DevOps Notes
Warning
Em construção
Paginas:
Em construção
Paginas:
Paginas:

Um cluster é composto por:






Para rodar o kubernets localmente, usamos o minikube, para baixa-lo acesse:
## Arquivo de configuração
## Minikube
## link: https://minikube.sigs.k8s.io/docs/start/
### Install minikube
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
### Start
minikube start
### Use
minikube kubectl -- get nodes
### Create alias dentro do .bashrc
alias kubectl="minikube kubectl --"
#-----------------------------------------------------------------------------------------------
## há a opç
#-----------------------------------------------------------------------------------------------
# Listando contextos possiveis
cat ~/.kube/config
kubcetl config get-cluster
# setar um contexto
kubectl cluster-info --context <contexto>
kubcetl config use-context <contexto>
# Setando o Kind como cluster padrão no kubctl
kubectl cluster-info --context kind-kind
kubcetl config use-context kind-kind
# Setando o minikube como cluster padrão no kubctl
kubectl cluster-info --context minikube
# Setar namespace padrão
kubectl config set-context --current --namespace=<namespace>
kubectl config set-context --current --namespace=ucontas-app
#-----------------------------------------------------------------------------------------------
### KUBERNETES (KUBECTL)
alias k="kubectl"
alias ka="kubectl apply -f"
alias kl="kubectl logs"
alias kdd="kubectl describe deployment"
alias kdp="kubectl describe pod"
alias kds="kubectl describe service"
alias kei="kubectl exec -it"
alias kgd="kubectl get deployments"
alias kgp="kubectl get pods"
alias kgs="kubectl get services"
alias krrd="kubectl rollout restart deployment"
alias kdad="kubectl delete --all deployments"
alias kdap="kubectl delete --all pods"
alias kdas="kubectl delete --all services"
### DOCKER
alias d="docker"
alias dc="docker compose"
alias di="docker images"
alias dl="docker logs"
alias db="docker build -t"
alias dps="docker ps"
alias dcu="docker compose up"
alias dcc="docker compose config"
alias drc="docker rm $(docker ps -a -q)"
alias dsa="docker kill $(docker ps -q)"
alias dsp="docker system prune -a --volumes"
alias dcps="docker compose ps"
alias dcenv="docker compose --env-file"
alias usedd="docker context use docker-desktop"
alias usede="docker context use default"
### Dasboard
minikube dashboardSegue alguns comandos uteis usados
# Recuperas os nodes criados
kubectl get nodes
# abre serviços
minikube service <nome do serviço>
# Listar pods
kubectl get pods
# listar pods com detalhes
kubctl get pods -o wide
# Acompanhar status pod
kubectl get pods --watch
# Criar novo pod
kubectl run <nome-pode> --image=<imagem>:<versão>
# - ex:
kubectl run nginx-pod --image=nginx:latest
# Descrever informações do pod
kubectl describe <nome-pode>
# - ex
kubectl describe pod nginx-pod
# Editar pod
kubectl edit pod <nome-pod>
kubectl edit pod nginx-pod
# deletar pod
kubectl delete pod <noime-pod>
kubectl delete pod nginx-pod
# deletar todos os pods
kubectl delete pods --all
# Entra no container com o modo interativo
kubectl exec -it <pod> -- bash
# Entra no container caso tenha mais de um no pod
kubectl exec -it <pod> --container <container-name> -- bash
# Para sair do container em uso
crtl + D
# Acessando api do kubenetes
kubectl proxy --porta=8085
# acesse no browser na porta definida
localhost:8085/apis
## Logs
kubectl logs -f --selector <label-key-value> -n <namespace>
#kubectl logs --selector app=ucontas-api -n ucontas-appPara criar pods de forma declarativa, primerio crie um arquivo usando a extenção .yaml
apiVersion: v1 # define a versão da api do kubernetes
kind: pod # define o tipo de recurso criado
metadata: # Meta dados que podesm ser adicionado ao pod
name: uni-pod # nome do pod
labels:
app: segundo-pod
spec: # epecificação do pod
containers: # containers que compoe o pod
- name: uni-nginx-container # nome do container
image: nginx:latest # imagem usada para criar o container
- name: uni-http-container
image: httpd:alpine
- name: db-noticias-container
image: aluracursos/mysql-db:1
env:
- name: "MYSQL_ROOT_PASSWORD"
value: "root"
- name: "MYSQL_DATABASE"
value: "test_db"
- name: "MYSQL_USER"
value: "user"
ports:
- containerPort: 3306# criado container
kubectl apply -f <nome-doa-arquivo>.yaml
# delete com arquivo deployment
kubctl delete -f <file>São abstrações para expor aplicações executando em um ou mais pods, que podem prover ips’s fixos para comunicação, alem de DNS e balanciamento de carga.
Podem ser dos tipos:
# Criando um novo servide
kubectl apply -f <file-do-svc>
# listando services criados
kubectl get services
# ou
kubectl get svc
# ver os detalhes dos services
kubectl describe service <nome-do-svc>
# ou
kubectl describe svc <nome-do-serviço>
# Deletar serviços
kubectl delete svc <service--name>
# deletar todos os pods
kubectl delete svc --allServe para fazer a cominucação entre diferentes pods dentro de um mesmo cluster. Usa labels para redirecionar o tafrico para os pods.
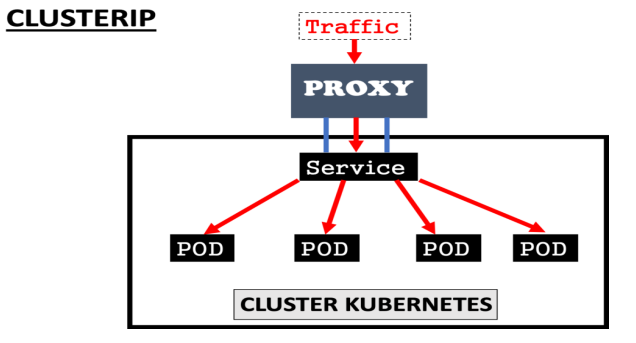
ex:
apiVersion: v1
kind: Service
metadata:
name: svc-pod-2
spec:
type: ClusterIP
selector:
app: segundo-pod # seletor de pod
ports:
- name: svc-pod-io
port: 80 # portra entrada - service
targetPort: 80 # porta do container / caso seja igual a port, não precisa informar
protocol: TCPNeste exemplo, cria um cluster ip que gerar um ip fixo para o pod com a seletor (label) app: segundo-po
# ver os detalhes dos services
kubectl get service <nome-do-svc>
kubectl describe service <nome-do-svc>ex:


Usado para permitir a comunicação com o mundo externo
apiVersion: v1
kind: Service
metadata:
name: svc-pod-1
spec:
type: NodePort
selector:
app: primeiro-pod
ports:
- port: 80 # porta do meu service
targetPort: 80 # porta do container / caso seja igual a port, não precisa informar
nodePort: 30001 # porta de acesso externo tem que esta no range 30000 a 32767# Mostra as configurações de forma extendida
kubeclt get svc -o wideex:

Para acessar o pod usando o nodePort dentro do cluster use:
curl 10.106.182.107:80
Para acessa externamente - linux
Se tiver no linux, para recuperar o ip mapeado para o cluster
kubectl get node -o wideex:


Para acessa externamente - windows
Use localhost:30001
Nada mais é do que um NodePort que permite a distribuição do trafico entres os pods de um container.
Ele é entregado com o serviço de Kuberbetes das nuvens, nele voce criar um arquivo e diz quais são os seletores e a partir dai o serviços de kubernets do provedor da nuvem gera um a instraestrutura de um loadbalance para que possamos acessa-los via web.
- Por serem um Load Balancer, também são um NodePort e ClusterIP ao mesmo tempo.
- Utilizam automaticamente os balanceadores de carga de cloud providers.

apiVersion: v1
kind: Service
metadata:
name: svc-lb-app-1
spec:
type: LoadBalancer
selector:
app: primeiro-pod
ports:
- port: 20
targetPort: 80kubectl apply -f <nome-arquivo> kubectl get svc -o wide
# ou
kubectl describe svc <svc-name>
Repare que o EXTERNAL-IP esta vazio, pois executamos localmente, se fosse num provedor, seria preenchiado com um ip para acesso web, repare também que foi gerado uma porta para acesso externo dentro da rede onde o cluster esta, semelhante ao NodePort.
Permite extrair as configuração especificas para tornar um pod genérico e reutilizável, com ele é possível reutilizar configurações e varios pods
apiVersion: v1
kind: ConfigMap
metadata:
name: db-config-map
data:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: test_db
MYSQL_USER: user
MYSQL_PASSWORD: pass kubectl apply -f <nome-arquivo>kubectl get configmapex:

Para descrever o configmap use:
kubectl describe configmap <nome-config-map>ex:

Há duas dorma de se fazer a importação
Mais verboso, e util quando se tem varios configMaps compartilhado
apiVersion: v1
kind: Pod
metadata:
name: db-noticias
labels:
app: db-noticias
spec:
containers:
- name: db-noticias-container
image: aluracursos/mysql-db:1
env:
- name: "MYSQL_ROOT_PASSWORD"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_ROOT_PASSWORD
- name: "MYSQL_DATABASE"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_DATABASE
- name: "MYSQL_USER"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_USER
- name: "MYSQL_PASSWORD"
valueFrom:
configMapKeyRef:
name: db-config-map
key: MYSQL_PASSWORD
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 3306 ex:

Menos verboso, usado quando o config map tem a maioria ou todas a variaveis (configurações) que o pod ira usar
apiVersion: v1
kind: Pod
metadata:
name: db-noticias
labels:
app: db-noticias
spec:
containers:
- name: db-noticias-container
image: aluracursos/mysql-db:1
envFrom:
- configMapRef:
name: db-config-map
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 3306ex:

Arquivos de exemplo dentro da pasta workspace/projeto-avançado
- recursos de disponibilidade
- ReplicasSets
- Deployments
- recursos de armazenamento
- Volumes
- Persistents Volumes
- Persistent Volume Claim
- Storage Classes


Estrutura que pode encapsular um ou mais pods, usada quando se quer manter alta disponibilidade, pois se um pod cair o replicaSet sobe outro automaticamente.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: portal-noticias-replicaset
spec:
template: # template a ser usado pelo replicaset
metadata:
name: portal-noticias
labels:
app: portal-noticias # label usada para identificar os pods
spec:
containers:
- name: portal-noticias-container
image: aluracursos/portal-noticias:1
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: portal-configmap
replicas: 3 # numeros de replicas que deve existir
selector: # serve pra dizer o kubernetes que ele deve gerenciar os pods com essa label
matchLabels:
app: portal-noticias 
caso delete algum pod do replicaSet ele automaticamente recriará um novo.
kubectl get replicasset
kubectl get rs
# ou se quiser mais detalhes
kubectl describe replicaset <nome>
kubectl describe rs <nome>
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod # deve ser igual ao labels do metadata do template
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:stable
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80kubectl apply -f <nome-arquivo> ex:

kubectl get deployments
# ou, caso queira mais detalhes use
kubectl describe deployments <nome>A diferencia que o deployment, permite adicionar outros recurso em um só arquivo, alem de ter uns comandos para controle de versionamento.
# Aplicar deployment
kubectl apply -f <nome-arquivo>
# Deletar deployment (deleta todos o recursos atrelados)
kubectl delete deployment <nome do deployment>
kubectl delete -f <nome-arquivo->
# ou
# Ver deployments
kubectl get deployments
# ou, caso queira mais detalhes use
kubectl describe deployments <nome>
# ver historico
kubectl rollout history deployment <nome-do-deployment>
# voltar pra uma versão
kubectl rollout undo deployment <nome-do-deploy> --to-revision=2Dica linux - crie alias
alias kubectl="minikube kubectl --" alias k="minikube kubectl --" funtion k-dploy-msg(){ echo "Adicionando ao deployment $1 a anotação : $2" kubectl annotate deployment $1 kubernetes.io/change-cause=$2 } alias k-hd="kubectl rollout history deployment "
- Historico de alterações - mostra o historico de alerações
kubectl rollout history deployment <nome-do-deployment>

obs: Deve ser passadoa flag –record no final do comando de apply
kubectl apply -f <arquivo-deployment> --record

- Altera mensagem de alteração
Quando fazemos o passo anterior, e vemos o historico, so vemos a linha do deplyment onde ouver a alteração, caso queiramos adicionar uma mensagem, mais amigavel, podemos após o apply dar o comando abaixo:
kubectl annotate deployment <nome-do-deploy> kubernetes.io/change-cause="Messagem que queremos"

Realizando o passo anterior podemos voltar versões, (fazer um rollback) com o comando:
kubectl rollout undo deployment <nome-do-deploy> --to-revision=2
link: https://kubernetes.io/docs/concepts/storage/volumes/
Semelhante aos volumes do docker, caso o container morrar os dados ficam armazenados no volume, a diferença aqui e que o ciclo de vida do volume no kubernetes dica atrelado a vida do pod, caso o pod tenha 2 container se um morrer, e for recriado, os dados ainda estaram lá, poré se o pod for distruido, os volumes serão perdidos.
ex:
apiVersion: apps/v1
kind: Pod
metadata:
name: pod-volume
spec:
containers:
- name: nginx-container
image: nginx:latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: segundo-volume
- name: jenkins
image: jenkins/jenkins:alpine
volumeMounts:
- mountPath: /volume-dentro-do-container
name: segundo-volume
volumes:
- name: segundo-volume
hostPath:
path: /tmp/bkp
type: DirectoryOrCreateo type do volume pode ser:
- Directory - Quando o diretorio já estiver criado.
- DirectoryOrCreate - Quando o diretorio não existir, o kubernets cria.
Para executar isso localmente no linux, você estará usando o minikube, que é um container docker que roda o kubernetes, por isso é necessario criar a pasta do mapeamento do volume (caso esteja usando o type do volume como directory) dentro do minikube , NÃO em sua maquina, para isso use os comandos abaixo:
# logar no minikube minikube ssh # criar a pasta cd /tmp mkdir bkp # Sair do minikuve crtl+d

A ideia de PV (persistence volume) é usar o mesmo conceito anterior, porem na nuvem, onde se criaria um volume e se linkaria esse volume com o pod, para isso é necessario criar um pv, que vai armazenar a conexão do volume criado na nuvem para ser usado no kubernetes
- Um PV é uma instância de armazenamento virtual que é incluída como um volume no cluster. O PV aponta para um dispositivo de armazenamento físico em sua conta na nuvem e resume a API que é usada para se comunicar com o dispositivo de armazenamento. Para montar um PV em um app, deve-se ter um PVC correspondente. Os PVs montados aparecem como uma pasta dentro do sistema de arquivos do contêiner.
# listando storage class existentes
kubectl get storageclass
#ou
kubectl get sc
# listar persistence volumes claim
kubectl get pvc
#listar persistence volume
kubectl get pvapiVersion: v1
kind: PersistVolume
metadata:
name: pv-1
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
gcePersistentDisk:
pdName: pv-disk
storageClassName: standardTipos de PersistentVolume são implementados como plugins. Atualmente o Kubernetes suporta os plugins abaixo:
awsElasticBlockStore- AWS Elastic Block Store (EBS)azureDisk- Azure DiskazureFile- Azure Filecephfs- CephFS volumecinder- Cinder (OpenStack block storage) (depreciado)csi- Container Storage Interface (CSI)fc- Fibre Channel (FC) storageflexVolume- FlexVolumeflocker- Flocker storagegcePersistentDisk- GCE Persistent Diskglusterfs- Glusterfs volumehostPath- HostPath volume (somente para teste de nó único; ISSO NÃO FUNCIONARÁ num cluster multi-nós; ao invés disso, considere a utilização de volumelocal.)iscsi- iSCSI (SCSI over IP) storagelocal- storage local montados nos nós.nfs- Network File System (NFS) storagephotonPersistentDisk- Controlador Photon para disco persistente. (Esse tipo de volume não funciona mais desde a removação do provedor de cloud correspondente.)portworxVolume- Volume Portworxquobyte- Volume Quobyterbd- Volume Rados Block Device (RBD)scaleIO- Volume ScaleIO (depreciado)storageos- Volume StorageOSvsphereVolume- Volume vSphere VMDK
Os modos de acesso são:
- ReadWriteOnce – o volume pode ser montado como leitura-escrita por um nó único
- ReadOnlyMany – o volume pode ser montado como somente-leitura por vários nós
- ReadWriteMany – o volume pode ser montado como leitura-escrita por vários nós
Na linha de comando, os modos de acesso ficam abreviados:
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- RWX - ReadWriteMany

Uma PVC é a solicitação para provisionar armazenamento persistente com um tipo e configuração específicos. Para especificar o tipo de armazenamento persistente que você deseja
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-1
spec:
accessModes:
- ReadWriteOnde
resources:
requests:
storage: 10Gi
storageClassName: standardpara linkar um pvc a pv, como pvc e uma “requisição de armazenamento” usa-se as especificações, ou seja, as especificações do volume contidos no pvc devem ser igual ao contido no pv.
apiVersion: v1
kind: Pod
metadata:
name: pod-pv
spec:
containers:
- name: nginx-container
image: nginx-latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: primeiro-pv
volumes:
- name: primeiro-pv
hostPath:
persistentVolumeClaim:
claimName: pvc-1
A diferença da item anteriror e que com um storage classes a criação do disco na nuvem e do persistente volume é feita automaticamente.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nome-sc
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
fstype: ext4
replication-type: noneapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-2
spec:
accessModes:
- ReadWriteOnde
resources:
requests:
storage: 10Gi
storageClassName: nome-scapiVersion: v1
kind: Pod
metadata:
name: pod-pv
spec:
containers:
- name: nginx-container
image: nginx-latest
volumeMounts:
- mountPath: /volume-dentro-do-container
name: primeiro-pv
volumes:
- name: primeiro-pv
hostPath:
persistentVolumeClaim:
claimName: pvc-2# listando storage class existentes
kubectl get storageclass
#ou
kubectl get sc
# listar persistence volumes claim
kubectl get pvc
#listar persistence volume
kubectl get pv
Bem similar a um Deployment, mas, ele é voltado para aplicações a Pods que devem manter o seu estado que eles são Stateful. Isso significa que quando um Pod reinicia ou falha por algum motivo dentro de um Stateful Set e volta a execução, o arquivo é mantido.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: systema-noticias-statefull-set
spec:
serviceName: svc-sistema-noticias
replicas: 2
selector:
matchLabels:
app: sistema-noticias
template:
metadata:
labels:
app: sistema-noticias
name: sistema-noticias
spec:
containers:
- name: sistema-noticias-container
image: aluracursos/sistema-noticias:1
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: sistema-configmap
volumeMounts:
- name: vl-imagem
mountPath: "/var/www/uploads"
- name: vl-sessao
mountPath: /tmp
volumes:
- name: vl-imagem
persistentVolumeClaim:
claimName: imagem-pvc
- name: vl-sessao
persistentVolumeClaim:
claimName: sessao-pvcvai criar a estrutura e vai manter os dados salvos no volumes atachados, use os comandos:
# Para aplicar kubectl apply -f <nome-file>
# imagem-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: imagem-pvc
spec:
resources:
requests:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
# sessao-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: sessao-pvc
spec:
resources:
requests:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnceSalve em arquivos com os determinados nomes e de o comando abaixo
# para aplicar
kubectl apply -f <nome>
# para ver os pvcs criados
kubectl get pvc
# para ver os pvs criados
kubectl get pv
# para ver o storage classe existente
kubectl get sco kubernetes consegue gerenciar por si proprio o pod, porem os container dentro (“a aplicação”) ele precisa de ajuda pra gerenciar se esta vivo, par isso ele utiliza o liveness e o readiness.
- O Kubernetes nem sempre tem como saber se a aplicação está saudável
- Podemos criar critérios para definir se a aplicação está saudável através de probes
- Como criar LivenessProbes com o campo
livenessProbe- LivenessProbes podem fazer a verificação em diferentes intervalos de tempo via HTTP
- Como criar ReadinessProbes com o campo
readinessProbe- ReadinessProbes podem fazer a verificação em diferentes intervalos de tempo via HTTP
- LivenessProbes são para saber se a aplicação está saudável e/ou se deve ser reiniciada, enquanto ReadinessProbes são para saber se a aplicação já está pronta para receber requisições depois de iniciar
- Além do HTTP, também podemos fazer verificações via TCP
Entenda como forma de checagem se o contanier tem uma boa saude, declaramos junto a declaração co container.
livenessProbe:
httpGet: # metodo que vamos usar
path: / # path aonde vamos bater com a requisição
port: 80 # porta do container
periodSeconds: 10 # de quanto em quanto tempo vamos validar em segundos
failureThreshold: 3 # quandos erros vamos aceitar antes de reiniciar o container
initialDelaySeconds: 20 # Delay inicial para que o container possa subirex:

Entenda como a prova de que um container pode receber requisições, que que ele esta “Ready” (pronto) para começar a receber requisições.
readinessProbe:
httpGet: # metodo que vamos usar para validar se o caontainer esta pronto
path: / # path aonde vamos bater com a requisição
port: 80 # porta do container
periodSeconds: 10 # de quanto em quanto tempo vamos validar em segundos
failureThreshold: 5 # quanto erros são tentativas são toleraveis aonte de começar a madar requisição para o container
initialDelaySeconds: 3 # Delay inicial após o container subir, para iniciar as validações se o container esta prontoEX:

Permite escalara os pods deacordo com a demanda
- HPA - Horizontal pod autpscale
resources:
limits:
memory: 128Mi
cpu: 500m
requests:
cpu: 10m # mili core cpu
memory: 128Miex:

apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: primeiro-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: portal-noticias-deployment
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 20# listar configurações de HPA
kubectl get hpaObs: Apenas isso não sera necessario pra que funcione, é necessario configurar um servidor de metricas vai garadar as metricas de consumo. para isso usamos o arquivo abaixo:
--- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:aggregated-metrics-reader labels: rbac.authorization.k8s.io/aggregate-to-view: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-admin: "true" rules: - apiGroups: ["metrics.k8s.io"] resources: ["pods", "nodes"] verbs: ["get", "list", "watch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: apiregistration.k8s.io/v1beta1 kind: APIService metadata: name: v1beta1.metrics.k8s.io spec: service: name: metrics-server namespace: kube-system group: metrics.k8s.io version: v1beta1 insecureSkipTLSVerify: true groupPriorityMinimum: 100 versionPriority: 100 --- apiVersion: v1 kind: ServiceAccount metadata: name: metrics-server namespace: kube-system --- apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server namespace: kube-system labels: k8s-app: metrics-server spec: selector: matchLabels: k8s-app: metrics-server template: metadata: name: metrics-server labels: k8s-app: metrics-server spec: serviceAccountName: metrics-server volumes: # mount in tmp so we can safely use from-scratch images and/or read-only containers - name: tmp-dir emptyDir: {} containers: - name: metrics-server image: k8s.gcr.io/metrics-server/metrics-server:v0.3.7 imagePullPolicy: IfNotPresent args: - --cert-dir=/tmp - --secure-port=4443 ports: - name: main-port containerPort: 4443 protocol: TCP securityContext: readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - name: tmp-dir mountPath: /tmp nodeSelector: kubernetes.io/os: linux --- apiVersion: v1 kind: Service metadata: name: metrics-server namespace: kube-system labels: kubernetes.io/name: "Metrics-server" kubernetes.io/cluster-service: "true" spec: selector: k8s-app: metrics-server ports: - port: 443 protocol: TCP targetPort: main-port --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces - configmaps verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system
Links:
Helm e um gerenciador de pacotes de cluster kunerntes, imagine que num deploys de apenas um item eu tenha os aquivos abaixo

Nesse caso teremos que dar 5
kubectl apply -fpara fazer deploy da nossa aplicação, ou seja realizar o controle manual do processo. Para resolver isso é que o HELM foi criado.
Pense em chart com um pacote de versão que contem todos os arquivos .yaml que compoem aquela versão.
ex:


#-----------------------------------------------------------------------------------------------
## Kind
## link: https://kind.sigs.k8s.io/docs/user/quick-start/#installation
## Usado para criar cluter kubernets
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.16.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
# Cria aum cluter
kind create cluster
# cria com nome
kind create cluster --name uni-cluster
# cria cluster via arquivo <ver abaixo arquivo cluster king>
kind create cluster --config=config.yaml
# Listar os cluster
kind get clusters
# Delete lcluster
kind delete cluster -n <name>
#-----------------------------------------------------------------------------------------------
# Listando contextos possiveis
cat ~/.kube/config
kubcetl config get-cluster
# setar um contexto
kubectl cluster-info --context <contexto>
kubcetl config use-context <contexto>
# Setando o Kind como cluster padrão no kubctl
kubectl cluster-info --context kind-kind
kubcetl config use-context kind-kind
# Setando o minikube como cluster padrão no kubctl
kubectl cluster-info --context minikube
# Setar namespace padrão
kubectl config set-context --current --namespace=<namespace>kind: Pod
apiVersion: v1
metadata:
name: foo
labels:
app: foo
spec:
containers:
- name: foo
image: hashicorp/http-echo:0.2.3
args:
- "-text=foo"
ports:
- containerPort: 5678
---
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
type: NodePort
ports:
- name: http
nodePort: 30950
port: 5678
selector:
app: fookind create cluster --config=config.yamlIstio é um service mesh, que nada mais que é uma camada adicionada junto as aplicações deployadas no kubernetes que permite gerenciar a comunicação dos serviços num sistema distribuído.
Um service mesh gerencia toda a comunicação serviço a serviço em um sistema de software distribuído (potencialmente baseado em microservices). Isso é feito normalmente por meio do uso de proxies “laterais (sidecar)” que são implantados ao lado de cada serviço através do qual todo o tráfego é roteado de forma transparente;
Com o Istio podemos resolver os problemas:
Existem outros services mesh, Linkerd, Istio, Consul, Kuma e Maesh.
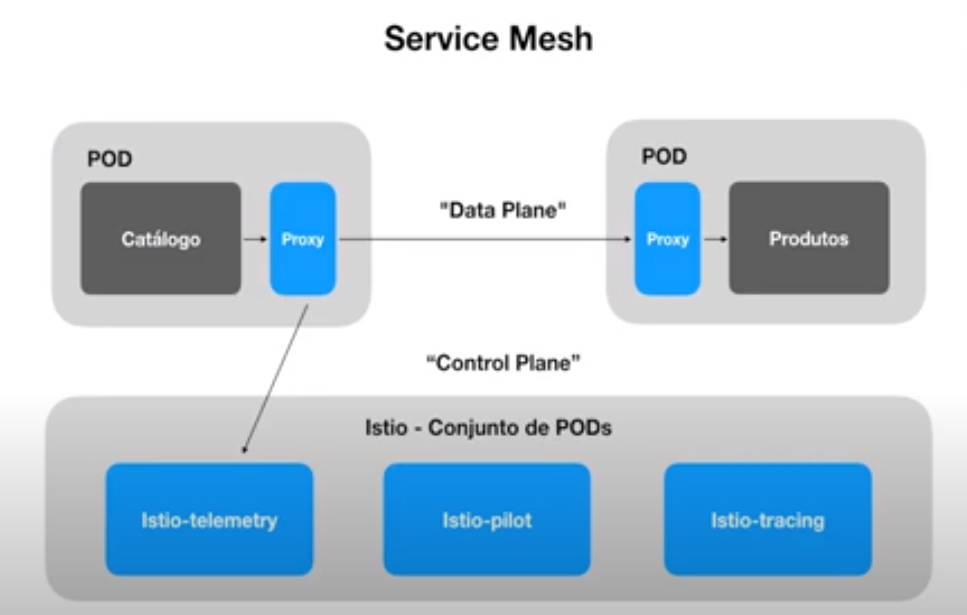
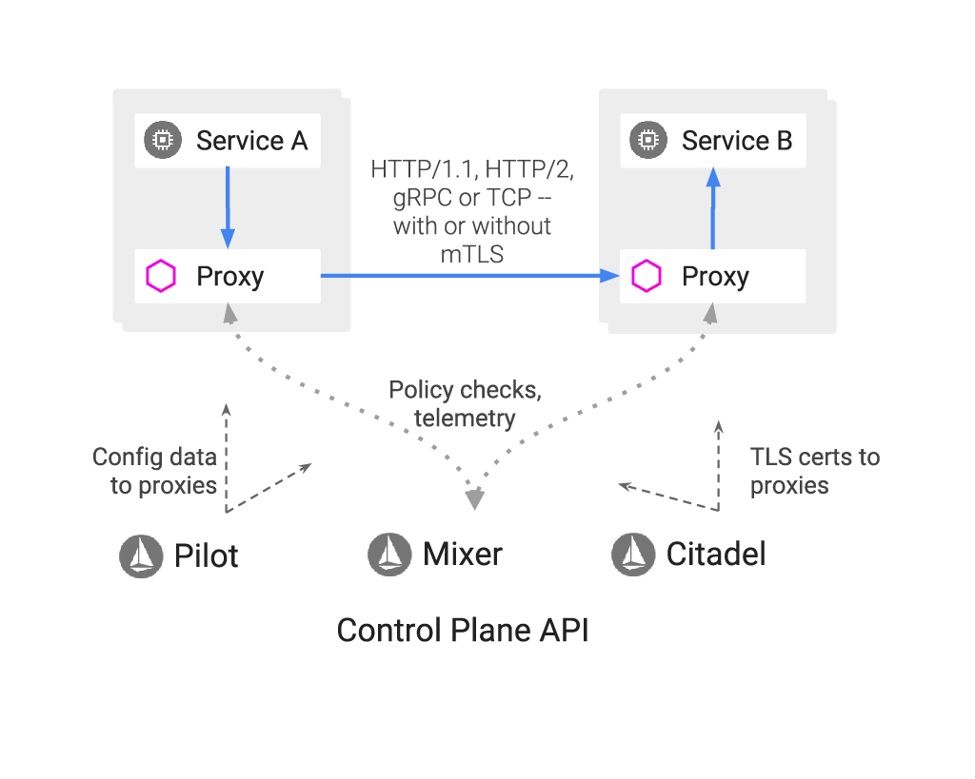
link: instale o istio
# Instalar istio no kunbernetes - veja outros profiles: https://istio.io/latest/docs/setup/additional-setup/config-profiles/
istioctl install --set profile=demo -y
# comandos uteis
# lista os namespaces
kubectl get namespaces
# lista os pods de um namespace
kubectl get pods -n istio-system
kgp -n istio-system
# lista os services de um namespace
kubectl get svc -n istio-system
kgs -n istio-system
# instalar addons
kubectl apply -f <istio-istall-folder>/samples/addons
kubectl apply -f ~/Documents/programs/istio-1.14.3/samples/addons
# Acessar dash kiali
istioctl dashboard kiali
# abre serviços
misinikube service <nome do serviço>
# configurar uma porta local pra usar no localhost
kubectl port-forward svc/<nome-serviço> -n <namespace-serviço> <porta-local>:<porta-serviço>Após fazer isso automaticamente o istio vai subir no pod um container de proxy.
# use para listar as lables de um namespace
kubectl get ns <namespace> --show-labels=true
kubectl get ns ucontas-app --show-labels=true
# Use para ativar o istion no namespace
kubectl label namespace <nome-namespace> istio-injection=enabled
kubectl label namespace ucontas-app istio-injection=enabled
# E reciso reiniciar os pod para que seja adicionados os sidecar
kubectl delete pods --all -n <namespace>
kubectl delete pods --all -n ucontas-appLink: https://www.infoq.com/br/articles/service-mesh-ultimate-guide/
Aplicação de continuos deploy, usada para realizar o deploy de aplicações no kubernetes.
Estamos acostumado com o formato padrão de pipeline do jenkins onde temos um fluxo único para o CI e CD. No caso do argoCD temos uma pipeline especifica para cada itens, sendo uma especifica para o processo de Continuos Delivery que é usada pelo argo.
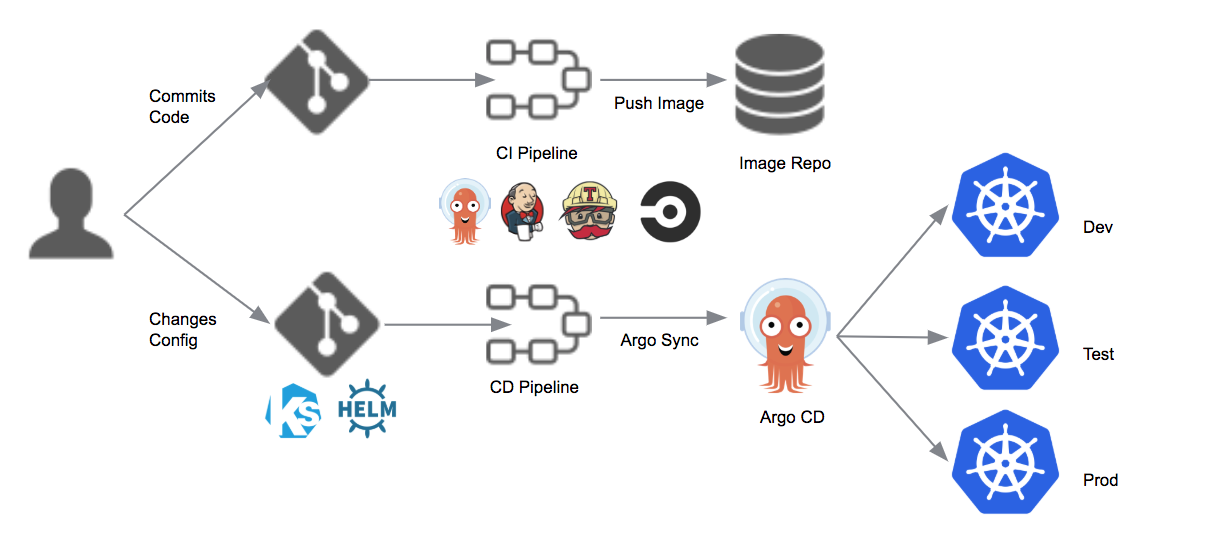
Diferentemente de outras ferramentas de Continuos delivery o ArgoCD tem uma particularidade que é o fato dele ser implantado no cluster do kubernetes. Na verdade ele é uma extensão do kubernetes, pois usa a maioria da ferramentas dele.
- Isso tem diversas vantagens tais como:
- Visibilidade do processo, coisa que o Jenkins não tem por ser um processo externo.
- Tem um interface gráfica que mostra o processo em tempo real.
Neste informamos qual:
- vai ser no repo onde vão estar os deployments.
- vai ser o cluster kubernets, onde serão aplicados os deployments.
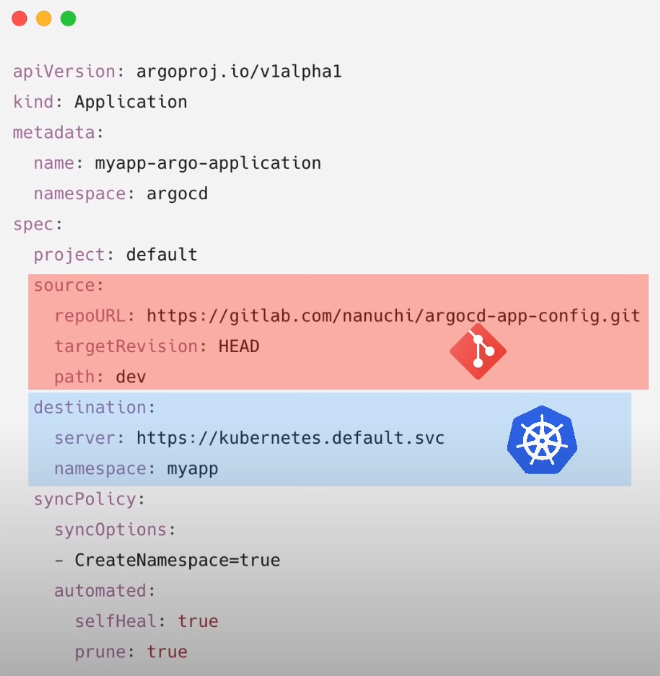
# cria o namespace do argo
kubectl create namespace <namespace>
kubectl create namespace argocd
# Para instalar o argo no namespace
kubectl apply -n <namespace> -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# Para remover argo
kubectl delete -n <namespace> -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
kubectl delete -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
## Acessando externamente
# 1 - Para acessar mude o serviço do argo-serve com o comando abaixo
kubectl patch svc argocd-server -n <namespace> -p '{"spec": {"type": "LoadBalancer"}}'
kubectl patch svc argocd-server -n argocd -p '{"spec": {"type": "LoadBalancer"}}'
# 1.1 - depois de o comando para abrir o serviço
minikube service argocd-server -n <namespace>
minikube service argocd-server -n argocd
# 1.3 Ou use o comando abaixo para liberar a porta
kubectl port-forward svc/argocd-server -n <namespace> 8080:443
kubectl port-forward svc/argocd-server -n argocd 8080:443
## Login Via UI
# Usuario padrão é admin
# Para pegar a senha use
kubectl -n <namespace> get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
## Login via CLI
# instale o cli - https://argo-cd.readthedocs.io/en/stable/cli_installation/
# Usuario padrão é admin
# Para pegar a senha use
kubectl -n <namespace> get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d; echo
# Use o comando abaixo - ARGOCD_SERVER é o ip e porta exporto externamente
argocd login <ARGOCD_SERVER>
argocd login 192.168.49.2:30634
# Para altera a senha #Nova senha - unisenha
argocd account update-password
# -------------------Register A Cluster To Deploy Apps To
# Listando os contextos validos
kubectl config get-contexts -o name
# Configurando um contexto para deploy
argocd cluster add <contexto>
argocd cluster add minikubeUser: admin
Senha: unisenha
- Trabalha com metricas e alertas para monitorar sistemas.
- Toolkit de monitoramento e alerta de sistema open source.
- Criado pela SoundCloud, Agora faz parte da Cloud Native Computer Foundation.
- Captura e armazenamena dados em formatos dimensionais.
- Tem coletas poderosas com o PromQL.
- Usado em conjunto com o Grafana.
- Tem diversas soluções para integrações.
há duas forma de funcionamento:
Sistema baseado em Pull.
Sistema baseado em Push.
Exports

Na arquitetura do Prometheus temos:

Acesse a pasta treinando
De os comando abaixo para subir o prometheus.
# Para subir os container
docker-compose up -d
# Para ver os logs do prometheus
docker-compose logs -f prometheus
# Para ver os logs do node export
docker-compose logs -f node-exportercontinuar -> https://prometheus.io/docs/concepts/metric_types/