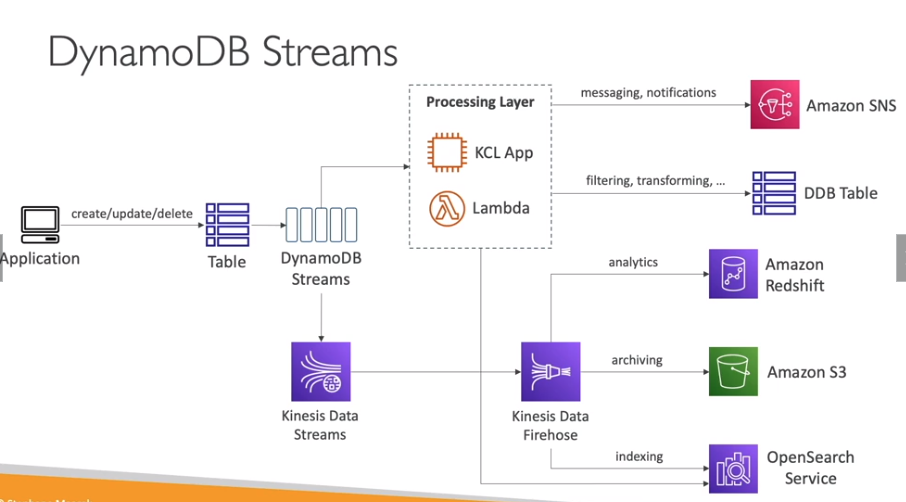
Permite criar tabela global, que replica os dados em diferentes regiões (Brasil, EUA, Europa por exemplo) para isso é necessário ativar o DynamoDB Streams.
Suporta ACID (Transações sobre múltiplas tabelas)
Devo usar DAX ou ElasticCache
RDS para Lamba


Aurora




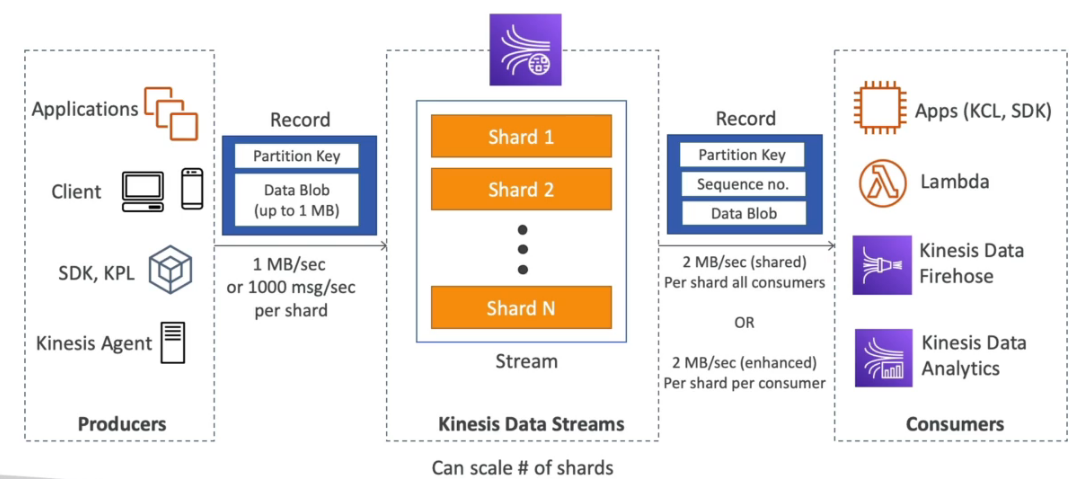
Consumers
Producer




Caso precise executar com alta performance (HPA) pode se usar o modo Multi Node


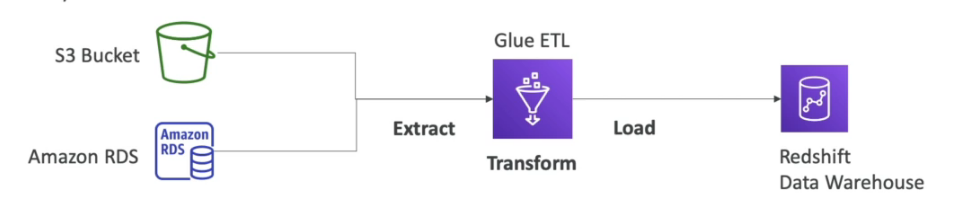
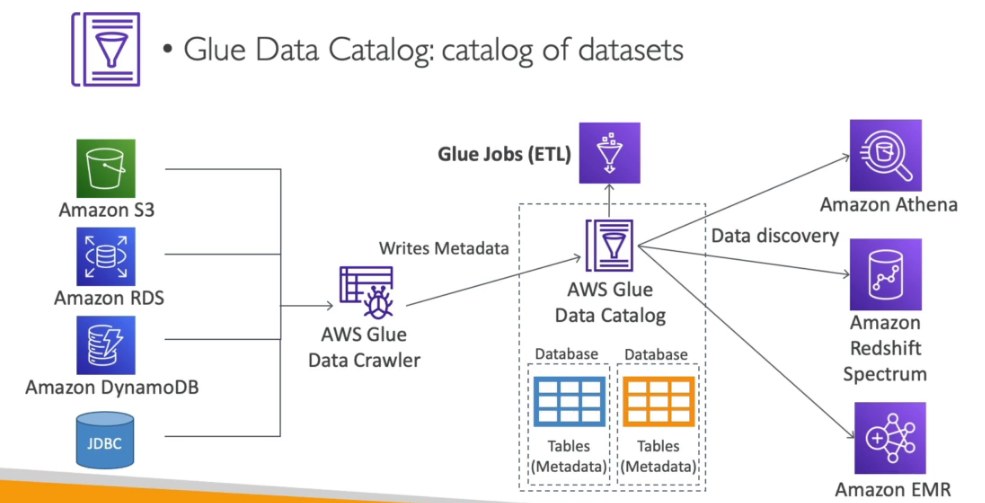
Serviço gerenciado de ETL (extract, tranform, and Load).
Serviço Serverless, possui 3 serviços:



Serviço usado para ver, entender e gerenciar os gastos (com varias granularidade mês, ano , dia).
Quando devo usar o AWS Compute Optimizer e quando devo usar o AWS Cost Explorer?
AWS Cost Explorer se quiser identificar instâncias do EC2 subutilizadas e quiser entender o impacto potencial em sua fatura.
AWS Compute Optimizer se quiser ver as recomendações de tipo de instância além do downsizing. Faz o uso de aprendizado de máquina para identificar tipos de carga de trabalho e escolher automaticamente a metodologia de recomendação específica de carga de trabalho para eles.

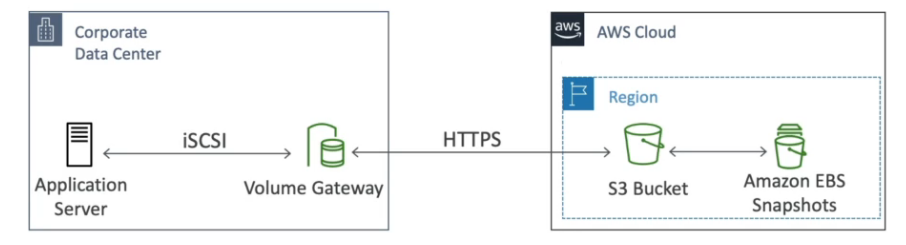
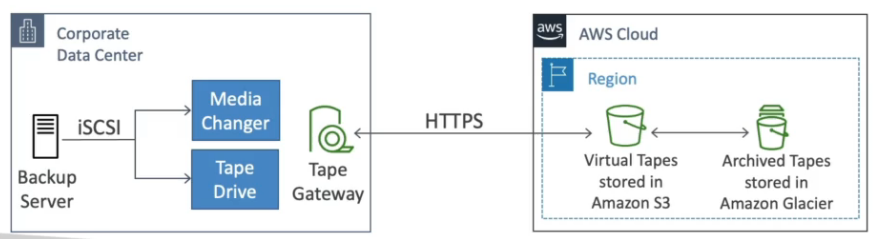
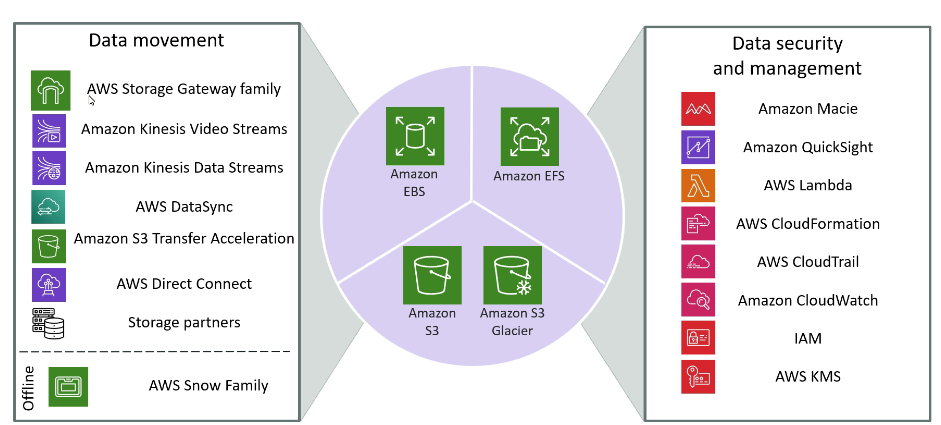
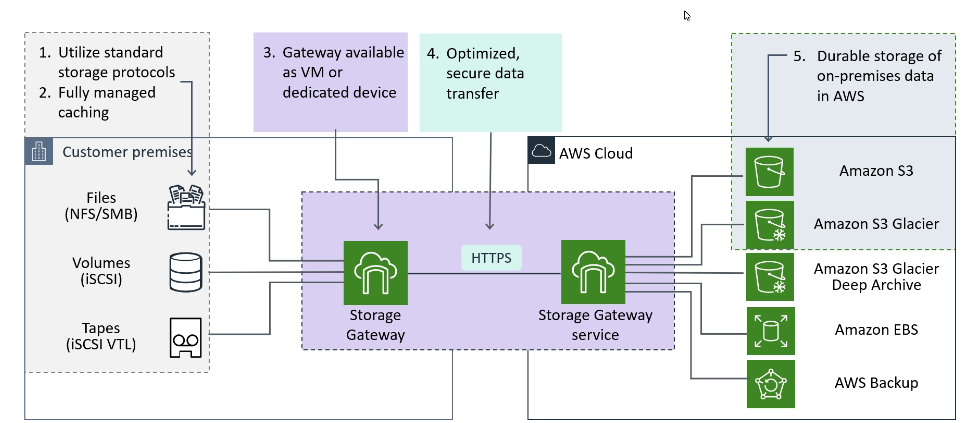
Uso:
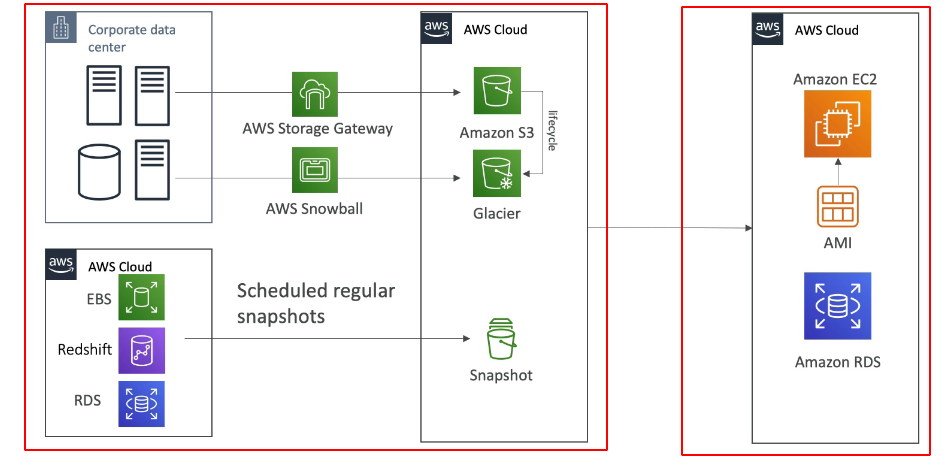
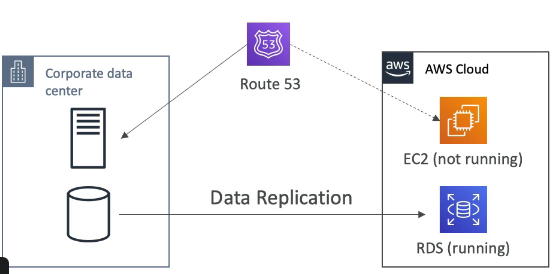
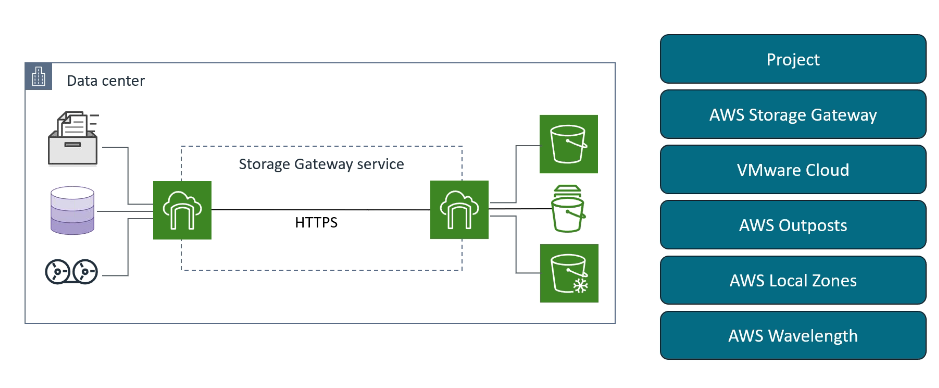
Arquitetura com Storage Gateway



Termos importante




Tipos:
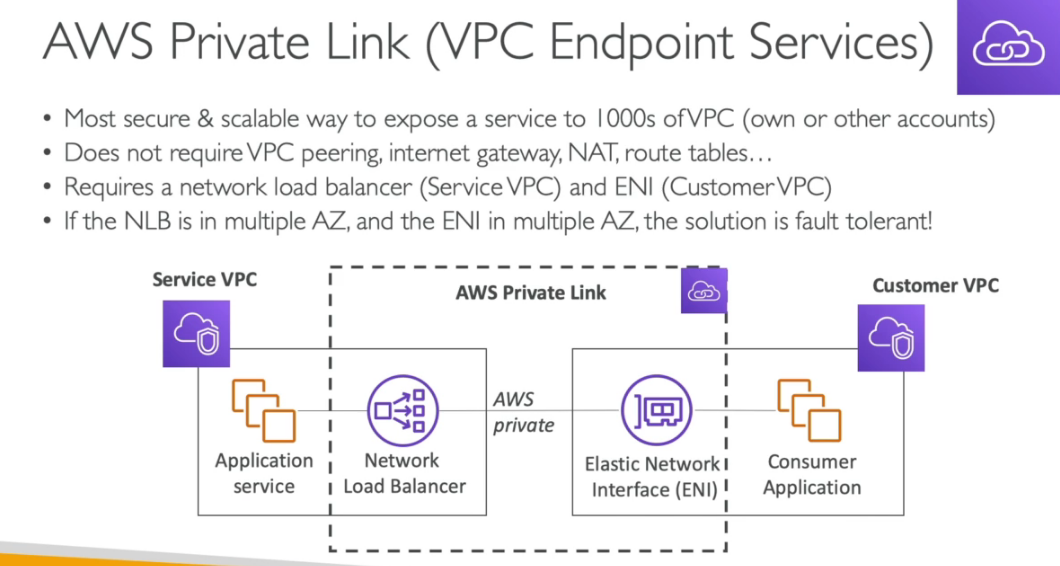
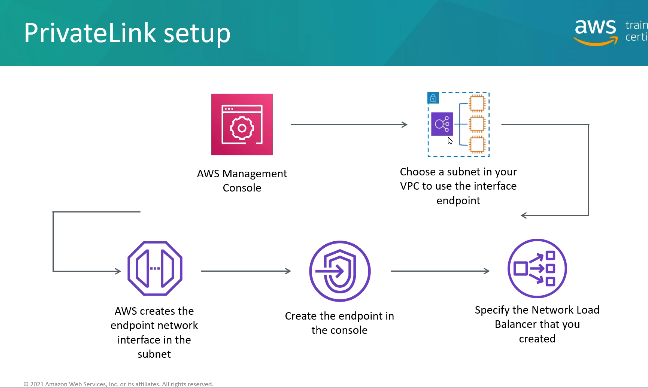
Interface - cria uma interface de rede (ENI) que fornece um IP para os serviços devem ser configurado o acesso no Security Group.
Gateway - usa um Gateway para provisionar um destino e deve ser configurado na tabela de rotas (Route Table)

Caso use VPC Endpoints deve se atentar a usar as configurações de DNS, Outra coisa que pode gerar confusão e que a partir da hora que se usa o VPC Endpoints e necessário informar as região ao usar comandos do CLI, pois o VPC Endpoints tem escopo regional.
VPC Endpoint Police



Casos de Uso
Limitações
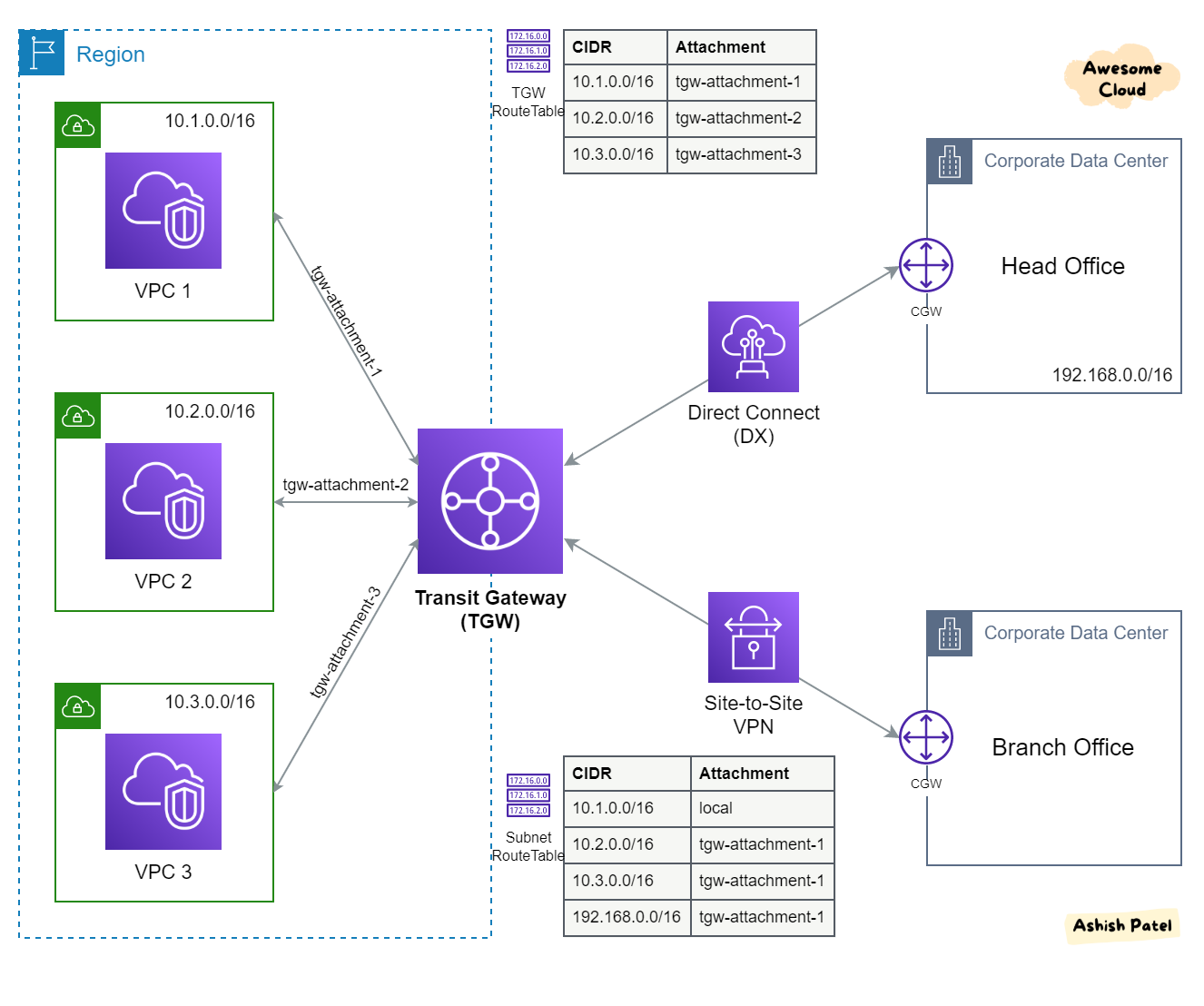
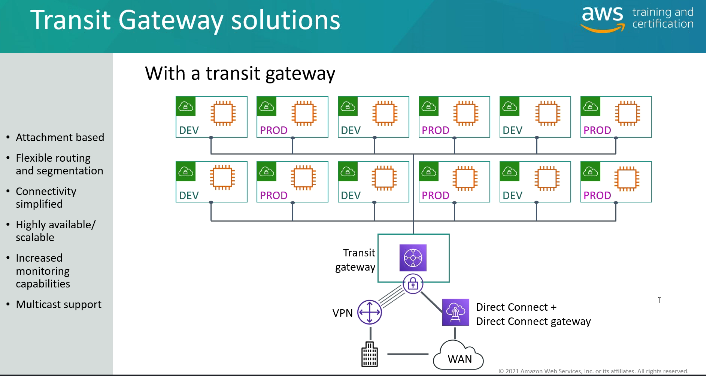
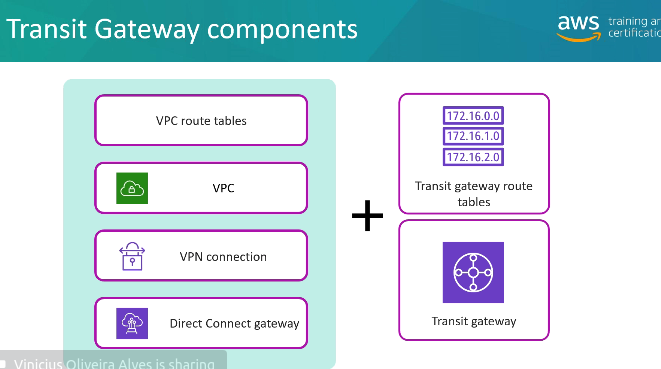
Inter e Intra Region Peering






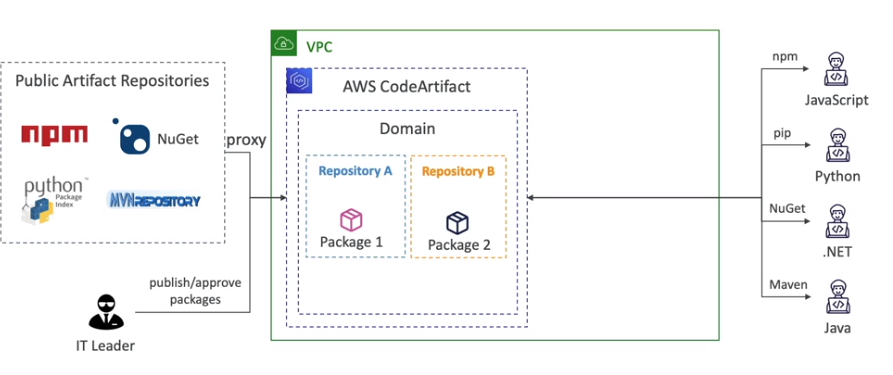
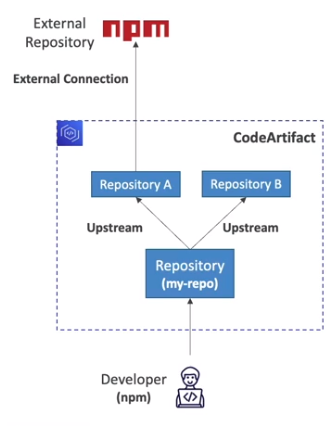
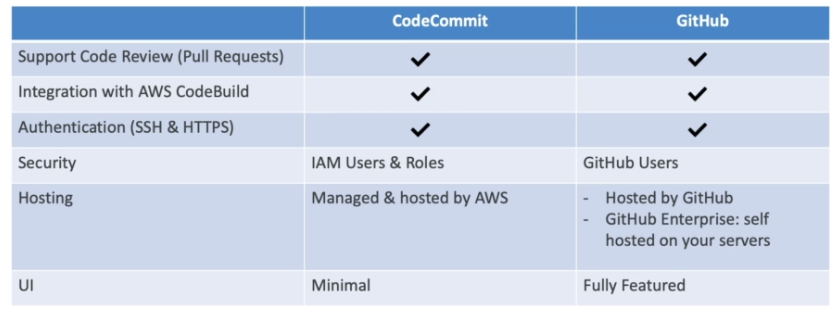
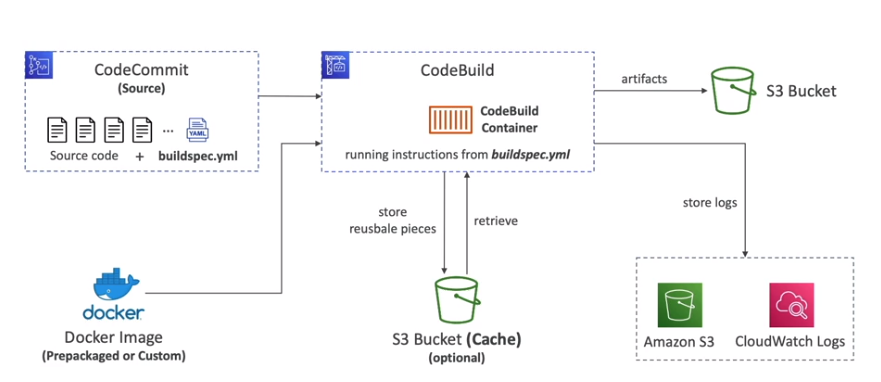
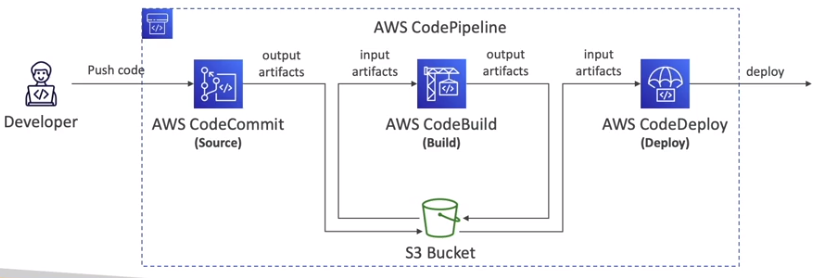
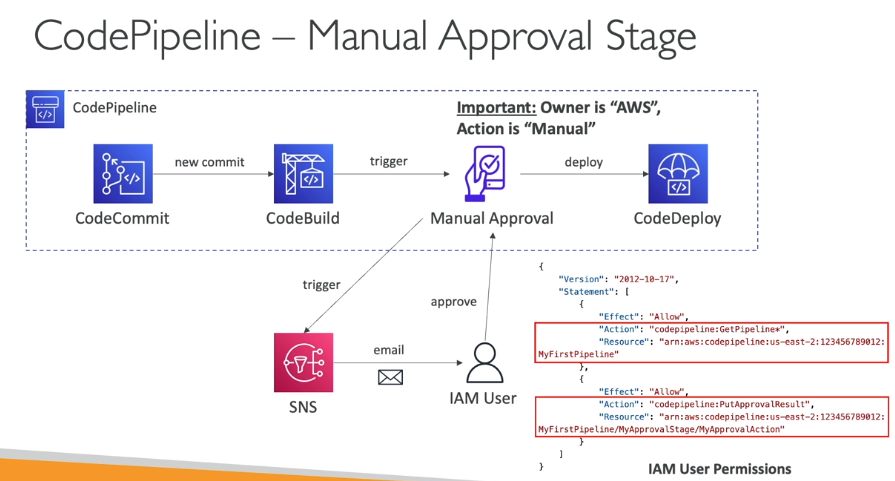
CodeCommit: armazene o código em repositórios controlados por versão. O código pode existir em múltiplos branches (ramificações).
CodeBuild: construa e teste o código sob demanda em suas pipelines de CICD.
CodeDeploy: faça o deploy do código em EC2, ASG, Lambda ou ECS.
CodePipeline: orquestre pipelines de CICD. Se usar o CodeCommit como fonte, ele se conectará a apenas um branch.
CloudSearch: solução de busca gerenciada para realizar pesquisas de texto completo, auto completar em suas aplicações.
Alexa for Business: use a Alexa para ajudar os funcionários a serem mais produtivos em salas de reunião e suas mesas.
Lex: Reconhecimento automático de fala (ASR) para converter fala em texto. Útil para construir chatbots.
Connect: receba chamadas, crie fluxos de contato, centro de contato virtual baseado em nuvem.
Rekognition: encontre objetos, pessoas, textos, cenas em imagens e vídeos usando Machine Learning.
Kinesis Video Stream: um fluxo por dispositivo de vídeo, análise usando instâncias do EC2 ou Rekognition.
WorkSpaces: estações de trabalho Windows sob demanda. WAM é usado para gerenciar aplicativos.
AppStream 2.0: transmita aplicativos de desktop para navegadores da web.
Mechanical Turk: marketplace de crowdsourcing para realizar tarefas simples para humanos, integração com SWF.
Device Farm: serviço de teste de aplicativos para seus aplicativos móveis e web em dispositivos reais.
Data Exchange - é um serviço de troca de dados na nuvem que permite que os clientes encontrem, assinem e usem dados de terceiros de maneira segura e eficiente.

Data Pipeline - permite criar pipelines da dados, onde se pode mover e transformar.

Lake Formation - ajuda a simplificar e acelerar a criação de data lakes seguros na nuvem

AWS AppFlow - permite a transferência segura de dados entre diferentes aplicativos de nuvem como Salesforce, Slack, Marketo e Zendesk, S3 e o Snowflake

AWS ECS Anywhere - Permite executar ecs em maquinas do cliente.
.3348533490091f0f0c9ae6d049092fea266b45fa.png)
AWS EKS Anywhere - permite que os usuários executem seus clusters do Amazon Elastic Kubernetes Service (EKS) em qualquer lugar - localmente, em data centers da empresa ou em outras nuvens - e gerenciem esses clusters por meio do AWS Management Console, AWS CLI ou API.
Usa se o AWS EKS Distro (versão do kubernetes da AWS) para rodar no cliente

AWS keyspaces - antigo Amazon Managed Apache Cassandra Service - permite criar e executar aplicativos Cassandra escaláveis na nuvem.
AWS Cloud9 - IDE baseado na nuvem que permite que os desenvolvedores escrevam, executem e depurem código. permite que várias pessoas trabalhem juntas no mesmo código e vejam as alterações em tempo real.
AWS Amplify - é um conjunto de ferramentas e serviços para criar e implantar aplicativos web e móveis escaláveis e seguros.

Amazon Pinpoint é um serviço de marketing por e-mail, SMS e notificação push para envolver e reter usuários em aplicativos móveis e web.

Compute:
Storage:
Database:
Migration and Transfer:
Networking and Content Delivery:
Developer Tools:
Management and Governance:
AWS Organizations SCPs - saiba toda a estrutura de aplicação de SCPs e a herança (vale muitos pontos!).
Conheça seu CloudFormation e como usar StackSets e Change Sets.
AWS Auto Scaling para serviços relevantes.
Saiba quais métricas você pode obter com o CloudWatch e quando você precisa de métricas personalizadas.
Saiba o que capturar com o CloudTrail e como usar o EventBridge ou CloudWatch Alarms/Events para reagir.
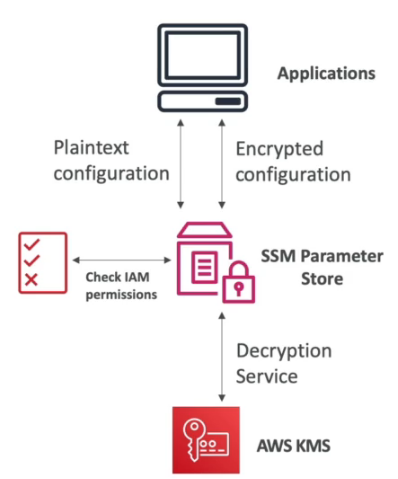
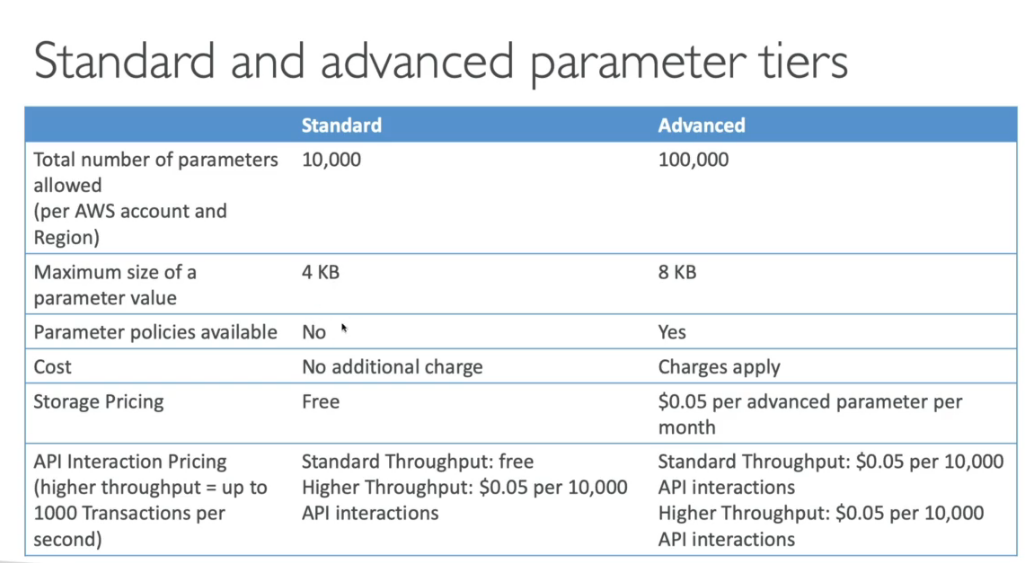
Casos de uso do Systems Manager Parameter Store e serviços de patching.
Service Catalog e como compartilhar portfólios na AWS Organizations.
Casos de uso do OpsWorks e opções de implantação.
Machine Learning:
Analytics:
Security, identity and compliance:
Front-end Web and Mobile:
Application Integration:
Cost management:
End-user computing:
Internet of things:
link: https://bookshelf.vitalsource.com/reader/books/300-ADVARC-30-EN-SG-E/pageid/806
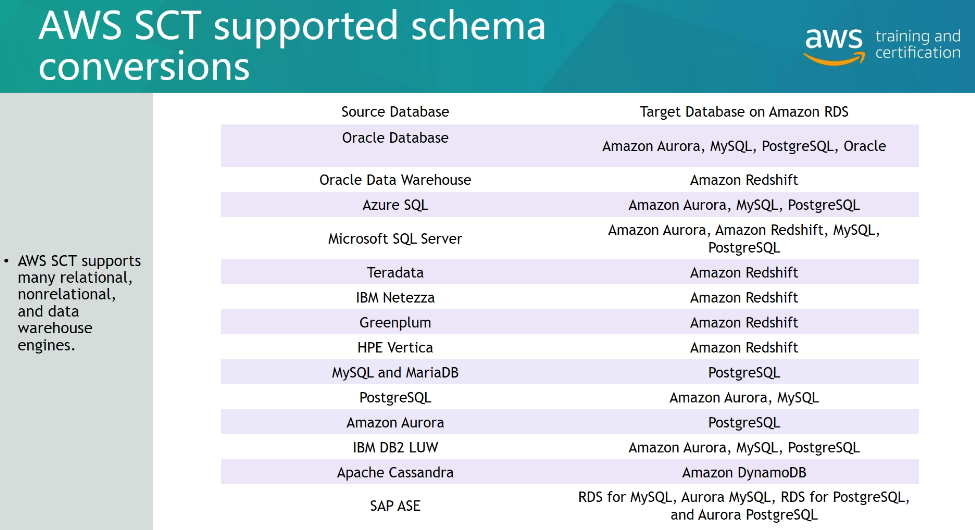
 AWS SCT
AWS SCT
ec2 - nitro, usado quando se quer não virtualizar certo componentes, tipo a placa de rede, o que pode melhorar o trafico de rede



 cd ~
ping 10.1.1.158
ping 10.2.2.205
ping 10.3.3.78
ping 10.4.4.125
ping 10.0.8.13
tgw-0e2ee82c8f1d39125
tgw-07b424246b676ba8b
cd ~
ping 10.1.1.158
ping 10.2.2.205
ping 10.3.3.78
ping 10.4.4.125
ping 10.0.8.13
tgw-0e2ee82c8f1d39125
tgw-07b424246b676ba8b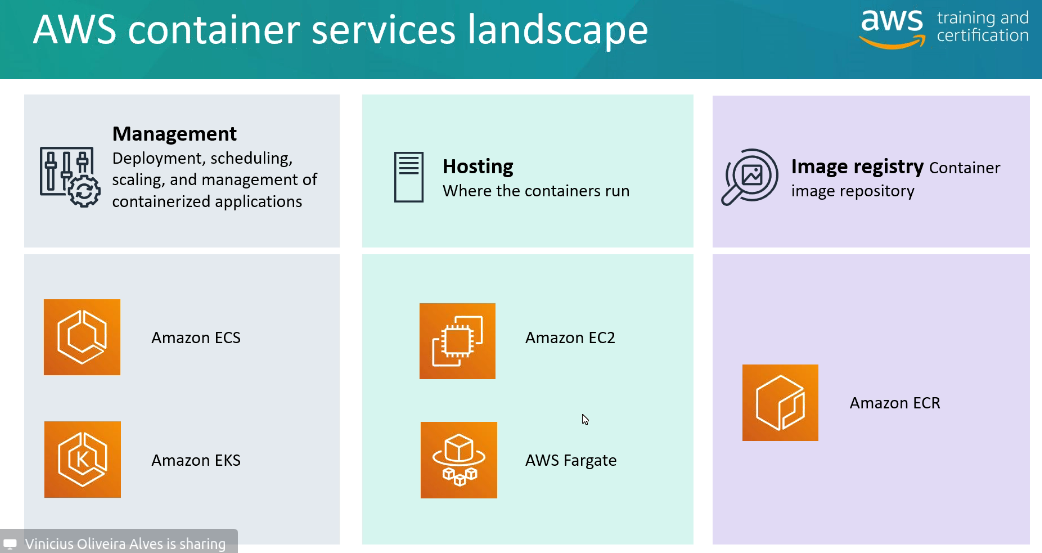
 Workshops
Workshops
# Show merged kubeconfig settings
kubectl config view
# List all services in the namespace
kubectl get services
# List all pods in all namespaces
kubectl get pods --all-namespaces
# List all pods in the current namespace, with more details
kubectl get pods -o wide
# List a particular deployment
kubectl get deployment my-dep
# List all pods in the namespace
kubectl get pods
# Get a pod's YAML
kubectl get pod my-pod -o yaml
# Describe commands with verbose output
kubectl describe nodes my-node
kubectl describe pods my-pod
COMANDOS EKSCTL
# List the details about a cluster
eksctl get cluster [--name=<name>][--region=<region>]
# Create the same kind of basic cluster, but with a different name
eksctl create cluster --name=cluster-1 --nodes=4
# Delete a cluster
eksctl delete cluster --name=<name> [--region=<region>]
# Create an additional nodegroup
eksctl create nodegroup --cluster=<clusterName> [--name=<nodegroupName>]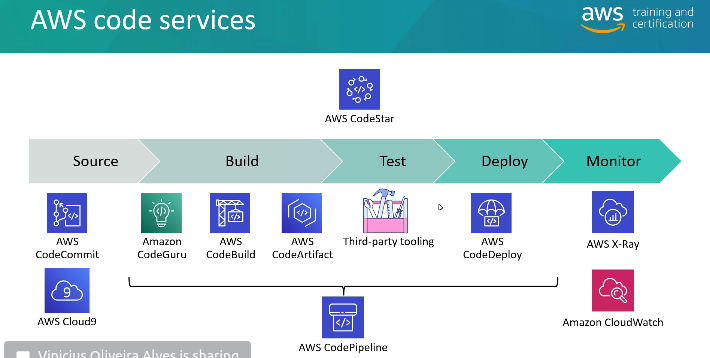


 AWS Firewal manager
AWS Firewal manager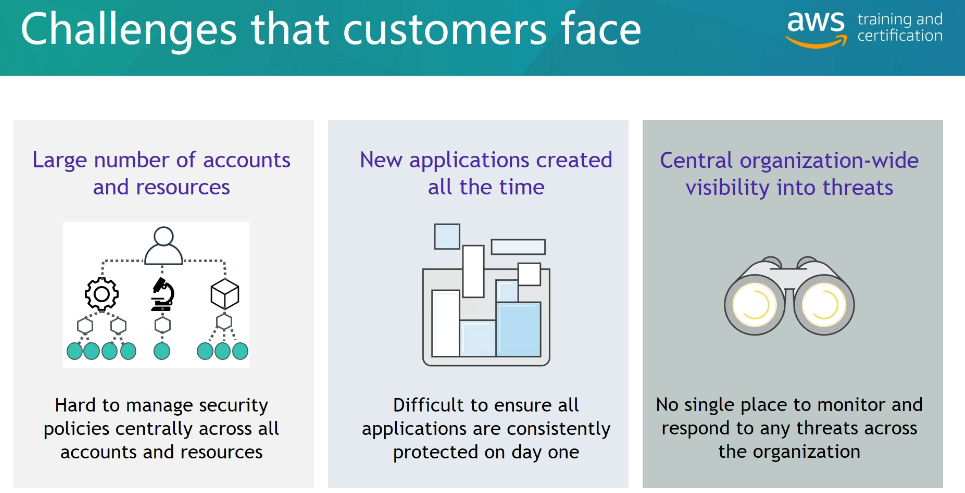
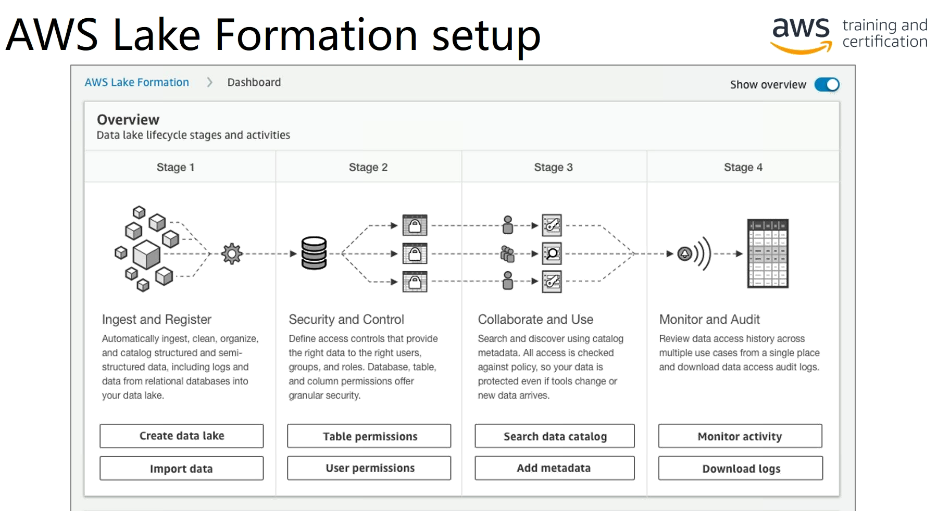 AWS Cloud9
AWS Cloud9
Leia sobre a AWS Certified Developer - Associate. (DVA-C02)
| Dominio | % do exame |
|---|---|
| Domínio 1: Desenvolvimento com os serviços da AWS | 32% |
| Domínio 2: Segurança | 26% |
| Domínio 3: Implantação | 24% |
| Domínio 4: Solução de problemas e otimização | 18% |
Recursos e produtos da AWS no escopo
Serviços AWS usado para análise de dados.
Contextualização:
Contextualização:
Tempos os seguintes serviços AWS usados para integração de aplicações:


Contextualização:
Contextualização:
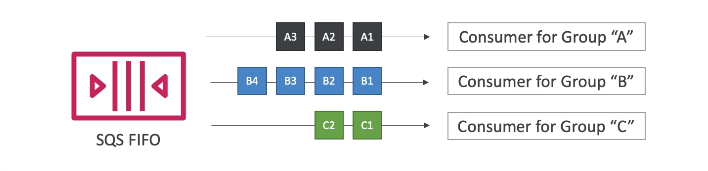
Contextualização:
Contextualização:
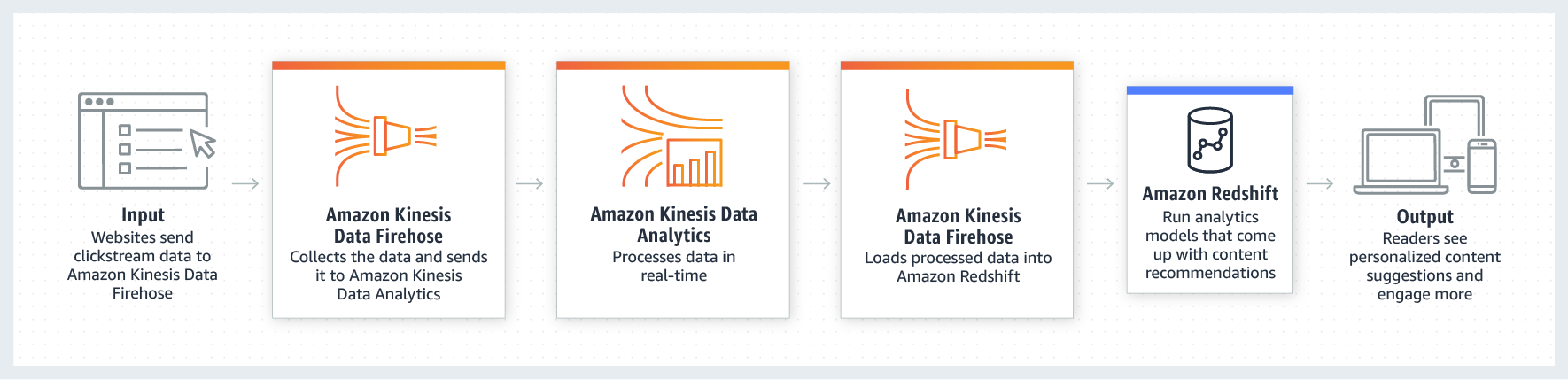
Usado para ingestão de log, métricas, website ClickStreams, telemetria IOT.
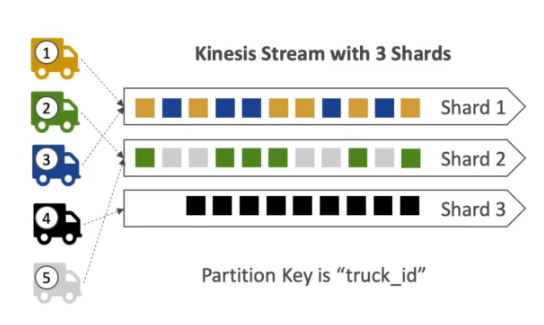
Kinesis Producer
Kinesis Consumer
KCL - Kinesis client library
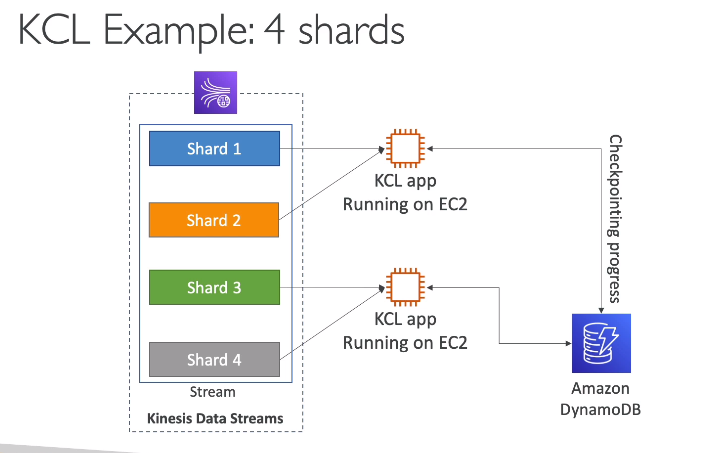
Kinesis Operations
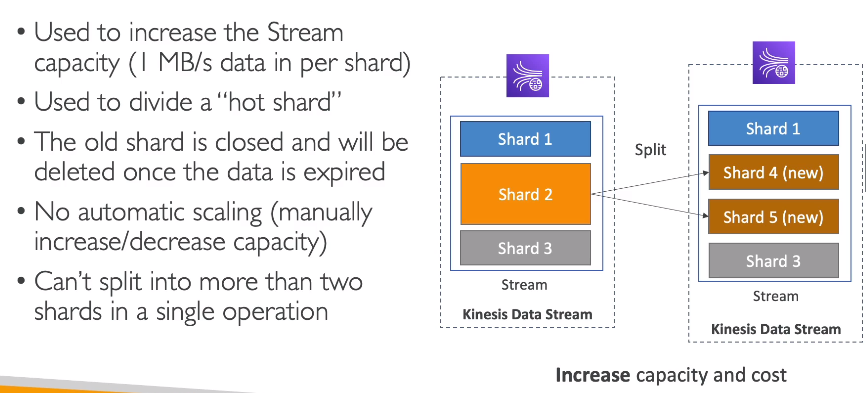
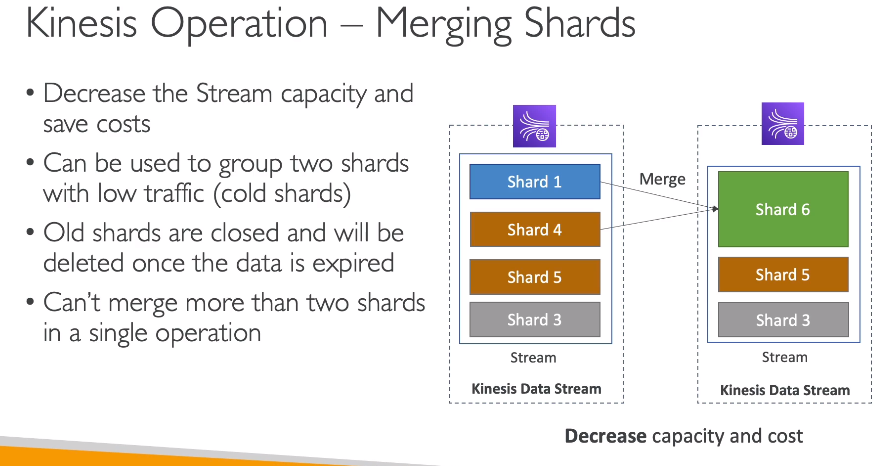
Contextualização:
Contextualização:
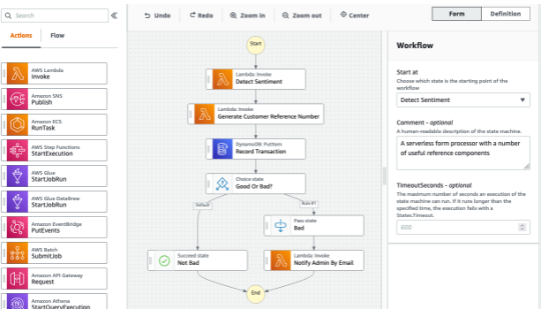
Escrito em json.
usado para orquestrar chamada de serviços.
Cada etapa é chamado de task.
Tem os tipos:
Erro handling


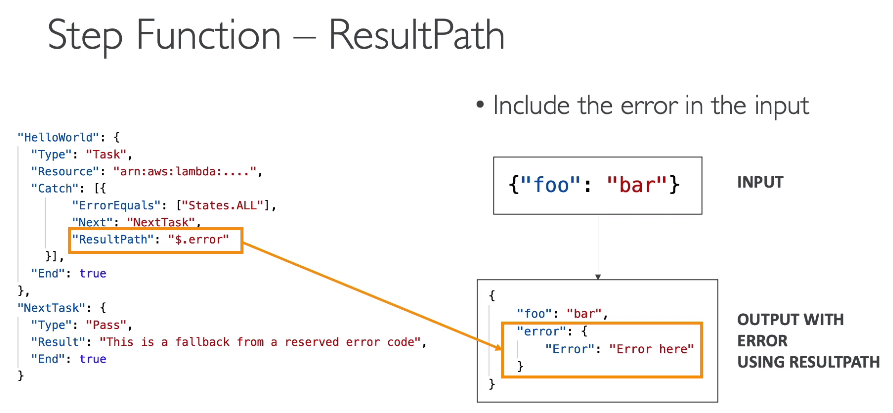
Veja aqui tudo que se precisa saber sobre Budgets
Contextualização:
Ao gerar o key pair atente-se ao:
Usado para pre configurar um instância Ec2. O exemplo abaixo instala o apache na instância.
## Considerando que AMI seja RedHat Based.
#!/bin/bash
yum update -y
yum install httpd -y
systemctl start httpd
systemctl enable httpd
echo “Hello World from $(hostname -f)” > /var/www/html/index.htmlTOKEN=`curl -X PUT "http://169.254.169.154/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-secondas:21060"` curl http://169.254.169.254/latest/metadata -H "X-aws-ec2-metadata-token: $TOKEN" curl -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/metadata/identity-credentials/ec2/security-credentials/ec2-instanceContextualização:
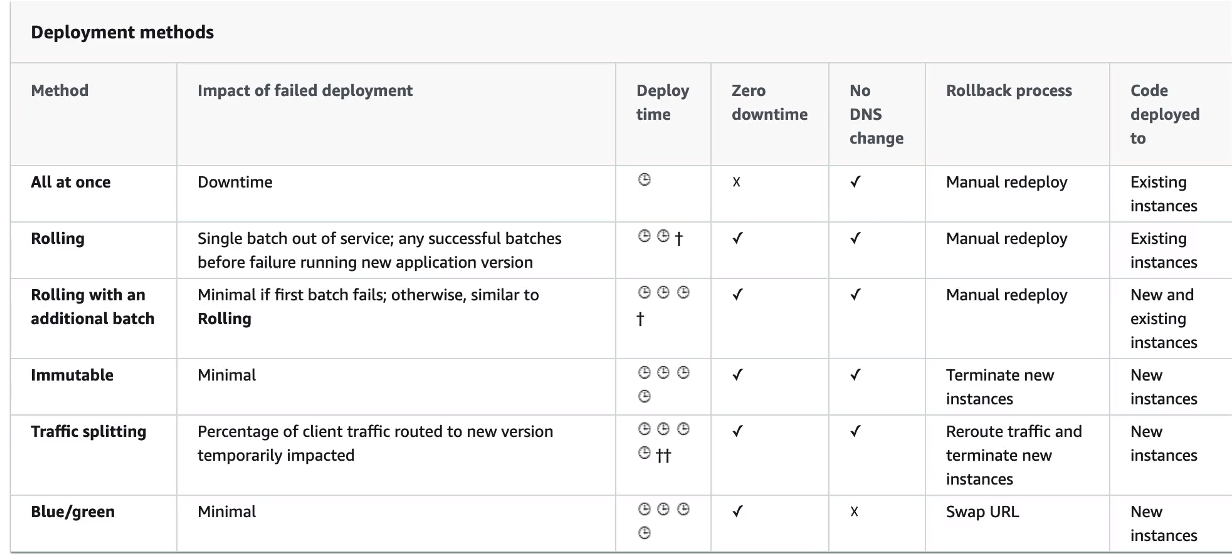
All at once - Tudo de uma vez.
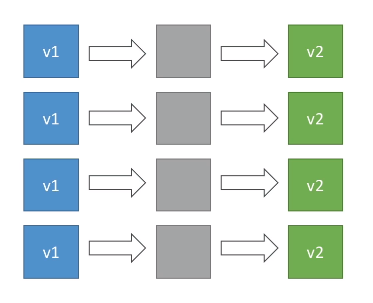
Rolling - Cria uma nova versão (chamada de bucket) derrubando parte das instâncias já existentes e redireciona o trafego quando a nova versão estiver de pé.
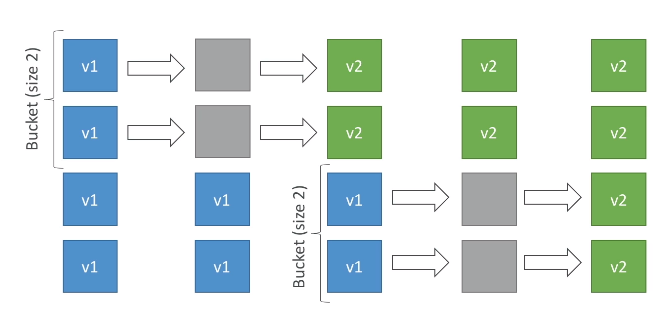
Rolling com batches adicionais - Igual ao anterior, mas faz o redirecionamento em partes, mantendo a convivência entre a nova e a versão antigo por algum tempo.
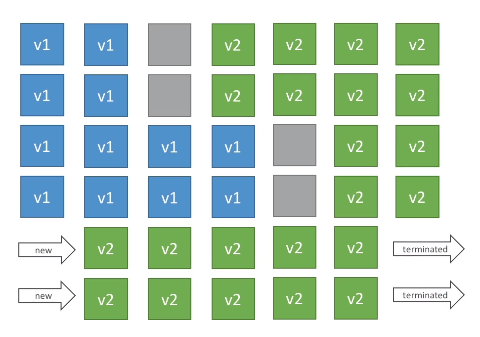
Immutable - realiza o deploy das instâncias em novo ASG, e quanto esse estiver disponível, se move as instâncias para o ASG antigo e termina as instâncias anteriores.
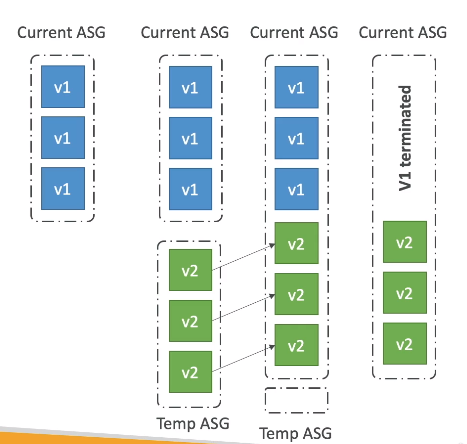
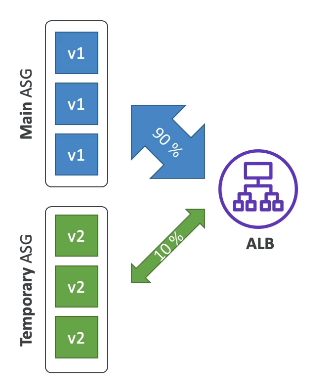
Blue/green - Cria se um novo ambiente, e redireciona (Route 53) quando estiver tudo ok.
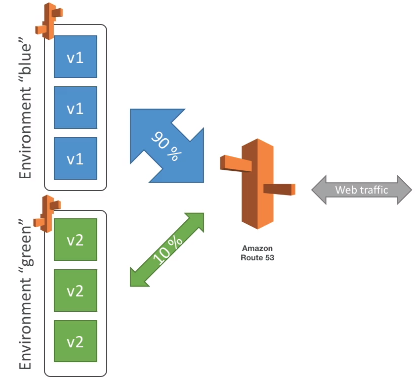
Traffic Splitting envia uma porcentagem de trafego para grupo de instâncias.
Usado para teste canário.
Contextualização:
Linguagem suportadas:
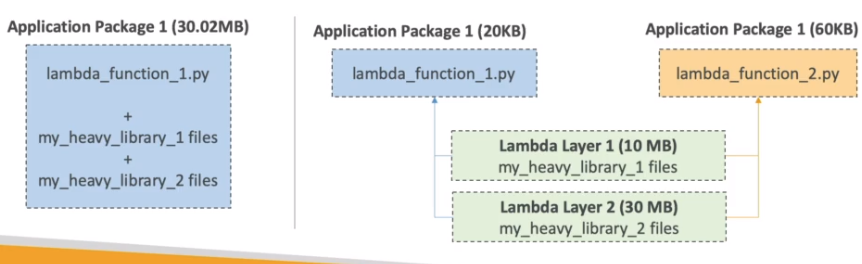
As dependências devem ser enviadas juntos com o condigo da Lambda. Respeitando a limitações do tamanho do pacote.
Suporta também Lambda Contêiner Image.
Para atualizar uma Lambda usando o CloudFormation deve se realizar o upload o pacote zipado para o S3 e referência-lo no CloudFormation.
Lambda Trigger
Na integração com ELB, os dados do request são transformado em Json e repassados a Lambda.

Há dois modos de operação:

Integrações com CW Events / EventBridge
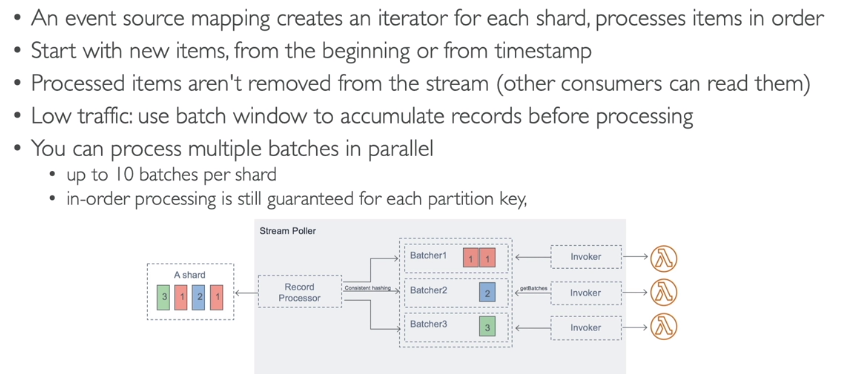
Event Source Mapping - Lambda Trigger
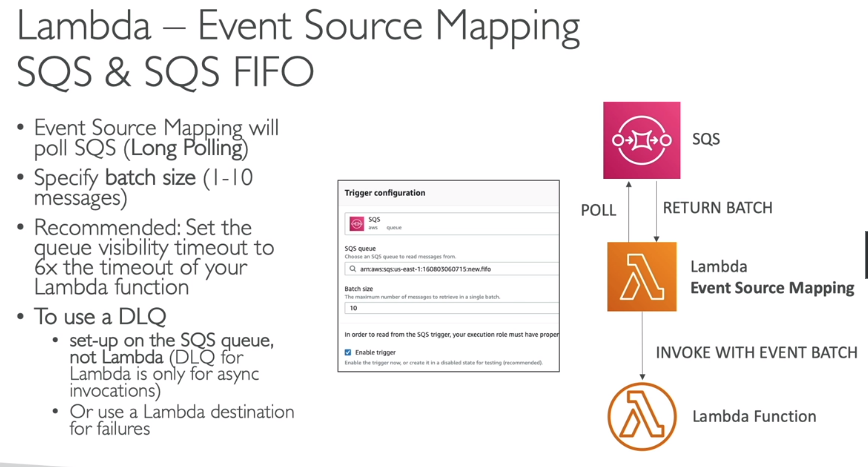
Event e Context Object
Lambda destination
Lambda polices
Lambda Logging & Monitoring
Lambda VPC
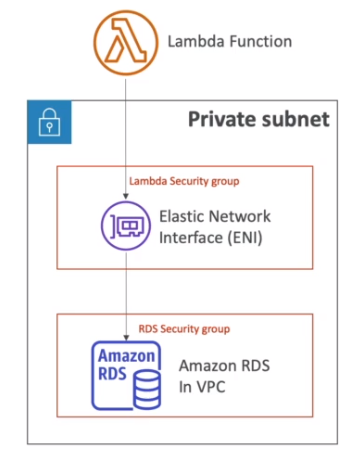
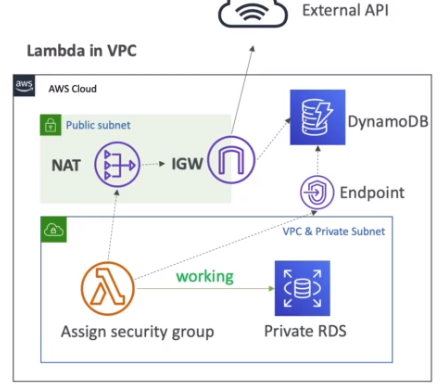
Lambda performance

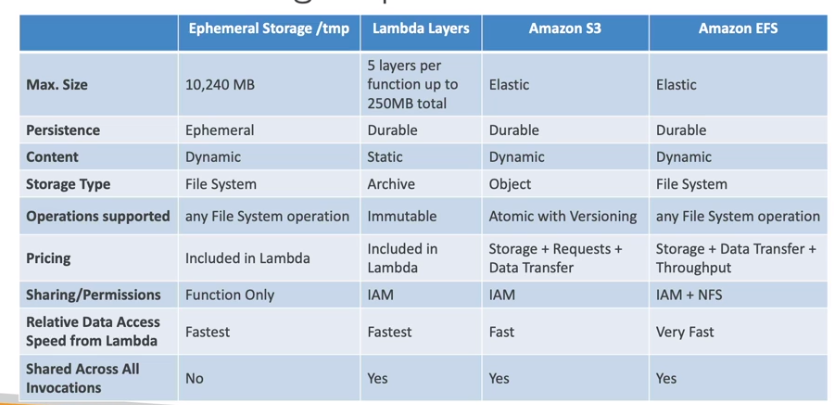
Lambda Layers
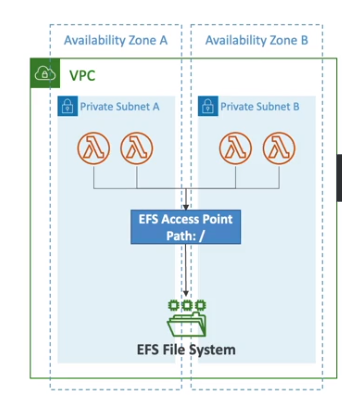
Lambda File System Mounting
Lambda Concurrency an Throttling
Lambda Container Image

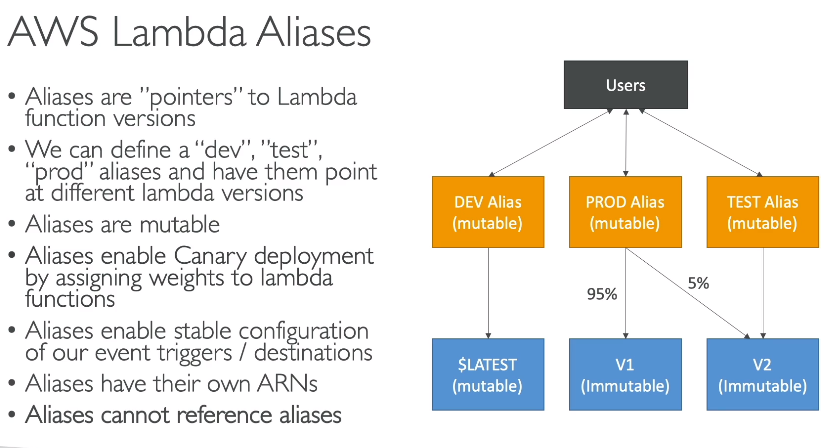
Lambda Version e Aliases

Lambda URL
Permite criar um endpoint dedicado para o Lambda. Suporta IPV4 e IPV6.
Gerada um URL única para a Lambda, que pode apontar para um alias ou $Latest.
Suporta CORS e politica baseada em recurso. (especificando CIDR ou IAM principal).
Pode ser configurada via Console ou API.
Tipo autenticação:

Lambda boas praticas

Contextualização:
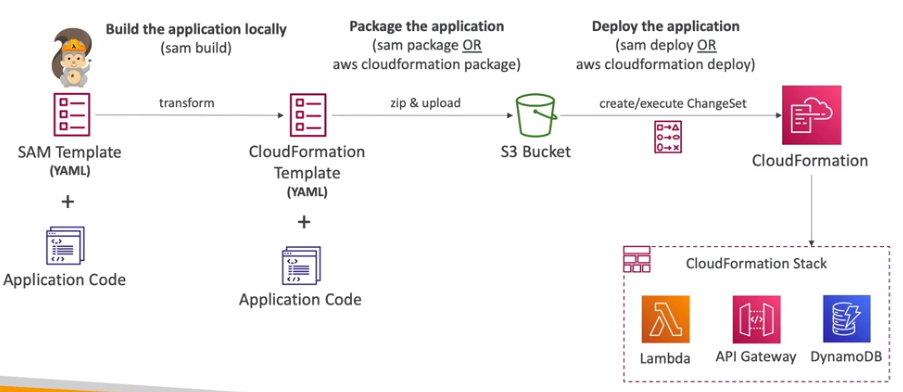
Construido em cima do CloudFormation.
Comandos:
# Inicia um projeto
sam init
# realiza o build
sam build <options>
# empacota a aplicação para cloudFormation
sam package --s3-bucket <bucket-name> --template-file template.yaml --output-template-file gen/template-generated.yaml
## é equivalente a:
aws cloudformation package --s3-bucket <bucket-name> --template-file template.yaml --output-template-file gen/template-generated.yaml
# Realiza o deploy
sam deploy <options>
## é equivalente a:
aws cloudformation deploy --template-file gen/template-generated.yaml --stack-name <stack name> --capabilities CAPABILITY_IAM
## Deploy configuravel via perguntas - realiza perguntas e executa o empacotamento e o deploy num comando só
sam deploy --guidedProcesso de uso:
As Polices criados pelo SAM, são baseados em templates configurados pela AWS.
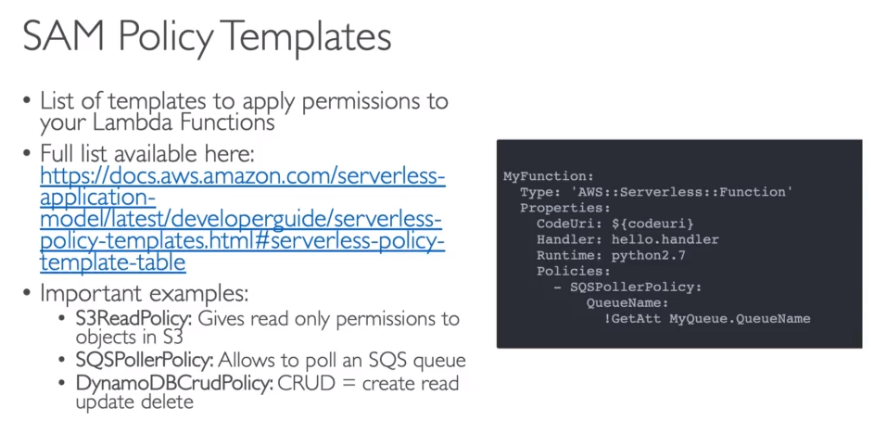
Ao se criar uma Lambda, há uma opção de usar um projeto já pronto a partir de um exemplo do SAM Aplication Repository (SAR).
Como configurar o SAM com o CodeDeploy para realizar o Traffic Shifting

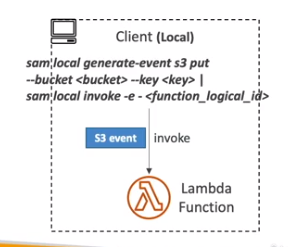
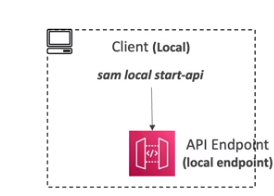
Como executar SAM Localmente para testes.
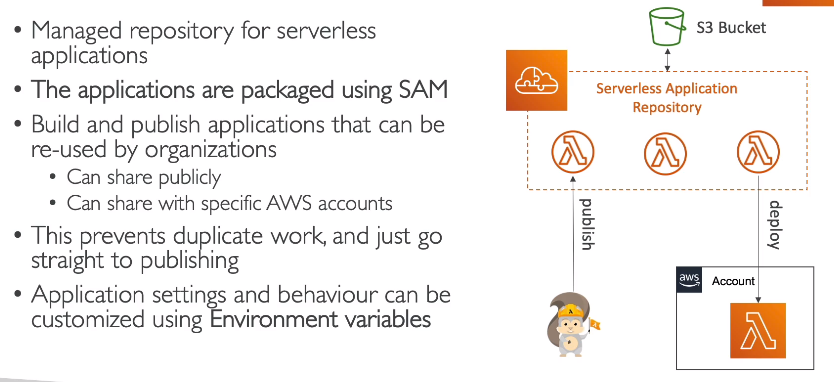
SAM Aplication Repository (SAR).
Contextualização:
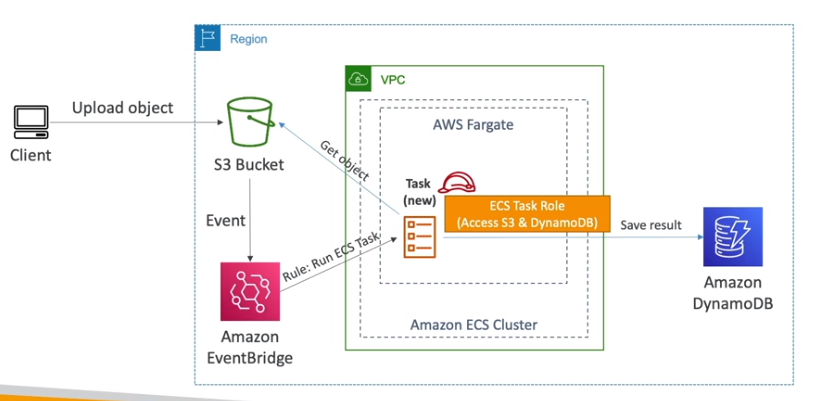
Há dois tipos:
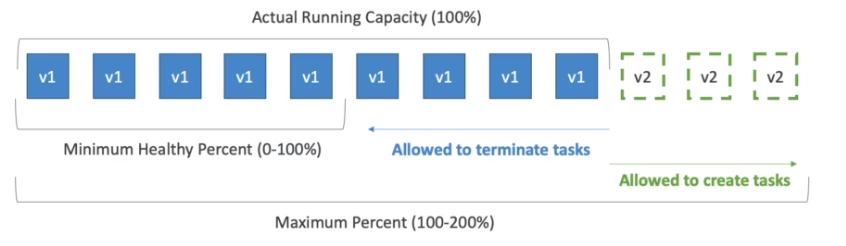
Pode escalar usando 3 métricas:
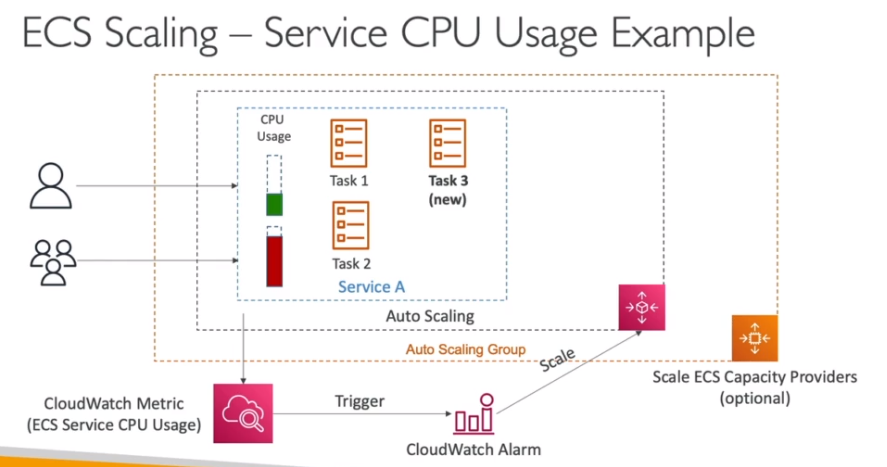
Pode escalar por







Tasks definitions
Contextualização:
Contextualização:
Contextualização:
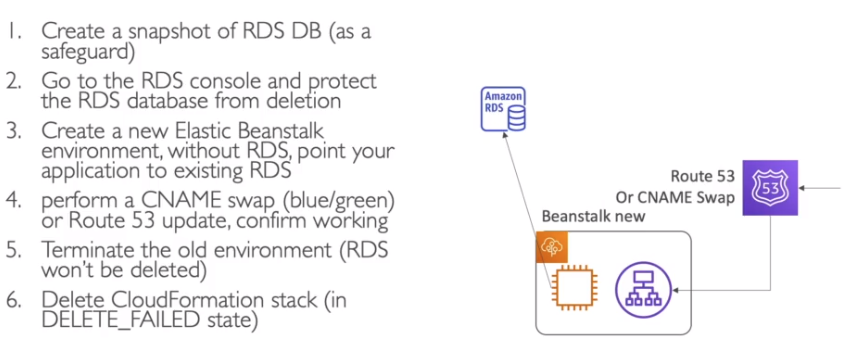
O que é RDS
Veja também:
Contextualização:
Contextualização:
Pode se alterar o modo de provisionado ou sob demanda a cada 24 horas.
Tipos de dados aceitos nos atributos:
Caso provisione os WCU e RCU, e exceda pode se usar temporariamente o Burst Capacity, que permite ter um Throughput extra.
Tem uma funcionalidade de auto scale que reconfigura os valores de WCU e RCU de acordo com o uso.
Operações
PutItem -> cria novo item.
UpdateItem -> Atualiza atribuídos de um item já existente.
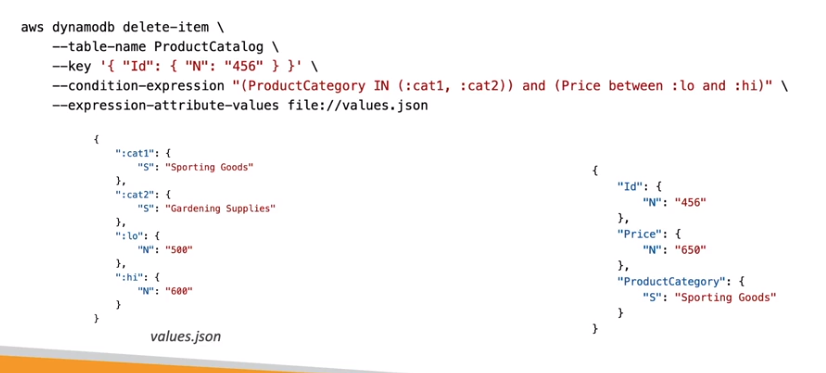
Conditional expression for Writes -> Adiciona / Deleta / Atualiza de acordo com uma condição.
DynamoDB Streams - Stream das alterações que ocorrem no banco de dados.
DynamoDB CLI - Bom saber sobre a API do dynamoDB no AWS CLI.
DynamoDB Transactions

Contextualização:


Contextualização:
Contextualização:





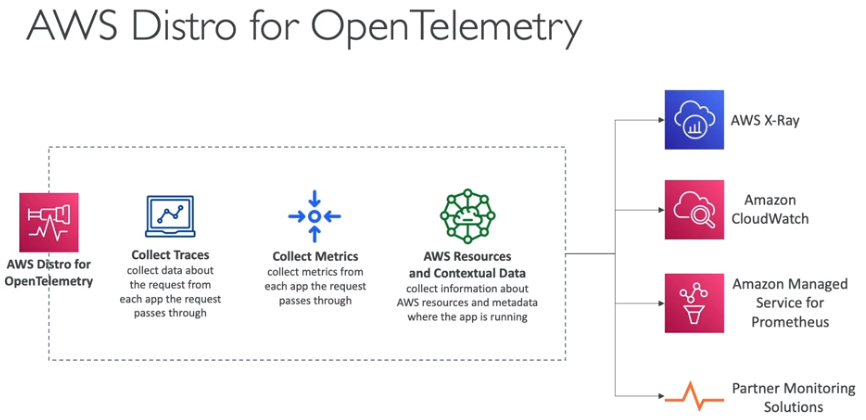
Contextualização:
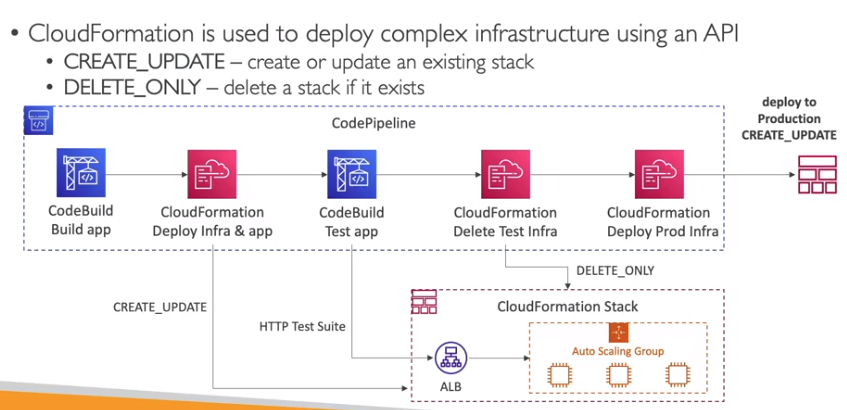
Pode se usar o AWS CLI para deployar um template do CloudFormation.
O CF trabalha com templates é composto por:

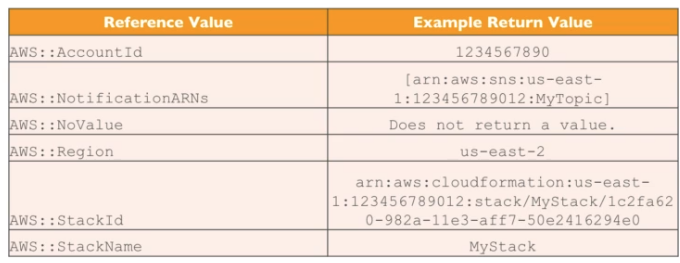

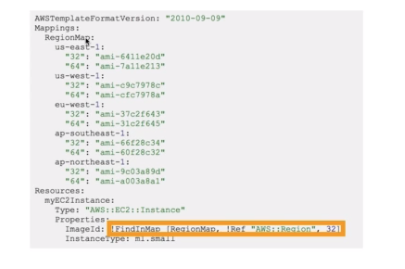

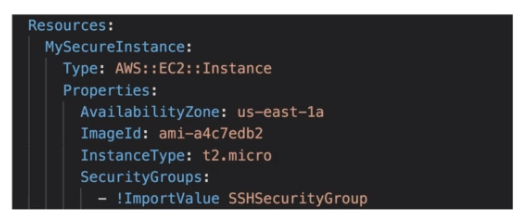

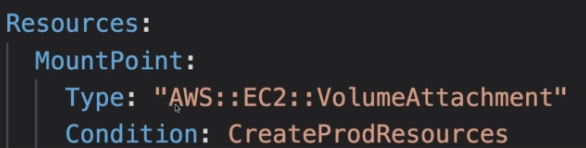
Há também as Funções intrisicas
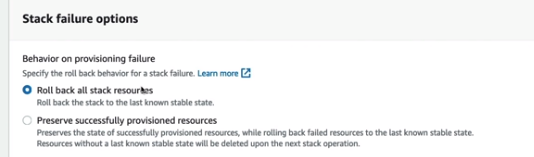
Processo de rollback
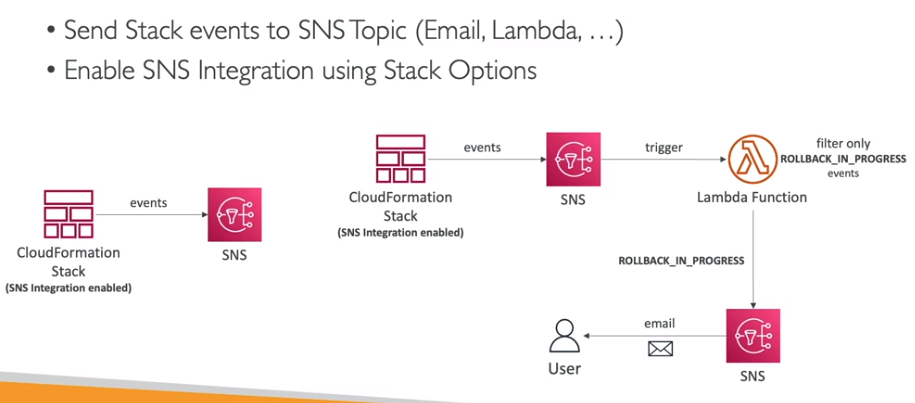
É possível habilitar a notificação das ações da stack via tópico SNS.
Tem o CF Drift que mostra qual foi a alteração que o recurso criado pela Stack sofreu.
A Stack police serve para limitar as ações que uma Stack pode fazer, como por exemplos, quais recursos que pode criar ou atualizar.
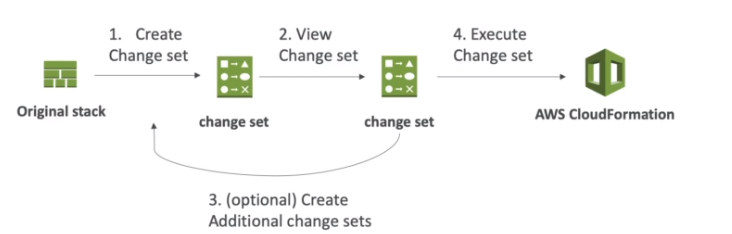
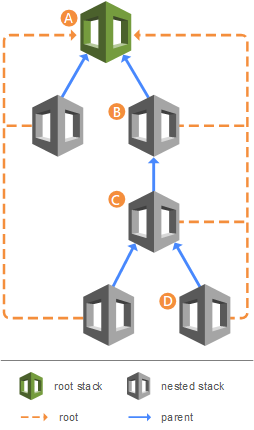
Contextualização:
Contextualização:

Contextualização:


Pré requisitos:
aws configure
# preencha os itens com os dados do access key.
# serve para configurar novos profiles (outra conta)
aws configure --profile <nome_novo_profile># use o comando para testa e listar o usuários
aws iam list-user
# use o comando para testa e listar o usuários pra um profile e
aws iam list-user --profile <nome_profile>aws sts get-session-token --serial-number <arn-do-dispositivo-mfa> --token-code <codigo-mfa> --duration-seconds 3600
Descreve a sequência que se usa para recuperar os acessos ao recursos da AWS.


Contextualização:
Contextualização:

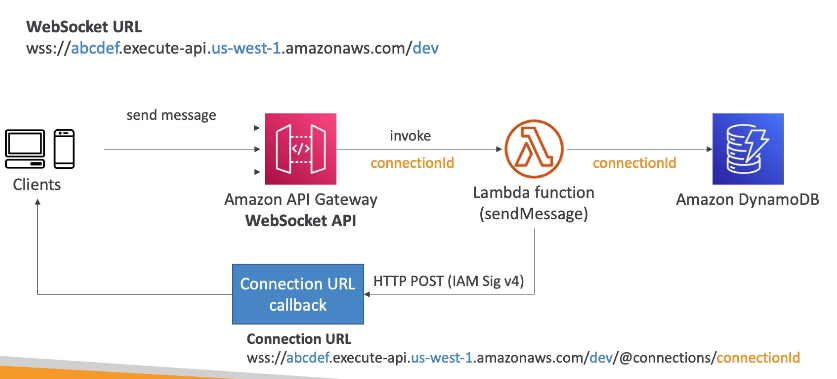
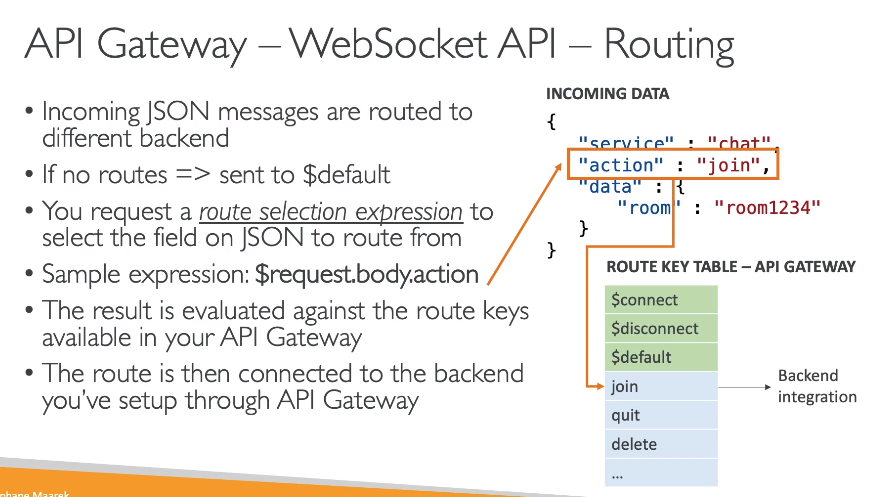
Contextualização:

 Logs em tempo real
Logs em tempo real
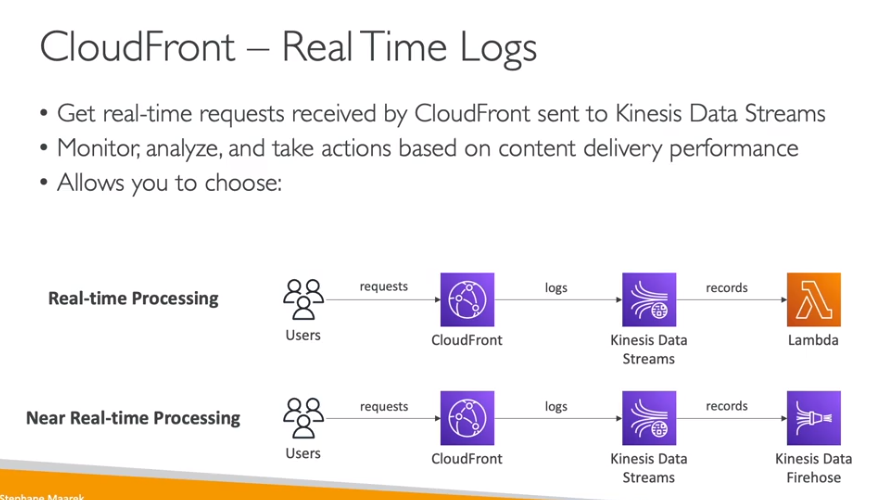
Contextualização:
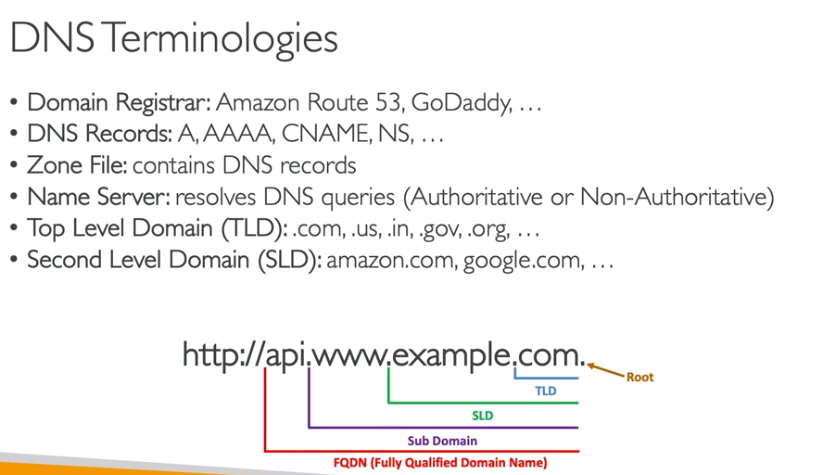
Não cai muitas coisas sobre isso na prova da certificação develop, mas é importante conhecer os conceitos.

Leitura recomendada:
Leitura recomendada:
Contextualização:
Contextualização:

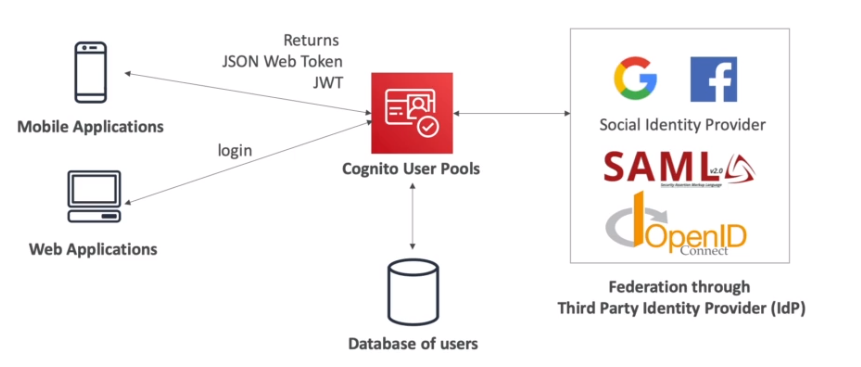



- Há dois via sofware (dispositivo MFA virtual, Chave de chegurança U2F (ex: YUbiKey))
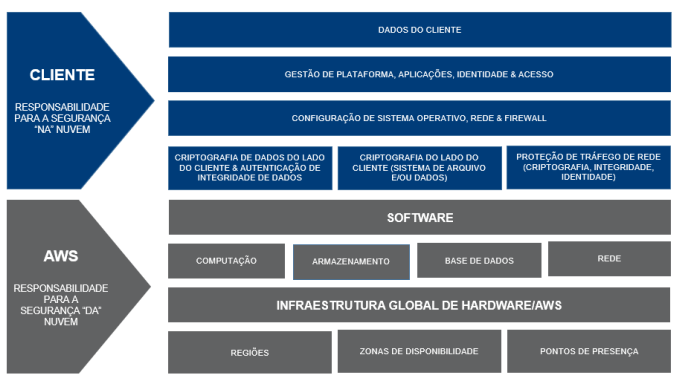
- Há uma opção de Hardware (ex: token Gemalto)a segurança na cloud é compartilhada e a AWS e nós temos responsabilidades para garantir a conformidade e segurança

Contextualização:
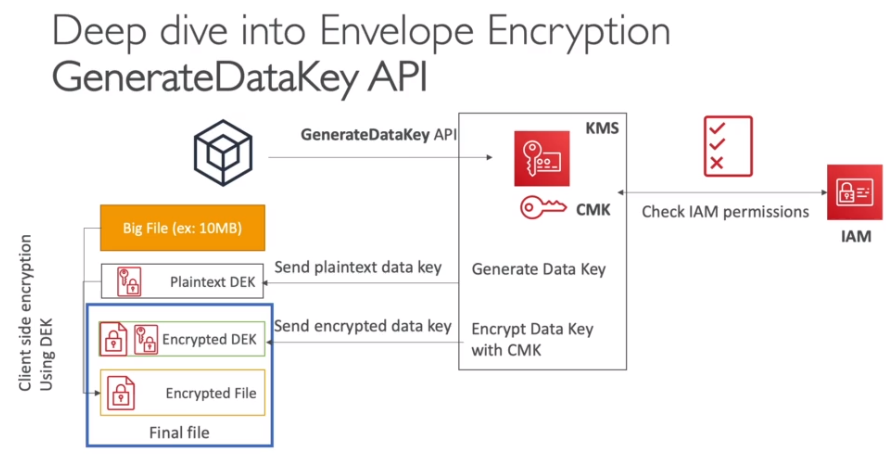
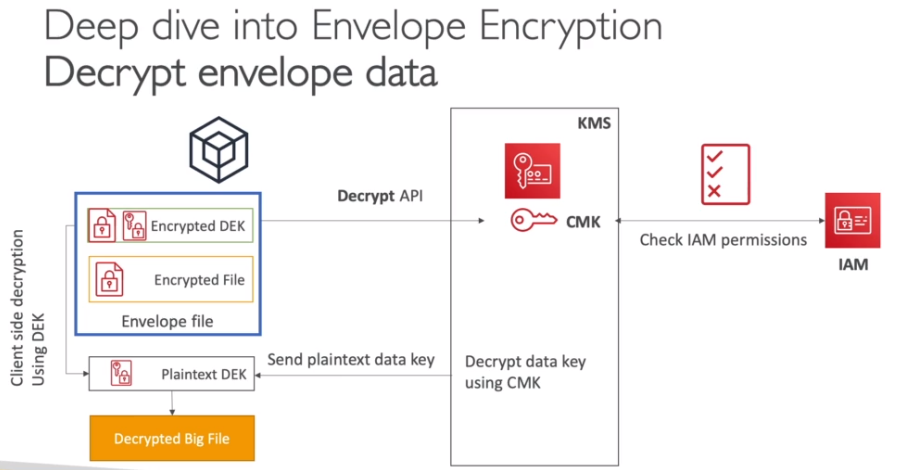

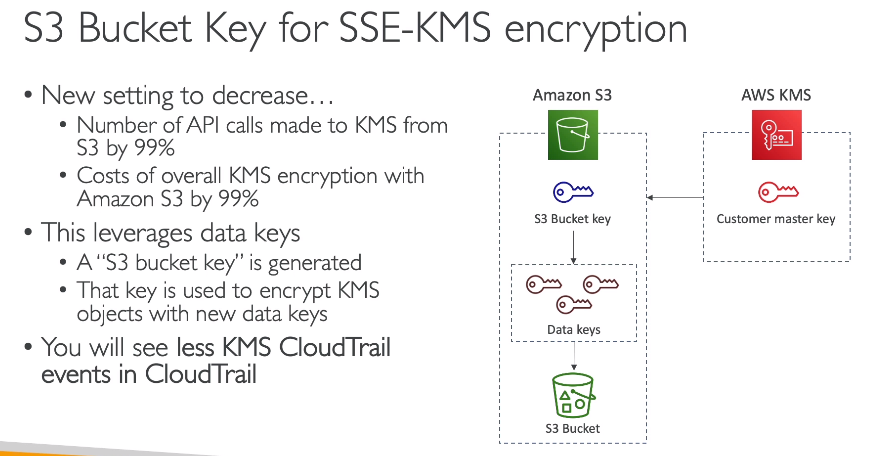
Contextualização:
Permite acesso temporário aos recursos de 15 minutos a até 1 hora.
Para adicionar MFA precisa adicionar a IAM police uma IAM condition chamada aws:MultiFactorAuthPresent:true
Contextualização:
Contextualização:

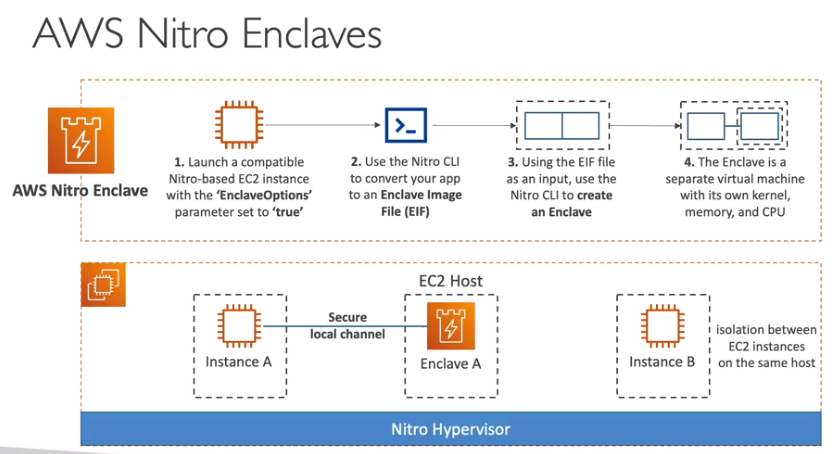
Contextualização:
Uma questão comum quanto ao S3 é como melhorar o tempo de busca de arquivos, a arquitetura que melhora resolve esse problema seria criar um index no DynamoDB com os metadados e tags do arquivos e realizar as busca no DynamoDB e apenas recuperar os arquivos no S3.
S3 - Encryption para prova

Contextualização:
Contextualização:
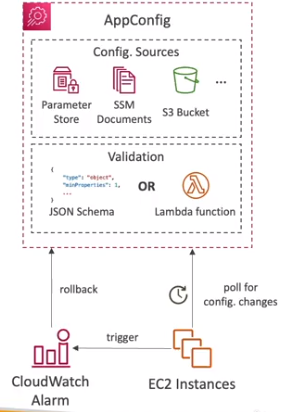
Em construção
Paginas:
Paginas:

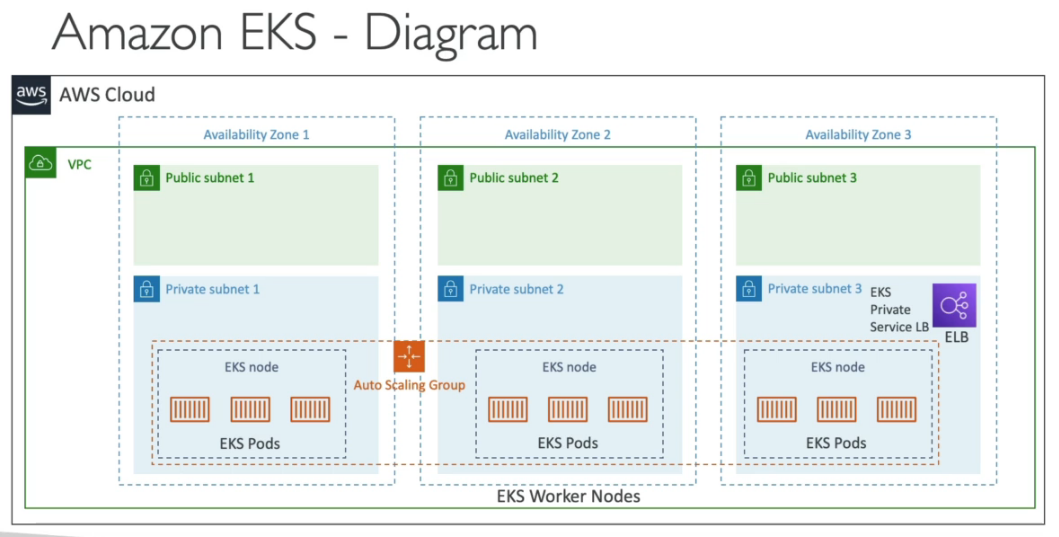
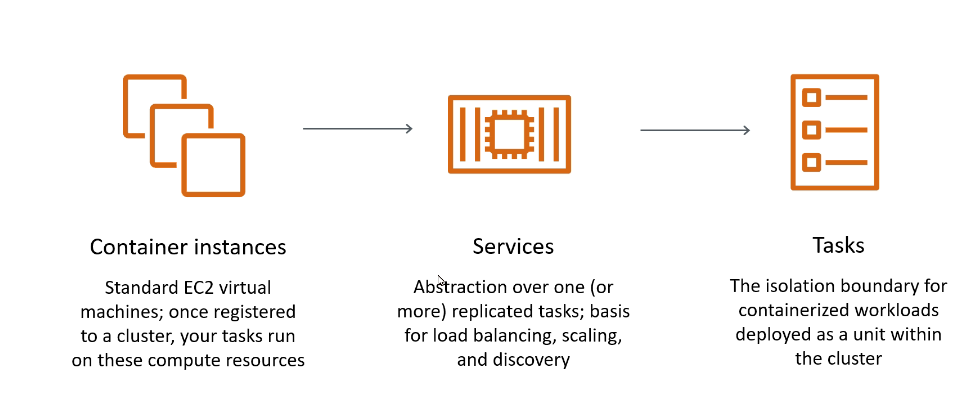
Um cluster é composto por:






Para rodar o kubernets localmente, usamos o minikube, para baixa-lo acesse:
## Arquivo de configuração
## Minikube
## link: https://minikube.sigs.k8s.io/docs/start/
### Install minikube
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
### Start
minikube start
### Use
minikube kubectl -- get nodes
### Create alias dentro do .bashrc
alias kubectl="minikube kubectl --"
#-----------------------------------------------------------------------------------------------
## há a opç
#-----------------------------------------------------------------------------------------------
# Listando contextos possiveis
cat ~/.kube/config
kubcetl config get-cluster
# setar um contexto
kubectl cluster-info --context <contexto>
kubcetl config use-context <contexto>
# Setando o Kind como cluster padrão no kubctl
kubectl cluster-info --context kind-kind
kubcetl config use-context kind-kind
# Setando o minikube como cluster padrão no kubctl
kubectl cluster-info --context minikube
# Setar namespace padrão
kubectl config set-context --current --namespace=<namespace>
kubectl config set-context --current --namespace=ucontas-app
#-----------------------------------------------------------------------------------------------
### KUBERNETES (KUBECTL)
alias k="kubectl"
alias ka="kubectl apply -f"
alias kl="kubectl logs"
alias kdd="kubectl describe deployment"
alias kdp="kubectl describe pod"
alias kds="kubectl describe service"
alias kei="kubectl exec -it"
alias kgd="kubectl get deployments"
alias kgp="kubectl get pods"
alias kgs="kubectl get services"
alias krrd="kubectl rollout restart deployment"
alias kdad="kubectl delete --all deployments"
alias kdap="kubectl delete --all pods"
alias kdas="kubectl delete --all services"
### DOCKER
alias d="docker"
alias dc="docker compose"
alias di="docker images"
alias dl="docker logs"
alias db="docker build -t"
alias dps="docker ps"
alias dcu="docker compose up"
alias dcc="docker compose config"
alias drc="docker rm $(docker ps -a -q)"
alias dsa="docker kill $(docker ps -q)"
alias dsp="docker system prune -a --volumes"
alias dcps="docker compose ps"
alias dcenv="docker compose --env-file"
alias usedd="docker context use docker-desktop"
alias usede="docker context use default"
### Dasboard
minikube dashboardSegue alguns comandos uteis usados
# Recuperas os nodes criados
kubectl get nodes
# abre serviços
minikube service <nome do serviço>
# Listar pods
kubectl get pods
# listar pods com detalhes
kubctl get pods -o wide
# Acompanhar status pod
kubectl get pods --watch
# Criar novo pod
kubectl run <nome-pode> --image=<imagem>:<versão>
# - ex:
kubectl run nginx-pod --image=nginx:latest
# Descrever informações do pod
kubectl describe <nome-pode>
# - ex
kubectl describe pod nginx-pod
# Editar pod
kubectl edit pod <nome-pod>
kubectl edit pod nginx-pod
# deletar pod
kubectl delete pod <noime-pod>
kubectl delete pod nginx-pod
# deletar todos os pods
kubectl delete pods --all
# Entra no container com o modo interativo
kubectl exec -it <pod> -- bash
# Entra no container caso tenha mais de um no pod
kubectl exec -it <pod> --container <container-name> -- bash
# Para sair do container em uso
crtl + D
# Acessando api do kubenetes
kubectl proxy --porta=8085
# acesse no browser na porta definida
localhost:8085/apis
## Logs
kubectl logs -f --selector <label-key-value> -n <namespace>
#kubectl logs --selector app=ucontas-api -n ucontas-appPara criar pods de forma declarativa, primerio crie um arquivo usando a extenção .yaml
apiVersion: v1 # define a versão da api do kubernetes
kind: pod # define o tipo de recurso criado
metadata: # Meta dados que podesm ser adicionado ao pod
name: uni-pod # nome do pod
labels:
app: segundo-pod
spec: # epecificação do pod
containers: # containers que compoe o pod
- name: uni-nginx-container # nome do container
image: nginx:latest # imagem usada para criar o container
- name: uni-http-container
image: httpd:alpine
- name: db-noticias-container
image: aluracursos/mysql-db:1
env:
- name: "MYSQL_ROOT_PASSWORD"
value: "root"
- name: "MYSQL_DATABASE"
value: "test_db"
- name: "MYSQL_USER"
value: "user"
ports:
- containerPort: 3306# criado container
kubectl apply -f <nome-doa-arquivo>.yaml
# delete com arquivo deployment
kubctl delete -f <file>São abstrações para expor aplicações executando em um ou mais pods, que podem prover ips’s fixos para comunicação, alem de DNS e balanciamento de carga.
Podem ser dos tipos:
# Criando um novo servide
kubectl apply -f <file-do-svc>
# listando services criados
kubectl get services
# ou
kubectl get svc
# ver os detalhes dos services
kubectl describe service <nome-do-svc>
# ou
kubectl describe svc <nome-do-serviço>
# Deletar serviços
kubectl delete svc <service--name>
# deletar todos os pods
kubectl delete svc --allServe para fazer a cominucação entre diferentes pods dentro de um mesmo cluster. Usa labels para redirecionar o tafrico para os pods.
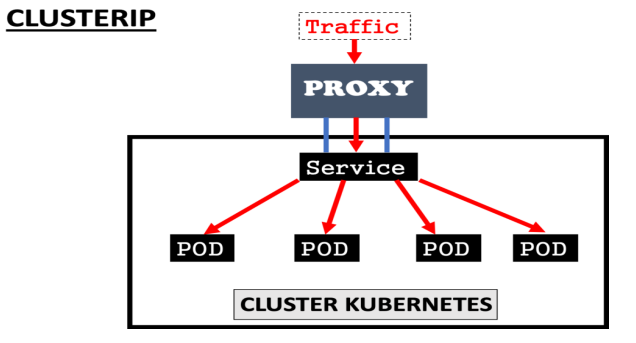
ex:
apiVersion: v1
kind: Service
metadata:
name: svc-pod-2
spec:
type: ClusterIP
selector:
app: segundo-pod # seletor de pod
ports:
- name: svc-pod-io
port: 80 # portra entrada - service
targetPort: 80 # porta do container / caso seja igual a port, não precisa informar
protocol: TCPNeste exemplo, cria um cluster ip que gerar um ip fixo para o pod com a seletor (label) app: segundo-po
# ver os detalhes dos services
kubectl get service <nome-do-svc>
kubectl describe service <nome-do-svc>ex:


Usado para permitir a comunicação com o mundo externo
apiVersion: v1
kind: Service
metadata:
name: svc-pod-1
spec:
type: NodePort
selector:
app: primeiro-pod
ports:
- port: 80 # porta do meu service
targetPort: 80 # porta do container / caso seja igual a port, não precisa informar
nodePort: 30001 # porta de acesso externo tem que esta no range 30000 a 32767# Mostra as configurações de forma extendida
kubeclt get svc -o wideex:

Para acessar o pod usando o nodePort dentro do cluster use:
curl 10.106.182.107:80
Para acessa externamente - linux
Se tiver no linux, para recuperar o ip mapeado para o cluster
kubectl get node -o wideex:


Para acessa externamente - windows
Use localhost:30001
Nada mais é do que um NodePort que permite a distribuição do trafico entres os pods de um container.
Ele é entregado com o serviço de Kuberbetes das nuvens, nele voce criar um arquivo e diz quais são os seletores e a partir dai o serviços de kubernets do provedor da nuvem gera um a instraestrutura de um loadbalance para que possamos acessa-los via web.
- Por serem um Load Balancer, também são um NodePort e ClusterIP ao mesmo tempo.
- Utilizam automaticamente os balanceadores de carga de cloud providers.

apiVersion: v1
kind: Service
metadata:
name: svc-lb-app-1
spec:
type: LoadBalancer
selector:
app: primeiro-pod
ports:
- port: 20
targetPort: 80kubectl apply -f <nome-arquivo> kubectl get svc -o wide
# ou
kubectl describe svc <svc-name>
Repare que o EXTERNAL-IP esta vazio, pois executamos localmente, se fosse num provedor, seria preenchiado com um ip para acesso web, repare também que foi gerado uma porta para acesso externo dentro da rede onde o cluster esta, semelhante ao NodePort.
Permite extrair as configuração especificas para tornar um pod genérico e reutilizável, com ele é possível reutilizar configurações e varios pods
apiVersion: v1
kind: ConfigMap
metadata:
name: db-config-map
data:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: test_db
MYSQL_USER: user
MYSQL_PASSWORD: pass kubectl apply -f <nome-arquivo>kubectl get configmapex:

Para descrever o configmap use:
kubectl describe configmap <nome-config-map>ex:

Há duas dorma de se fazer a importação
Mais verboso, e util quando se tem varios configMaps compartilhado
apiVersion: v1
kind: Pod
metadata:
name: db-noticias
labels:
app: db-noticias
spec:
containers:
- name: db-noticias-container
image: aluracursos/mysql-db:1
env:
- name: "MYSQL_ROOT_PASSWORD"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_ROOT_PASSWORD
- name: "MYSQL_DATABASE"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_DATABASE
- name: "MYSQL_USER"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_USER
- name: "MYSQL_PASSWORD"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_PASSWORD
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 3306 ex:

Menos verboso, usado quando o config map tem a maioria ou todas a variaveis (configurações) que o pod ira usar
apiVersion: v1
kind: Pod
metadata:
name: db-noticias
labels:
app: db-noticias
spec:
containers:
- name: db-noticias-container
image: aluracursos/mysql-db:1
envFrom:
- configMapRef:
name: db-config-map
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 3306ex:

Arquivos de exemplo dentro da pasta workspace/projeto-avançado
- recursos de disponibilidade
- ReplicasSets
- Deployments
- recursos de armazenamento
- Volumes
- Persistents Volumes
- Persistent Volume Claim
- Storage Classes


Estrutura que pode encapsular um ou mais pods, usada quando se quer manter alta disponibilidade, pois se um pod cair o replicaSet sobe outro automaticamente.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: portal-noticias-replicaset
spec:
template: # template a ser usado pelo replicaset
metadata:
name: portal-noticias
labels:
app: portal-noticias # label usada para identificar os pods
spec:
containers:
- name: portal-noticias-container
image: aluracursos/portal-noticias:1
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: portal-configmap
replicas: 3 # numeros de replicas que deve existir
selector: # serve pra dizer o kubernetes que ele deve gerenciar os pods com essa label
matchLabels:
app: portal-noticias 
caso delete algum pod do replicaSet ele automaticamente recriará um novo.
kubectl get replicasset
kubectl get rs
# ou se quiser mais detalhes
kubectl describe replicaset <nome>
kubectl describe rs <nome>
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod # deve ser igual ao labels do metadata do template
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:stable
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80kubectl apply -f <nome-arquivo> ex:

kubectl get deployments
# ou, caso queira mais detalhes use
kubectl describe deployments <nome>A diferencia que o deployment, permite adicionar outros recurso em um só arquivo, alem de ter uns comandos para controle de versionamento.
# Aplicar deployment
kubectl apply -f <nome-arquivo>
# Deletar deployment (deleta todos o recursos atrelados)
kubectl delete deployment <nome do deployment>
kubectl delete -f <nome-arquivo->
# ou
# Ver deployments
kubectl get deployments
# ou, caso queira mais detalhes use
kubectl describe deployments <nome>
# ver historico
kubectl rollout history deployment <nome-do-deployment>
# voltar pra uma versão
kubectl rollout undo deployment <nome-do-deploy> --to-revision=2Dica linux - crie alias
alias kubectl="minikube kubectl --" alias k="minikube kubectl --" funtion k-dploy-msg(){ echo "Adicionando ao deployment $1 a anotação : $2" kubectl annotate deployment $1 kubernetes.io/change-cause=$2 } alias k-hd="kubectl rollout history deployment "
- Historico de alterações - mostra o historico de alerações
kubectl rollout history deployment <nome-do-deployment>

obs: Deve ser passadoa flag –record no final do comando de apply
kubectl apply -f <arquivo-deployment> --record

- Altera mensagem de alteração
Quando fazemos o passo anterior, e vemos o historico, so vemos a linha do deplyment onde ouver a alteração, caso queiramos adicionar uma mensagem, mais amigavel, podemos após o apply dar o comando abaixo:
kubectl annotate deployment <nome-do-deploy> kubernetes.io/change-cause="Messagem que queremos"

Realizando o passo anterior podemos voltar versões, (fazer um rollback) com o comando:
kubectl rollout undo deployment <nome-do-deploy> --to-revision=2
link: https://kubernetes.io/docs/concepts/storage/volumes/
Semelhante aos volumes do docker, caso o container morrar os dados ficam armazenados no volume, a diferença aqui e que o ciclo de vida do volume no kubernetes dica atrelado a vida do pod, caso o pod tenha 2 container se um morrer, e for recriado, os dados ainda estaram lá, poré se o pod for distruido, os volumes serão perdidos.
ex:
apiVersion: apps/v1
kind: Pod
metadata:
name: pod-volume
spec:
containers:
- name: nginx-container
image: nginx:latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: segundo-volume
- name: jenkins
image: jenkins/jenkins:alpine
volumeMounts:
- mountPath: /volume-dentro-do-container
name: segundo-volume
volumes:
- name: segundo-volume
hostPath:
path: /tmp/bkp
type: DirectoryOrCreateo type do volume pode ser:
- Directory - Quando o diretorio já estiver criado.
- DirectoryOrCreate - Quando o diretorio não existir, o kubernets cria.
Para executar isso localmente no linux, você estará usando o minikube, que é um container docker que roda o kubernetes, por isso é necessario criar a pasta do mapeamento do volume (caso esteja usando o type do volume como directory) dentro do minikube , NÃO em sua maquina, para isso use os comandos abaixo:
# logar no minikube minikube ssh # criar a pasta cd /tmp mkdir bkp # Sair do minikuve crtl+d

A ideia de PV (persistence volume) é usar o mesmo conceito anterior, porem na nuvem, onde se criaria um volume e se linkaria esse volume com o pod, para isso é necessario criar um pv, que vai armazenar a conexão do volume criado na nuvem para ser usado no kubernetes
- Um PV é uma instância de armazenamento virtual que é incluída como um volume no cluster. O PV aponta para um dispositivo de armazenamento físico em sua conta na nuvem e resume a API que é usada para se comunicar com o dispositivo de armazenamento. Para montar um PV em um app, deve-se ter um PVC correspondente. Os PVs montados aparecem como uma pasta dentro do sistema de arquivos do contêiner.
# listando storage class existentes
kubectl get storageclass
#ou
kubectl get sc
# listar persistence volumes claim
kubectl get pvc
#listar persistence volume
kubectl get pvapiVersion: v1
kind: PersistVolume
metadata:
name: pv-1
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
gcePersistentDisk:
pdName: pv-disk
storageClassName: standardTipos de PersistentVolume são implementados como plugins. Atualmente o Kubernetes suporta os plugins abaixo:
awsElasticBlockStore- AWS Elastic Block Store (EBS)azureDisk- Azure DiskazureFile- Azure Filecephfs- CephFS volumecinder- Cinder (OpenStack block storage) (depreciado)csi- Container Storage Interface (CSI)fc- Fibre Channel (FC) storageflexVolume- FlexVolumeflocker- Flocker storagegcePersistentDisk- GCE Persistent Diskglusterfs- Glusterfs volumehostPath- HostPath volume (somente para teste de nó único; ISSO NÃO FUNCIONARÁ num cluster multi-nós; ao invés disso, considere a utilização de volumelocal.)iscsi- iSCSI (SCSI over IP) storagelocal- storage local montados nos nós.nfs- Network File System (NFS) storagephotonPersistentDisk- Controlador Photon para disco persistente. (Esse tipo de volume não funciona mais desde a removação do provedor de cloud correspondente.)portworxVolume- Volume Portworxquobyte- Volume Quobyterbd- Volume Rados Block Device (RBD)scaleIO- Volume ScaleIO (depreciado)storageos- Volume StorageOSvsphereVolume- Volume vSphere VMDK
Os modos de acesso são:
- ReadWriteOnce – o volume pode ser montado como leitura-escrita por um nó único
- ReadOnlyMany – o volume pode ser montado como somente-leitura por vários nós
- ReadWriteMany – o volume pode ser montado como leitura-escrita por vários nós
Na linha de comando, os modos de acesso ficam abreviados:
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- RWX - ReadWriteMany

Uma PVC é a solicitação para provisionar armazenamento persistente com um tipo e configuração específicos. Para especificar o tipo de armazenamento persistente que você deseja
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-1
spec:
accessModes:
- ReadWriteOnde
resources:
requests:
storage: 10Gi
storageClassName: standardpara linkar um pvc a pv, como pvc e uma “requisição de armazenamento” usa-se as especificações, ou seja, as especificações do volume contidos no pvc devem ser igual ao contido no pv.
apiVersion: v1
kind: Pod
metadata:
name: pod-pv
spec:
containers:
- name: nginx-container
image: nginx-latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: primeiro-pv
volumes:
- name: primeiro-pv
hostPath:
persistentVolumeClaim:
claimName: pvc-1
A diferença da item anteriror e que com um storage classes a criação do disco na nuvem e do persistente volume é feita automaticamente.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nome-sc
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
fstype: ext4
replication-type: noneapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-2
spec:
accessModes:
- ReadWriteOnde
resources:
requests:
storage: 10Gi
storageClassName: nome-scapiVersion: v1
kind: Pod
metadata:
name: pod-pv
spec:
containers:
- name: nginx-container
image: nginx-latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: primeiro-pv
volumes:
- name: primeiro-pv
hostPath:
persistentVolumeClaim:
claimName: pvc-2# listando storage class existentes
kubectl get storageclass
#ou
kubectl get sc
# listar persistence volumes claim
kubectl get pvc
#listar persistence volume
kubectl get pv
Bem similar a um Deployment, mas, ele é voltado para aplicações a Pods que devem manter o seu estado que eles são Stateful. Isso significa que quando um Pod reinicia ou falha por algum motivo dentro de um Stateful Set e volta a execução, o arquivo é mantido.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: systema-noticias-statefull-set
spec:
serviceName: svc-sistema-noticias
replicas: 2
selector:
matchLabels:
app: sistema-noticias
template:
metadata:
labels:
app: sistema-noticias
name: sistema-noticias
spec:
containers:
- name: sistema-noticias-container
image: aluracursos/sistema-noticias:1
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: sistema-configmap
volumeMounts:
- name: vl-imagem
mountPath: "/var/www/uploads"
- name: vl-sessao
mountPath: /tmp
volumes:
- name: vl-imagem
persistentVolumeClaim:
claimName: imagem-pvc
- name: vl-sessao
persistentVolumeClaim:
claimName: sessao-pvcvai criar a estrutura e vai manter os dados salvos no volumes atachados, use os comandos:
# Para aplicar kubectl apply -f <nome-file>
# imagem-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: imagem-pvc
spec:
resources:
requests:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
# sessao-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: sessao-pvc
spec:
resources:
requests:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnceSalve em arquivos com os determinados nomes e de o comando abaixo
# para aplicar
kubectl apply -f <nome>
# para ver os pvcs criados
kubectl get pvc
# para ver os pvs criados
kubectl get pv
# para ver o storage classe existente
kubectl get sco kubernetes consegue gerenciar por si proprio o pod, porem os container dentro (“a aplicação”) ele precisa de ajuda pra gerenciar se esta vivo, par isso ele utiliza o liveness e o readiness.
- O Kubernetes nem sempre tem como saber se a aplicação está saudável
- Podemos criar critérios para definir se a aplicação está saudável através de probes
- Como criar LivenessProbes com o campo
livenessProbe- LivenessProbes podem fazer a verificação em diferentes intervalos de tempo via HTTP
- Como criar ReadinessProbes com o campo
readinessProbe- ReadinessProbes podem fazer a verificação em diferentes intervalos de tempo via HTTP
- LivenessProbes são para saber se a aplicação está saudável e/ou se deve ser reiniciada, enquanto ReadinessProbes são para saber se a aplicação já está pronta para receber requisições depois de iniciar
- Além do HTTP, também podemos fazer verificações via TCP
Entenda como forma de checagem se o contanier tem uma boa saude, declaramos junto a declaração co container.
livenessProbe:
httpGet: # metodo que vamos usar
path: / # path aonde vamos bater com a requisição
port: 80 # porta do container
periodSeconds: 10 # de quanto em quanto tempo vamos validar em segundos
failureThreshold: 3 # quandos erros vamos aceitar antes de reiniciar o container
initialDelaySeconds: 20 # Delay inicial para que o container possa subirex:

Entenda como a prova de que um container pode receber requisições, que que ele esta “Ready” (pronto) para começar a receber requisições.
readinessProbe:
httpGet: # metodo que vamos usar para validar se o caontainer esta pronto
path: / # path aonde vamos bater com a requisição
port: 80 # porta do container
periodSeconds: 10 # de quanto em quanto tempo vamos validar em segundos
failureThreshold: 5 # quanto erros são tentativas são toleraveis aonte de começar a madar requisição para o container
initialDelaySeconds: 3 # Delay inicial após o container subir, para iniciar as validações se o container esta prontoEX:

Permite escalara os pods deacordo com a demanda
- HPA - Horizontal pod autpscale
resources:
limits:
memory: 128Mi
cpu: 500m
requests:
cpu: 10m # mili core cpu
memory: 128Miex:

apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: primeiro-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: portal-noticias-deployment
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 20# listar configurações de HPA
kubectl get hpaObs: Apenas isso não sera necessario pra que funcione, é necessario configurar um servidor de metricas vai garadar as metricas de consumo. para isso usamos o arquivo abaixo:
--- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:aggregated-metrics-reader labels: rbac.authorization.k8s.io/aggregate-to-view: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-admin: "true" rules: - apiGroups: ["metrics.k8s.io"] resources: ["pods", "nodes"] verbs: ["get", "list", "watch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: apiregistration.k8s.io/v1beta1 kind: APIService metadata: name: v1beta1.metrics.k8s.io spec: service: name: metrics-server namespace: kube-system group: metrics.k8s.io version: v1beta1 insecureSkipTLSVerify: true groupPriorityMinimum: 100 versionPriority: 100 --- apiVersion: v1 kind: ServiceAccount metadata: name: metrics-server namespace: kube-system --- apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server namespace: kube-system labels: k8s-app: metrics-server spec: selector: matchLabels: k8s-app: metrics-server template: metadata: name: metrics-server labels: k8s-app: metrics-server spec: serviceAccountName: metrics-server volumes: # mount in tmp so we can safely use from-scratch images and/or read-only containers - name: tmp-dir emptyDir: {} containers: - name: metrics-server image: k8s.gcr.io/metrics-server/metrics-server:v0.3.7 imagePullPolicy: IfNotPresent args: - --cert-dir=/tmp - --secure-port=4443 ports: - name: main-port containerPort: 4443 protocol: TCP securityContext: readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - name: tmp-dir mountPath: /tmp nodeSelector: kubernetes.io/os: linux --- apiVersion: v1 kind: Service metadata: name: metrics-server namespace: kube-system labels: kubernetes.io/name: "Metrics-server" kubernetes.io/cluster-service: "true" spec: selector: k8s-app: metrics-server ports: - port: 443 protocol: TCP targetPort: main-port --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces - configmaps verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system
Links:
Helm e um gerenciador de pacotes de cluster kunerntes, imagine que num deploys de apenas um item eu tenha os aquivos abaixo

Nesse caso teremos que dar 5
kubectl apply -fpara fazer deploy da nossa aplicação, ou seja realizar o controle manual do processo. Para resolver isso é que o HELM foi criado.
Pense em chart com um pacote de versão que contem todos os arquivos .yaml que compoem aquela versão.
ex:


#-----------------------------------------------------------------------------------------------
## Kind
## link: https://kind.sigs.k8s.io/docs/user/quick-start/#installation
## Usado para criar cluter kubernets
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.16.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
# Cria aum cluter
kind create cluster
# cria com nome
kind create cluster --name uni-cluster
# cria cluster via arquivo <ver abaixo arquivo cluster king>
kind create cluster --config=config.yaml
# Listar os cluster
kind get clusters
# Delete lcluster
kind delete cluster -n <name>
#-----------------------------------------------------------------------------------------------
# Listando contextos possiveis
cat ~/.kube/config
kubcetl config get-cluster
# setar um contexto
kubectl cluster-info --context <contexto>
kubcetl config use-context <contexto>
# Setando o Kind como cluster padrão no kubctl
kubectl cluster-info --context kind-kind
kubcetl config use-context kind-kind
# Setando o minikube como cluster padrão no kubctl
kubectl cluster-info --context minikube
# Setar namespace padrão
kubectl config set-context --current --namespace=<namespace>kind: Pod
apiVersion: v1
metadata:
name: foo
labels:
app: foo
spec:
containers:
- name: foo
image: hashicorp/http-echo:0.2.3
args:
- "-text=foo"
ports:
- containerPort: 5678
---
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
type: NodePort
ports:
- name: http
nodePort: 30950
port: 5678
selector:
app: fookind create cluster --config=config.yamlIstio é um service mesh, que nada mais que é uma camada adicionada junto as aplicações deployadas no kubernetes que permite gerenciar a comunicação dos serviços num sistema distribuído.
Um service mesh gerencia toda a comunicação serviço a serviço em um sistema de software distribuído (potencialmente baseado em microservices). Isso é feito normalmente por meio do uso de proxies “laterais (sidecar)” que são implantados ao lado de cada serviço através do qual todo o tráfego é roteado de forma transparente;
Com o Istio podemos resolver os problemas:
Existem outros services mesh, Linkerd, Istio, Consul, Kuma e Maesh.
link: instale o istio
# Instalar istio no kunbernetes - veja outros profiles: https://istio.io/latest/docs/setup/additional-setup/config-profiles/
istioctl install --set profile=demo -y
# comandos uteis
# lista os namespaces
kubectl get namespaces
# lista os pods de um namespace
kubectl get pods -n istio-system
kgp -n istio-system
# lista os services de um namespace
kubectl get svc -n istio-system
kgs -n istio-system
# instalar addons
kubectl apply -f <istio-istall-folder>/samples/addons
kubectl apply -f ~/Documents/programs/istio-1.14.3/samples/addons
# Acessar dash kiali
istioctl dashboard kiali
# abre serviços
misinikube service <nome do serviço>
# configurar uma porta local pra usar no localhost
kubectl port-forward svc/<nome-serviço> -n <namespace-serviço> <porta-local>:<porta-serviço>Após fazer isso automaticamente o istio vai subir no pod um container de proxy.
# use para listar as lables de um namespace
kubectl get ns <namespace> --show-labels=true
kubectl get ns ucontas-app --show-labels=true
# Use para ativar o istion no namespace
kubectl label namespace <nome-namespace> istio-injection=enabled
kubectl label namespace ucontas-app istio-injection=enabled
# E reciso reiniciar os pod para que seja adicionados os sidecar
kubectl delete pods --all -n <namespace>
kubectl delete pods --all -n ucontas-appLink: https://www.infoq.com/br/articles/service-mesh-ultimate-guide/
Aplicação de continuos deploy, usada para realizar o deploy de aplicações no kubernetes.
Estamos acostumado com o formato padrão de pipeline do jenkins onde temos um fluxo único para o CI e CD. No caso do argoCD temos uma pipeline especifica para cada itens, sendo uma especifica para o processo de Continuos Delivery que é usada pelo argo.
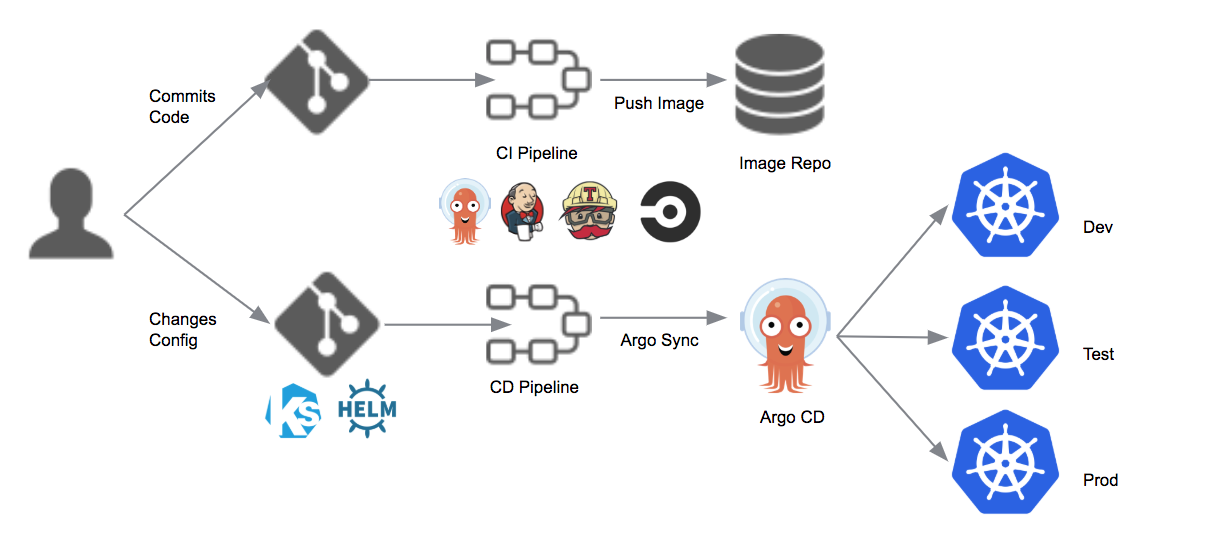
Diferentemente de outras ferramentas de Continuos delivery o ArgoCD tem uma particularidade que é o fato dele ser implantado no cluster do kubernetes. Na verdade ele é uma extensão do kubernetes, pois usa a maioria da ferramentas dele.
- Isso tem diversas vantagens tais como:
- Visibilidade do processo, coisa que o Jenkins não tem por ser um processo externo.
- Tem um interface gráfica que mostra o processo em tempo real.
Neste informamos qual:
- vai ser no repo onde vão estar os deployments.
- vai ser o cluster kubernets, onde serão aplicados os deployments.
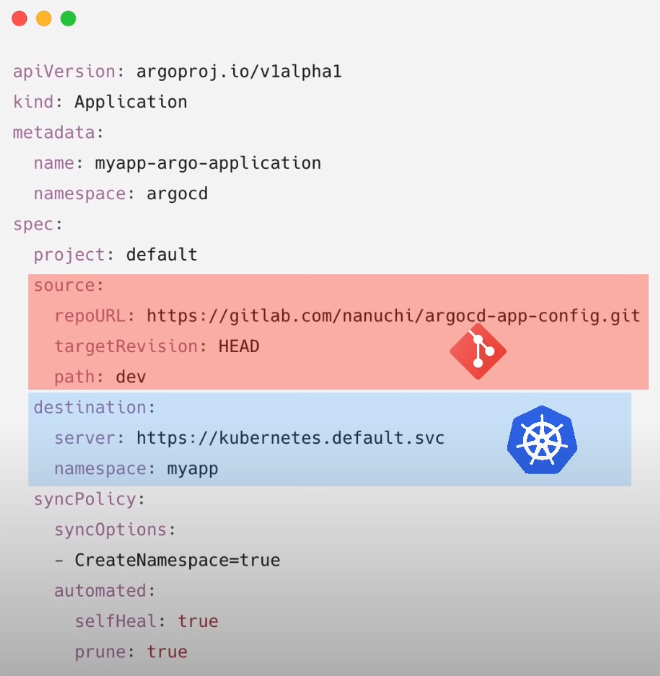
# cria o namespace do argo
kubectl create namespace <namespace>
kubectl create namespace argocd
# Para instalar o argo no namespace
kubectl apply -n <namespace> -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# Para remover argo
kubectl delete -n <namespace> -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
kubectl delete -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
## Acessando externamente
# 1 - Para acessar mude o serviço do argo-serve com o comando abaixo
kubectl patch svc argocd-server -n <namespace> -p '{"spec": {"type": "LoadBalancer"}}'
kubectl patch svc argocd-server -n argocd -p '{"spec": {"type": "LoadBalancer"}}'
# 1.1 - depois de o comando para abrir o serviço
minikube service argocd-server -n <namespace>
minikube service argocd-server -n argocd
# 1.3 Ou use o comando abaixo para liberar a porta
kubectl port-forward svc/argocd-server -n <namespace> 8080:443
kubectl port-forward svc/argocd-server -n argocd 8080:443
## Login Via UI
# Usuario padrão é admin
# Para pegar a senha use
kubectl -n <namespace> get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
## Login via CLI
# instale o cli - https://argo-cd.readthedocs.io/en/stable/cli_installation/
# Usuario padrão é admin
# Para pegar a senha use
kubectl -n <namespace> get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
# Use o comando abaixo - ARGOCD_SERVER é o ip e porta exporto externamente
argocd login <ARGOCD_SERVER>
argocd login 192.168.49.2:30634
# Para altera a senha #Nova senha - unisenha
argocd account update-password
# -------------------Register A Cluster To Deploy Apps To
# Listando os contextos validos
kubectl config get-contexts -o name
# Configurando um contexto para deploy
argocd cluster add <contexto>
argocd cluster add minikubeUser: admin
Senha: unisenha
- Trabalha com metricas e alertas para monitorar sistemas.
- Toolkit de monitoramento e alerta de sistema open source.
- Criado pela SoundCloud, Agora faz parte da Cloud Native Computer Foundation.
- Captura e armazenamena dados em formatos dimensionais.
- Tem coletas poderosas com o PromQL.
- Usado em conjunto com o Grafana.
- Tem diversas soluções para integrações.
há duas forma de funcionamento:
Sistema baseado em Pull.
Sistema baseado em Push.
Exports

Na arquitetura do Prometheus temos:

Acesse a pasta treinando
De os comando abaixo para subir o prometheus.
# Para subir os container
docker-compose up -d
# Para ver os logs do prometheus
docker-compose logs -f prometheus
# Para ver os logs do node export
docker-compose logs -f node-exportercontinuar -> https://prometheus.io/docs/concepts/metric_types/